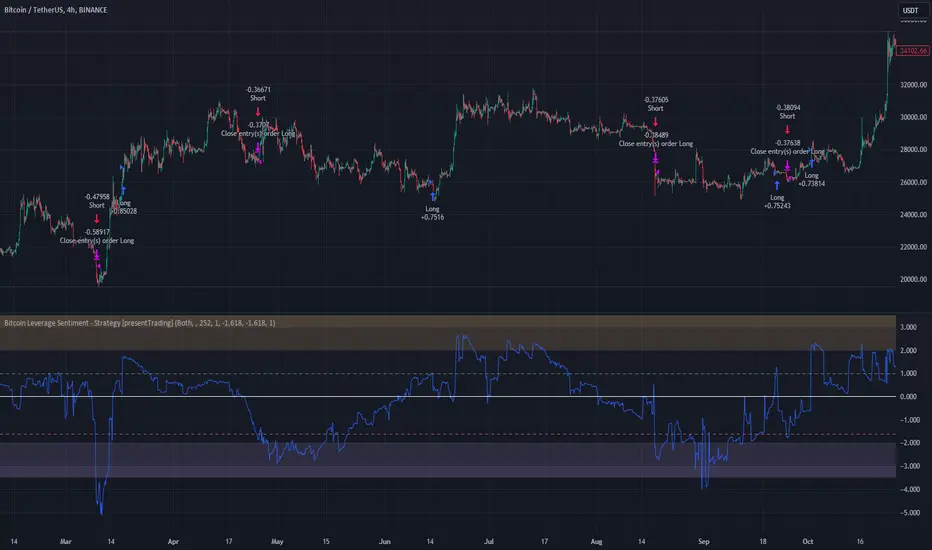
Bitcoin Leverage Sentiment - Strategy [presentTrading]█ Introduction and How it is Different
The "Bitcoin Leverage Sentiment - Strategy " represents a novel approach in the realm of cryptocurrency trading by focusing on sentiment analysis through leveraged positions in Bitcoin. Unlike traditional strategies that primarily rely on price action or technical indicators, this strategy leverages the power of Z-Score analysis to gauge market sentiment by examining the ratio of leveraged long to short positions. By assessing how far the current sentiment deviates from the historical norm, it provides a unique lens to spot potential reversals or continuation in market trends, making it an innovative tool for traders who wish to incorporate market psychology into their trading arsenal.
BTC 4h L/S Performance
local
█ Strategy, How It Works: Detailed Explanation
🔶 Data Collection and Ratio Calculation
Firstly, the strategy acquires data on leveraged long (**`priceLongs`**) and short positions (**`priceShorts`**) for Bitcoin. The primary metric of interest is the ratio of long positions relative to the total of both long and short positions:
BTC Ratio=priceLongs / (priceLongs+priceShorts)
This ratio reflects the prevailing market sentiment, where values closer to 1 indicate a bullish sentiment (dominance of long positions), and values closer to 0 suggest bearish sentiment (prevalence of short positions).
🔶 Z-Score Calculation
The Z-Score is then calculated to standardize the BTC Ratio, allowing for comparison across different time periods. The Z-Score formula is:
Z = (X - μ) / σ
Where:
- X is the current BTC Ratio.
- μ is the mean of the BTC Ratio over a specified period (**`zScoreCalculationPeriod`**).
- σ is the standard deviation of the BTC Ratio over the same period.
The Z-Score helps quantify how far the current sentiment deviates from the historical norm, with high positive values indicating extreme bullish sentiment and high negative values signaling extreme bearish sentiment.
🔶 Signal Generation: Trading signals are derived from the Z-Score as follows:
Long Entry Signal: Occurs when the BTC Ratio Z-Score crosses above the thresholdLongEntry, suggesting bullish sentiment.
- Condition for Long Entry = BTC Ratio Z-Score > thresholdLongEntry
Long Exit/Short Entry Signal: Triggered when the BTC Ratio Z-Score drops below thresholdLongExit for exiting longs or below thresholdShortEntry for entering shorts, indicating a shift to bearish sentiment.
- Condition for Long Exit/Short Entry = BTC Ratio Z-Score < thresholdLongExit or BTC Ratio Z-Score < thresholdShortEntry
Short Exit Signal: Happens when the BTC Ratio Z-Score exceeds the thresholdShortExit, hinting at reducing bearish sentiment and a potential switch to bullish conditions.
- Condition for Short Exit = BTC Ratio Z-Score > thresholdShortExit
🔶Implementation and Visualization: The strategy applies these conditions for trade management, aligning with the selected trade direction. It visualizes the BTC Ratio Z-Score with horizontal lines at entry and exit thresholds, illustrating the current sentiment against historical norms.
█ Trade Direction
The strategy offers flexibility in trade direction, allowing users to choose between long, short, or both, depending on their market outlook and risk tolerance. This adaptability ensures that traders can align the strategy with their individual trading style and market conditions.
█ Usage
To employ this strategy effectively:
1. Customization: Begin by setting the trade direction and adjusting the Z-Score calculation period and entry/exit thresholds to match your trading preferences.
2. Observation: Monitor the Z-Score and its moving average for potential trading signals. Look for crossover events relative to the predefined thresholds to identify entry and exit points.
3. Confirmation: Consider using additional analysis or indicators for signal confirmation, ensuring a comprehensive approach to decision-making.
█ Default Settings
- Trade Direction: Determines if the strategy engages in long, short, or both types of trades, impacting its adaptability to market conditions.
- Timeframe Input: Influences signal frequency and sensitivity, affecting the strategy's responsiveness to market dynamics.
- Z-Score Calculation Period: Affects the strategy’s sensitivity to market changes, with longer periods smoothing data and shorter periods increasing responsiveness.
- Entry and Exit Thresholds: Set the Z-Score levels for initiating or exiting trades, balancing between capturing opportunities and minimizing false signals.
- Impact of Default Settings: Provides a balanced approach to leverage sentiment trading, with adjustments needed to optimize performance across various market conditions.
Forecast
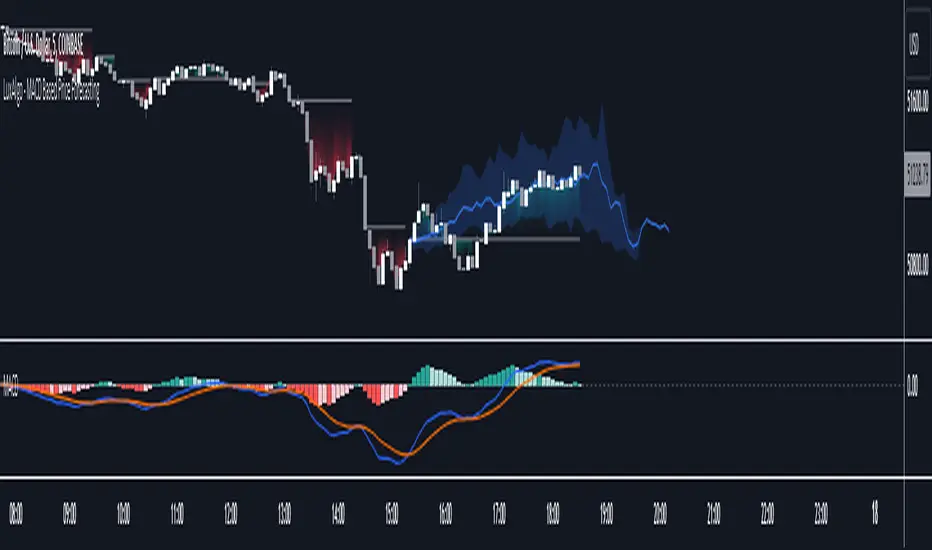
MACD Based Price Forecasting [LuxAlgo]The MACD Based Price Forecasting tool is an innovative price forecasting method based on signals generated by the MACD indicator.
The forecast includes an area which can help traders determine the area where price can develop after a MACD signal.
🔶 USAGE
The forecast returned by the tool allows users to obtain a general picture of how price tends to progress after a specific MACD signal. The forecast is constructed based on percentiles of previous price progressions done after a specific MACD signal is generated.
Users can change which condition is used to generate MACD signals from the "Trend Determination" dropdown menu, with "MACD" determining trends based on whether the MACD is positive (uptrend) or negative (downtrend) and "MACD-Signal" determining trends based on the position of the MACD relative to its signal line, with an MACD above the signal line indicating an uptrend, else a downtrend.
Users can introduce bias to the forecast by changing the "Average Percentage" setting, with values above 50% introducing bullish bias, and below bearish bias.
It can be possible for the forecast to highlight potential reversals depending on the selected forecasting horizon as long as reversals can be observed on trends detected by the MACD.
🔹 Forecasting Area
The forecasting area can help visualize the area that will likely contain price after a specific signal. The area width is based on the "Top/Bottom Percentiles" settings, with a higher "Top Percentile" value returning a higher top bound and a lower "Bottom Percentile" value returning a lower bottom bound.
These areas can also serve as potential support/resistance areas.
🔶 SETTINGS
Fast Length: Fast length of the moving average used to compute the MACD
Slow Length: Slow length of the moving average used to compute the MACD
Signal Length: Length of the MACD moving average.
Trend Determination: Method used to determine a trend direction from the MACD.
🔹 Forecast
Maximum Memory: Determines the maximum amount of prices recorded at each steps succeeding a signal. Lower values will return forecasts with a higher degree of variability.
Forecasting Length: Forecasting horizon in bars, this value only serves as a limit of the forecasting horizon and might not be reached depending on user selected MACD settings.
Top Percentile: Percentile value used to determine the upper bound of the forecasting area.
Average Percentile: Percentile value used to determine the forecast.
Lower Percentile: Percentile value used to determine the lower bound of the forecasting area.
Session breakThis indicator will show future lines before each session start. It will only show London session and US session start.
You can change the color of the lines and time as per day light savings.

AI SuperTrend x Pivot Percentile - Strategy [PresentTrading]█ Introduction and How it is Different
The AI SuperTrend x Pivot Percentile strategy is a sophisticated trading approach that integrates AI-driven analysis with traditional technical indicators. Combining the AI SuperTrend with the Pivot Percentile strategy highlights several key advantages:
1. Enhanced Accuracy in Trend Prediction: The AI SuperTrend utilizes K-Nearest Neighbors (KNN) algorithm for trend prediction, improving accuracy by considering historical data patterns. This is complemented by the Pivot Percentile analysis which provides additional context on trend strength.
2. Comprehensive Market Analysis: The integration offers a multi-faceted approach to market analysis, combining AI insights with traditional technical indicators. This dual approach captures a broader range of market dynamics.
BTC 6H L/S Performance
Local
█ Strategy: How it Works - Detailed Explanation
🔶 AI-Enhanced SuperTrend Indicators
1. SuperTrend Calculation:
- The SuperTrend indicator is calculated using a moving average and the Average True Range (ATR). The basic formula is:
- Upper Band = Moving Average + (Multiplier × ATR)
- Lower Band = Moving Average - (Multiplier × ATR)
- The moving average type (SMA, EMA, WMA, RMA, VWMA) and the length of the moving average and ATR are adjustable parameters.
- The direction of the trend is determined based on the position of the closing price in relation to these bands.
2. AI Integration with K-Nearest Neighbors (KNN):
- The KNN algorithm is applied to predict trend direction. It uses historical price data and SuperTrend values to classify the current trend as bullish or bearish.
- The algorithm calculates the 'distance' between the current data point and historical points. The 'k' nearest data points (neighbors) are identified based on this distance.
- A weighted average of these neighbors' trends (bullish or bearish) is calculated to predict the current trend.
For more please check: Multi-TF AI SuperTrend with ADX - Strategy
🔶 Pivot Percentile Analysis
1. Percentile Calculation:
- This involves calculating the percentile ranks for high and low prices over a set of predefined lengths.
- The percentile function is typically defined as:
- Percentile = Value at (P/100) × (N + 1)th position
- Where P is the desired percentile, and N is the number of data points.
2. Trend Strength Evaluation:
- The calculated percentiles for highs and lows are used to determine the strength of bullish and bearish trends.
- For instance, a high percentile rank in the high prices may indicate a strong bullish trend, and vice versa for bearish trends.
For more please check: Pivot Percentile Trend - Strategy
🔶 Strategy Integration
1. Combining SuperTrend and Pivot Percentile:
- The strategy synthesizes the insights from both AI-enhanced SuperTrend and Pivot Percentile analysis.
- It compares the trend direction indicated by the SuperTrend with the strength of the trend as suggested by the Pivot Percentile analysis.
2. Signal Generation:
- A trading signal is generated when both the AI-enhanced SuperTrend and the Pivot Percentile analysis agree on the trend direction.
- For instance, a bullish signal is generated when both the SuperTrend is bullish, and the Pivot Percentile analysis shows strength in bullish trends.
🔶 Risk Management and Filters
- ADX and DMI Filter: The strategy uses the Average Directional Index (ADX) and the Directional Movement Index (DMI) as filters to assess the trend's strength and direction.
- Dynamic Trailing Stop Loss: Based on the SuperTrend indicator, the strategy dynamically adjusts stop-loss levels to manage risk effectively.
This strategy stands out for its ability to combine real-time AI analysis with established technical indicators, offering traders a nuanced and responsive tool for navigating complex market conditions. The equations and algorithms involved are pivotal in accurately identifying market trends and potential trade opportunities.
█ Usage
To effectively use this strategy, traders should:
1. Understand the AI and Pivot Percentile Indicators: A clear grasp of how these indicators work will enable traders to make informed decisions.
2. Interpret the Signals Accurately: The strategy provides bullish, bearish, and neutral signals. Traders should align these signals with their market analysis and trading goals.
3. Monitor Market Conditions: Given that this strategy is sensitive to market dynamics, continuous monitoring is crucial for timely decision-making.
4. Adjust Settings as Needed: Traders should feel free to tweak the input parameters to suit their trading preferences and to respond to changing market conditions.
█Default Settings and Their Impact on Performance
1. Trading Direction (Default: "Both")
Effect: Determines whether the strategy will take long positions, short positions, or both. Adjusting this setting can align the strategy with the trader's market outlook or risk preference.
2. AI Settings (Neighbors: 3, Data Points: 24)
Neighbors: The number of nearest neighbors in the KNN algorithm. A higher number might smooth out noise but could miss subtle, recent changes. A lower number makes the model more sensitive to recent data but may increase noise.
Data Points: Defines the amount of historical data considered. More data points provide a broader context but may dilute recent trends' impact.
3. SuperTrend Settings (Length: 10, Factor: 3.0, MA Source: "WMA")
Length: Affects the sensitivity of the SuperTrend indicator. A longer length results in a smoother, less sensitive indicator, ideal for long-term trends.
Factor: Determines the bandwidth of the SuperTrend. A higher factor creates wider bands, capturing larger price movements but potentially missing short-term signals.
MA Source: The type of moving average used (e.g., WMA - Weighted Moving Average). Different MA types can affect the trend indicator's responsiveness and smoothness.
4. AI Trend Prediction Settings (Price Trend: 10, Prediction Trend: 80)
Price Trend and Prediction Trend Lengths: These settings define the lengths of weighted moving averages for price and SuperTrend, impacting the responsiveness and smoothness of the AI's trend predictions.
5. Pivot Percentile Settings (Length: 10)
Length: Influences the calculation of pivot percentiles. A shorter length makes the percentile more responsive to recent price changes, while a longer length offers a broader view of price trends.
6. ADX and DMI Settings (ADX Length: 14, Time Frame: 'D')
ADX Length: Defines the period for the Average Directional Index calculation. A longer period results in a smoother ADX line.
Time Frame: Sets the time frame for the ADX and DMI calculations, affecting the sensitivity to market changes.
7. Commission, Slippage, and Initial Capital
These settings relate to transaction costs and initial investment, directly impacting net profitability and strategy feasibility.

ATH Gain PotentialThe indicator quantifies the relative position of a symbol's current closing price in relation to its historical all-time high (ATH).
By evaluating the ratio between the ATH and the present closing price, it provides an analytical framework to estimate the potential gains that could accrue if the symbol were to revert to its ATH from a specified reference point. The ratio serves as a quantitative measure for assessing the distance between the current market value and the symbol's historical peak, enabling investors to gauge the prospective profitability of a return to the ATH.

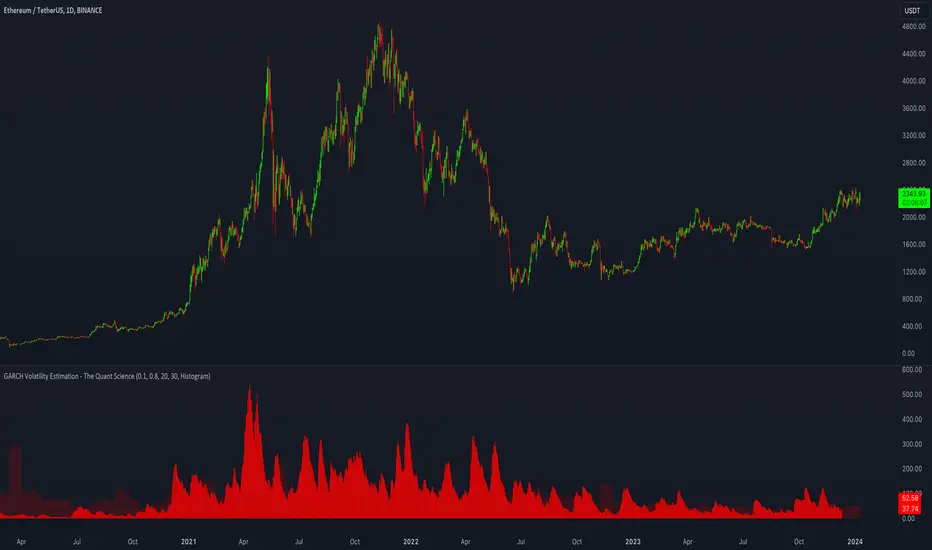
GARCH Volatility Estimation - The Quant ScienceThe GARCH (Generalized Autoregressive Conditional Heteroskedasticity) model is a statistical model used to forecast the volatility of a financial asset. This model takes into account the fluctuations in volatility over time, recognizing that volatility can vary in a heteroskedastic (i.e., non-constant variance) manner and can be influenced by past events.
The general formula of the GARCH model is:
σ²(t) = ω + α * ε²(t-1) + β * σ²(t-1)
where:
σ²(t) is the conditional variance at time t (i.e., squared volatility)
ω is the constant term (intercept) representing the baseline level of volatility
α is the coefficient representing the impact of the squared lagged error term on the conditional variance
ε²(t-1) is the squared lagged error term at the previous time period
β is the coefficient representing the impact of the lagged conditional variance on the current conditional variance
In the context of financial forecasting, the GARCH model is used to estimate the future volatility of the asset.
HOW TO USE
This quantitative indicator is capable of estimating the probable future movements of volatility. When the GARCH increases in value, it means that the volatility of the asset will likely increase as well, and vice versa. The indicator displays the relationship of the GARCH (bright red) with the trend of historical volatility (dark red).
USER INTERFACE
Alpha: select the starting value of Alpha (default value is 0.10).
Beta: select the starting value of Beta (default value is 0.80).
Lenght: select the period for calculating values within the model such as EMA (Exponential Moving Average) and Historical Volatility (default set to 20).
Forecasting: select the forecasting period, the number of bars you want to visualize data ahead (default set to 30).
Design: customize the indicator with your preferred color and choose from different types of charts, managing the design settings.
Forecast: PastFluxDelta PredictionThe theory is that time periods and the conditions during these periods repeat themselves. Especially if it is the same day of the week in the past, there is a high probability that price fluctuations will roughly repeat themselves.
Eternal return (or eternal recurrence) is a philosophical concept which states that time repeats itself in an infinite loop, and that exactly the same events will continue to occur in exactly the same way, over and over again, for eternity.
History does repeat itself.
The stock market is a manifest example.
Chief market strategist at Miller Tabak + Co. Matt Maley pointed out the strong resemblance between the stock market recently and that in the past.
Various scientific studies and articles show that there could be something to this theory
Most of the investors are ignoring the parallels between stocks today and "heady" years 1929, 1999 and 2007…
Post Labor Day sees investors returning to the S&P 500 near all-time highs and some dark economic shadows lurking …
So how should we regard these inescapable results?
Nietzsche said we should embrace them, accept them, and love them. Once they stop, expect them to start again.
But remember that the future is fundamentally uncertain and that past results are by no means a guarantee of future performance.
Based on this, this indicator uses historical trading data from a year, a week or a day ago and compares price fluctuations in the past with current conditions.
"Bars to predict" can be used to indicate how far into the future the indicator is looking.
"Amount of bars to show" determines how many bars are generally displayed. A high value allows you to see how accurate the method was in the past.

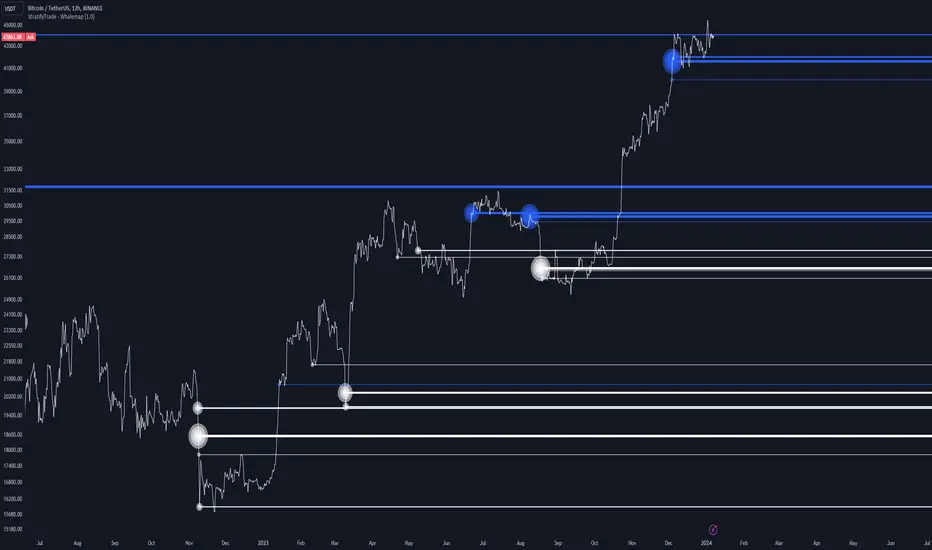
Whalemap [BigBeluga]The Whalemap indicator aims to spot big buying and selling activity represented as big orders for a possible bottom or top formation on the chart.
🔶 CALCULATION
The indicator uses volume to spot big volume activity represented as big orders in the market.
for i = 0 to len - 1
blV.vol += (close > close ? volume : 0)
brV.vol += (close < close ? volume : 0)
When volume exceeds its own threshold, it is a sign that volume is exceeding its normal value and is considered as a "Whale order" or "Whale activity," which is then plotted on the chart as circles.
🔶 DETAILS
The indicator plots Bubbles on the chart with different sizes indicating the buying or selling activity. The bigger the circle, the more impact it will have on the market.
On each circle is also plotted a line, and its own weight is also determined by the strength of its own circle; the bigger the circle, the bigger the line.
Old buying/selling activity can also be used for future support and resistance to spot interesting areas.
The more price enters old buying/selling activity and starts producing orders of the same direction, it might be an interesting point to take a closer look.
🔶 EXAMPLES
The chart above is showing us price reacting to big orders, finding good bottoms in price and good tops in confluence with old activity.
🔶 SETTINGS
Users will have the options to:
Filter options to adjust buying and selling sensitivity.
Display/Hide Lines
Display/Hide Bubbles
Choose which orders to display (from smallest to biggest)
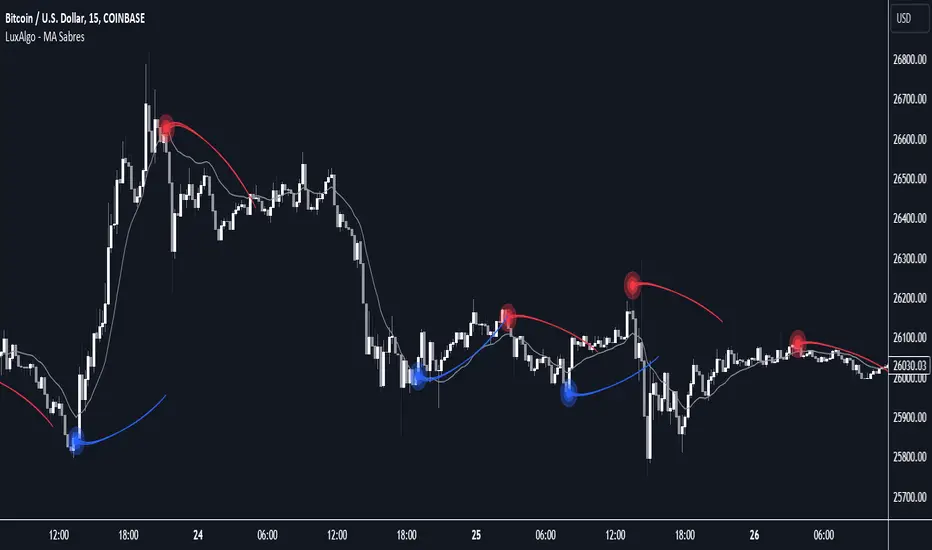
MA Sabres [LuxAlgo]The "MA Sabres" indicator highlights potential trend reversals based on a moving average direction. Detected reversals are accompanied by an extrapolated "Sabre" looking shape that can be used as support/resistance and as a source of breakouts.
🔶 USAGE
If a selected moving average (MA) continues in the same direction for a certain time, a change in that direction could signify a potential reversal.
In this publication, when a trend change occurs, a sabre-shaped figure is drawn which can be used as support/resistance:
A sabre can be indicative of a direction, however, it can also act as a stop-loss when the price should go in the opposite direction:
Or show potential areas of interest:
🔶 DETAILS
This publication will look for a change in direction after the MA went in the same direction during x consecutive bars (settings: " Reversal after x bars in the same direction ").
Then a circle-shaped drawing will be drawn 1 bar back, at the previous high/low, dependable of the previous direction.
From there originates a sabre-shaped figure where the tip lies as far as the user-set MA length.
The angle of the "sabre" relies on the ATR of the previous 14 bars.
Less volatility will create a flatter sabre while the opposite is true when there is more volatility in the previous 14 bars.
The sabre is created by the latest feature, polylines , which enables us to connect several 'points', resulting in a polyline.new() object.
Do note that sabres are offset by one bar to the past to align their locations.
🔶 SETTINGS
MA Type: SMA, EMA, SMMA (RMA), HullMA, WMA, VWMA, DEMA, TEMA, NONE (off)
Length: this sets the length of MA, and the length of the sabre shape
Previous Trend Duration: After the MA direction is the same for x consecutive bars, the first time the direction changes, a sabre is drawn
Machine Learning: Gaussian Process Regression [LuxAlgo]We provide an implementation of the Gaussian Process Regression (GPR), a popular machine-learning method capable of estimating underlying trends in prices as well as forecasting them.
While this implementation is adapted to real-time usage, do remember that forecasting trends in the market is challenging, do not use this tool as a standalone for your trading decisions.
🔶 USAGE
The main goal of our implementation of GPR is to forecast trends. The method is applied to a subset of the most recent prices, with the Training Window determining the size of this subset.
Two user settings controlling the trend estimate are available, Smooth and Sigma . Smooth determines the smoothness of our estimate, with higher values returning smoother results suitable for longer-term trend estimates.
Sigma controls the amplitude of the forecast, with values closer to 0 returning results with a higher amplitude. Do note that due to the calculation of the method, lower values of sigma can return errors with higher values of the training window.
🔹 Updating Mechanisms
The script includes three methods to update a forecast. By default a forecast will not update for new bars (Lock Forecast).
The forecast can be re-estimated once the price reaches the end of the forecasting window when using the "Update Once Reached" method.
Finally "Continuously Update" will update the whole forecast on any new bar.
🔹 Estimating Trends
Gaussian Process Regression can be used to estimate past underlying local trends in the price, allowing for a noise-free interpretation of trends.
This can be useful for performing descriptive analysis, such as highlighting patterns more easily.
🔶 SETTINGS
Training Window: Number of most recent price observations used to fit the model
Forecasting Length: Forecasting horizon, determines how many bars in the future are forecasted.
Smooth: Controls the degree of smoothness of the model fit.
Sigma: Noise variance. Controls the amplitude of the forecast, lower values will make it more sensitive to outliers.
Update: Determines when the forecast is updated, by default the forecast is not updated for new bars.

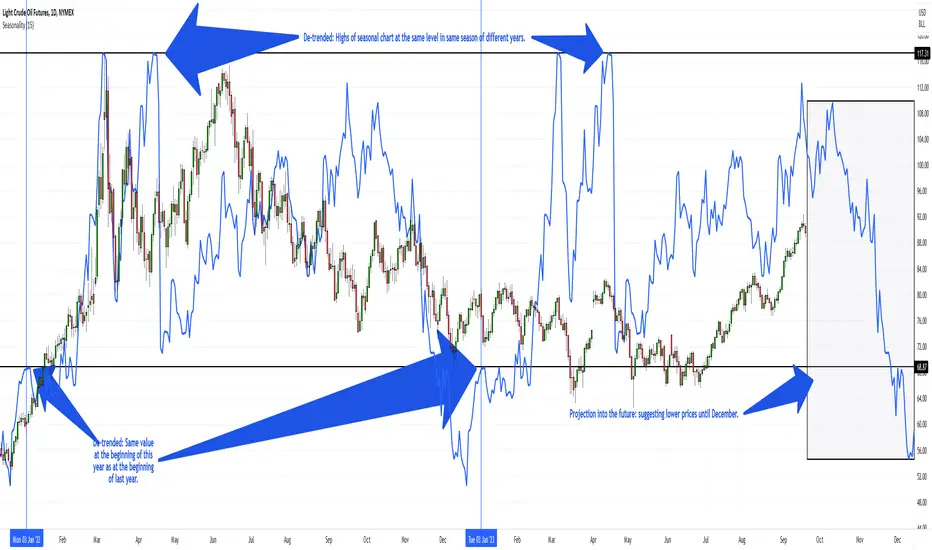
Kaschko's Seasonal TrendThis script calculates the average price moves (using each bar's close minus the previous bar's close) for the trading days, weeks or months (depending on the timeframe it is applied to) of a number of past calendar years (up to 30) to construct a seasonal trend which is then drawn as a seasonal chart (overlay) onto the price chart. Supported are the 1D,1W,1M timeframes.
The seasonal chart is adjusted to the price chart (so that both occupy the same height on the overall chart) and it is also de-trended, which means that the seasonal chart's starting value is the same in each year and the progression during the year is adjusted so that no abrupt gap occurs between years and the highs and lows of consecutive years of the seasonal chart (if projected over more than one year) are also at the same level. Of course, this also means that the absolute value of the seasonal chart has no meaning at all.
You can configure the number of bars the seasonal chart is drawn into the future. This projection shows how price could move in the future if the market shows the same seasonal tendencies like in the past. On the daily chart, the trading week of year (TWOY), trading day of month (TDOM) and trading day of year (TDOY) are shown in the status line.
Caution is advised as seasonality is based on the past. It is not a reliable prediction of the future. But it can still be used as an additional confirmation or contradiction of an otherwise recognized possible impending trend.
I have used a virtually identical indicator for a long time in a commercial software package popular among futures traders, but have not found anything comparable here. Therefore I implemented it myself. I hope you find it useful.
Machine Learning Regression Trend [LuxAlgo]The Machine Learning Regression Trend tool uses random sample consensus (RANSAC) to fit and extrapolate a linear model by discarding potential outliers, resulting in a more robust fit.
🔶 USAGE
The proposed tool can be used like a regular linear regression, providing support/resistance as well as forecasting an estimated underlying trend.
Using RANSAC allows filtering out outliers from the input data of our final fit, by outliers we are referring to values deviating from the underlying trend whose influence on a fitted model is undesired. For financial prices and under the assumptions of segmented linear trends, these outliers can be caused by volatile moves and/or periodic variations within an underlying trend.
Adjusting the "Allowed Error" numerical setting will determine how sensitive the model is to outliers, with higher values returning a more sensitive model. The blue margin displayed shows the allowed error area.
The number of outliers in the calculation window (represented by red dots) can also be indicative of the amount of noise added to an underlying linear trend in the price, with more outliers suggesting more noise.
Compared to a regular linear regression which does not discriminate against any point in the calculation window, we see that the model using RANSAC is more conservative, giving more importance to detecting a higher number of inliners.
🔶 DETAILS
RANSAC is a general approach to fitting more robust models in the presence of outliers in a dataset and as such does not limit itself to a linear regression model.
This iterative approach can be summarized as follow for the case of our script:
Step 1: Obtain a subset of our dataset by randomly selecting 2 unique samples
Step 2: Fit a linear regression to our subset
Step 3: Get the error between the value within our dataset and the fitted model at time t , if the absolute error is lower than our tolerance threshold then that value is an inlier
Step 4: If the amount of detected inliers is greater than a user-set amount save the model
Repeat steps 1 to 4 until the set number of iterations is reached and use the model that maximizes the number of inliers
🔶 SETTINGS
Length: Calculation window of the linear regression.
Width: Linear regression channel width.
Source: Input data for the linear regression calculation.
🔹 RANSAC
Minimum Inliers: Minimum number of inliers required to return an appropriate model.
Allowed Error: Determine the tolerance threshold used to detect potential inliers. "Auto" will automatically determine the tolerance threshold and will allow the user to multiply it through the numerical input setting at the side. "Fixed" will use the user-set value as the tolerance threshold.
Maximum Iterations Steps: Maximum number of allowed iterations.

Autocorrelation - The Quant ScienceAutocorrelation - The Quant Science it is an indicator developed to quickly calculate the autocorrelation of a historical series. The objective of this indicator is to plot the autocorrelation values and highlight market moments where the value is positive and exceeds the attention threshold.
This indicator can be used for manual analysis when a trader needs to search for new price patterns within the historical series or to create complex formulas in estimating future prices.
What is autocorrelation?
Autocorrelation in trading is a statistical measure used to determine the presence of a relationship or pattern of dependence between values in a financial time series over time. It represents the correlation of past values in a series with its future values. In other words, autocorrelation in trading aims to identify if there are systematic relationships between the past prices or returns of a security or market and its future prices or returns. This analysis can be helpful in identifying patterns or trends that can be leveraged for informed trading decisions. The presence of autocorrelation may suggest that market prices or returns follow a certain pattern or trend over time.
Limitations of the model
It is important to note that autocorrelation does not necessarily imply a causal relationship between past and future values. Other variables or market factors may influence the dynamics of prices or returns, and therefore autocorrelation could be merely a random coincidence. Therefore, it is essential to carefully evaluate the results of autocorrelation analysis along with other information and trading strategies to make informed decisions.
How to use
The usage is very simple, you just need to add it to the current chart to activate the indicator.
From the user interface, you can manage two important features:
1. Lenght: the delay period applied to the historical series during the autocorrelation calculation can be managed from the user interface. By default, it is set to 20, which means that the autocorrelation ratio within the historical series is calculated with a delay of 20 bars.
2. Threshold: the threshold value that the autocorrelation level must meet can be managed from the user interface. By default, it is set to 0.50, which means that the autocorrelation value must be higher than this threshold to be considered valid and displayed on the chart.
3. Bar color: the color used to display the autocorrelation data and highlight the bars when autocorrelation is valid can be managed from the user interface.
To set up the chart
We recommend disabling the 'wick' and 'border' of the candlesticks from the chart settings for a high-quality user experience.

Inverted ProjectionThe "Inverted Projection" indicator calculates the Simple Moving Average (SMA) and draws lines representing an inverted projection. The indicator swaps the highs and lows of the projection to provide a unique perspective on price movement.
This indicator is a simple study that should not be taken seriously as a tool for predicting future price movements; it is purely intended for exploratory purposes.

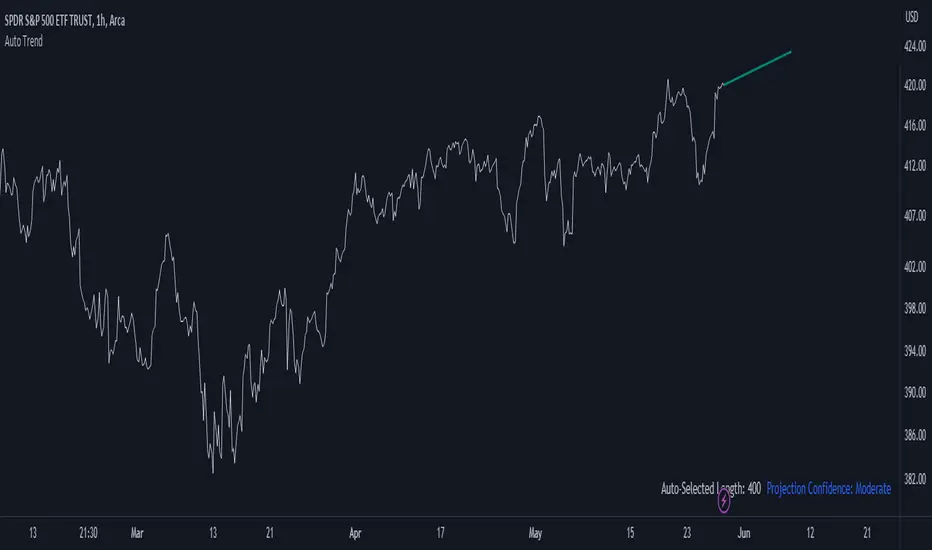
Auto Trend ProjectionAuto Trend Projection is an indicator designed to automatically project the short-term trend based on historical price data. It utilizes a dynamic calculation method to determine the slope of the linear regression line, which represents the trend direction. The indicator takes into account multiple length inputs and calculates the deviation and Pearson's R values for each length.
Using the highest Pearson's R value, Auto Trend Projection identifies the optimal length for the trend projection. This ensures that the projected trend aligns closely with the historical price data.
The indicator visually displays the projected trend using trendlines. These trendlines extend into the future, providing a visual representation of the potential price movement in the short term. The color and style of the trendlines can be customized according to user preferences.
Auto Trend Projection simplifies the process of trend analysis by automating the projection of short-term trends. Traders and investors can use this indicator to gain insights into potential price movements and make informed trading decisions.
Please note that Auto Trend Projection is not a standalone trading strategy but a tool to assist in trend analysis. It is recommended to combine it with other technical analysis tools and indicators for comprehensive market analysis.
Overall, Auto Trend Projection offers a convenient and automated approach to projecting short-term trends, empowering traders with valuable insights into the potential price direction.
Ultimate Trend LineThe "Ultimate Trend Line" indicator, designed for overlay on financial charts, calculates and plots a global trend line. It works by first allowing users to input several parameters such as different lengths for up to 21 groups, a multiplier that defines the deviation from the linear regression line for calculating the upper and lower bands, and a color for the fill.
Using these inputs, it calculates the upper and lower bands for each length group based on a multiple of the standard deviation from the linear regression line. It then averages these bands to define the global trend line, which is plotted on the graph.
Although the code includes commented-out lines for plotting each individual upper and lower band, the indicator as it stands only displays the overall average trend line. The line's color and linewidth can be adjusted according to user preferences.
This indicator can be effectively used on both logarithmic and linear scales. This versatility allows it to be adaptable to various types of financial charts and trading styles, providing a flexible tool for users to assess and visualize trend patterns across different market conditions and time frames. It maintains its accuracy and relevance, regardless of the scale used, thus making it a comprehensive solution for trend line analysis in diverse scenarios.
It's important to note that the "Ultimate Trend Line" indicator requires a substantial amount of historical data to function properly. If insufficient historical data is available, the indicator may not display accurately or at all. This issue is particularly prevalent when using larger time units, such as weekly or monthly charts, where the available data may not stretch back far enough to satisfy the requirements of the indicator. As such, users should ensure they are operating on a time scale and data set that provides adequate historical depth for the reliable operation of this indicator.

TrueLevel BandsTrueLevel Bands is a powerful trading indicator that employs linear regression and standard deviation to create dynamic, envelope-style bands around the price action of a financial instrument. These bands are designed to help traders identify potential support and resistance levels, trend direction, and volatility.
The TrueLevel Bands indicator consists of multiple envelope bands, each constructed using different timeframes or lengths, and a multiple (mult) factor. The multiple factor determines the width of the bands by adjusting the number of standard deviations from the linear regression line.
Key Features of TrueLevel Bands
1. Multi-Timeframe Analysis: Unlike traditional moving average-based indicators, TrueLevel Bands allow traders to incorporate multiple timeframes into their analysis. This helps traders capture both short-term and long-term market dynamics, offering a more comprehensive understanding of price behavior.
2. Customization: The TrueLevel Bands indicator offers a high level of customization, allowing traders to adjust the lengths and multiple factors to suit their trading style and preferences. This flexibility enables traders to fine-tune the indicator to work optimally with various instruments and market conditions.
3. Adaptive Volatility: By incorporating standard deviation, TrueLevel Bands can automatically adjust to changing market volatility. This feature enables the bands to expand during periods of high volatility and contract during periods of low volatility, providing traders with a more accurate representation of market dynamics.
4. Dynamic Support and Resistance Levels: TrueLevel Bands can help traders identify dynamic support and resistance levels, as the bands adjust in real-time according to price action. This can be particularly useful for traders looking to enter or exit positions based on support and resistance levels.
5. The "Global Trend Line" refers to the average of the bands used to indicate the overall trend.
Why TrueLevel Bands are Different from Classic Moving Averages
TrueLevel Bands differ from conventional moving averages in several ways:
1. Linear Regression: While moving averages are based on simple arithmetic means, TrueLevel Bands use linear regression to determine the centerline. This offers a more accurate representation of the trend and helps traders better assess potential entry and exit points.
2. Envelope Style Bands: Unlike moving averages, which are single lines, TrueLevel Bands form envelope-style bands around the price action. This provides traders with a visual representation of potential support and resistance levels, trend direction, and volatility.
3. Multi-Timeframe Analysis: Classic moving averages typically focus on a single timeframe. In contrast, TrueLevel Bands incorporate multiple timeframes, enabling traders to capture a broader understanding of market dynamics.
4. Adaptive Volatility: Traditional moving averages do not account for changing market volatility, whereas TrueLevel Bands automatically adjust to volatility shifts through the use of standard deviation.
The TrueLevel Bands indicator is a powerful, versatile tool that offers traders a unique approach to technical analysis. With its ability to adapt to changing market conditions, provide multi-timeframe analysis, and dynamic support and resistance levels, TrueLevel Bands can serve as an invaluable asset to both novice and experienced traders looking to gain an edge in the markets.

Price Action Color Forecast (Expo)█ Overview
The Price Action Color Forecast Indicator , is an innovative trading tool that uses the power of historical price action and candlestick patterns to predict potential future market movements. By analyzing the colors of the candlesticks and identifying specific price action events, this indicator provides traders with valuable insights into future market behavior based on past performance.
█ Calculations
The Price Action Color Forecast Indicator systematically analyzes historical price action events based on the colors of the candlesticks. Upon identifying a current price action coloring event, the indicator searches through its past data to find similar patterns that have happened before. By examining these past events and their outcomes, the indicator projects potential future price movements, offering traders valuable insights into how the market might react to the current price action event.
The indicator prioritizes the analysis of the most recent candlesticks before methodically progressing toward earlier data. This approach ensures that the generated candle forecast is based on the latest market dynamics.
The core functionality of the Price Action Color Forecast Indicator:
Analyzing historical price action events based on the colors of the candlesticks.
Identifying similar events from the past that correspond to the current price action coloring event.
Projecting potential future price action based on the outcomes of past similar events.
█ Example
In this example, we can see that the current price action pattern matches with a similar historical price action pattern that shares the same characteristics regarding candle coloring. The historical outcome is then projected into the future. This helps traders to understand how the past pattern evolved over time.
█ How to use
The indicator provides traders with valuable insights into how the market might react to the current price action event by examining similar historical patterns and projecting potential future price movements.
█ Settings
Candle series
The candle lookback length refers to the number of bars, starting from the current one, that will be examined in order to find a similar event in the past.
Forecast Candles
Number of candles to project into the future.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

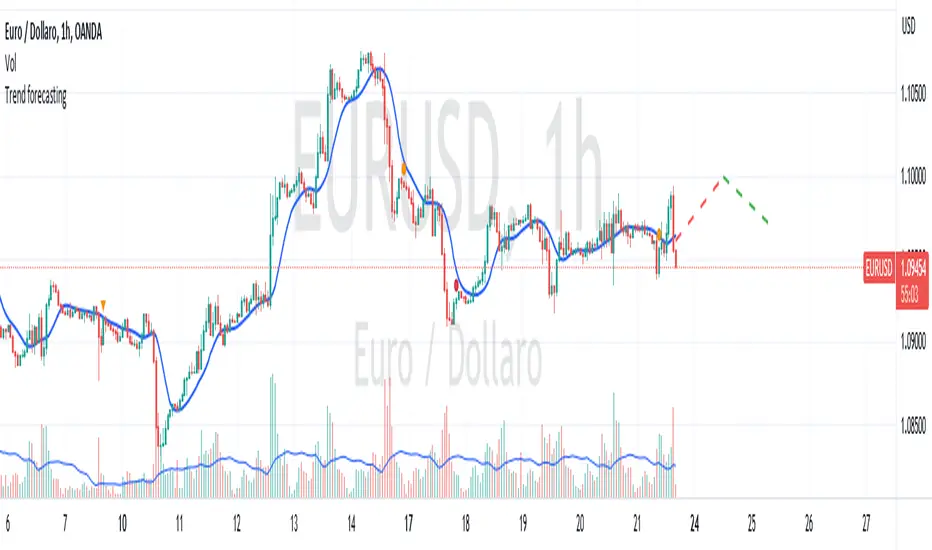
Trend forecasting by c00l75----------- ITALIANO -----------
Questo codice è uno script di previsione del trend creato solo a scopo didattico. Utilizza una media mobile esponenziale (EMA) e una media mobile di Hull (HMA) per calcolare il trend attuale e prevedere il trend futuro. Il codice utilizza anche una regressione lineare per calcolare il trend attuale e un fattore di smorzamento per regolare l’effetto della regressione lineare sulla previsione del trend. Infine il codice disegna due linee tratteggiate per mostrare la previsione del trend per i periodi futuri specificati dall’utente. Se ti piace l'idea mettimi un boost e lascia un commento!
----------- ENGLISH -----------
This code is a trend forecasting script created for educational purposes only. It uses an exponential moving average (EMA) and a Hull moving average (HMA) to calculate the current trend and forecast the future trend. The code also uses a linear regression to calculate the current trend and a damping factor to adjust the effect of the linear regression on the trend prediction. Finally, the code draws two dashed lines to show the trend prediction for future periods specified by the user. If you like the idea please put a boost and leave a comment!
Volume Forecasting [LuxAlgo]The Volume Forecasting indicator provides a forecast of volume by capturing and extrapolating periodic fluctuations. Historical forecasts are also provided to compare the method against volume at time t .
This script will not work on tickers that do not have volume data.
🔶 SETTINGS
Median Memory: Number of days used to compute the median and first/third quartiles.
Forecast Window: Number of bars forecasted in the future.
Auto Forecast Window: Set the forecast window so that the forecast length completes an interval.
🔶 USAGE
The periodic nature of volume on certain securities allows users to more easily forecast using historical volume. The forecast can highlight intervals where volume tends to be more important, that is where most trading activity takes place.
More pronounced periodicity will tend to return more accurate forecasts.
The historical forecast can also highlight intervals where high/low volume is not expected.
The interquartile range is also highlighted, giving an area where we can expect the volume to lie.
🔶 DETAILS
This forecasting method is similar to the time series decomposition method used to obtain the seasonal component.
We first segment the chart over equidistant intervals. Each interval is delimited by a change in the daily timeframe.
To forecast volume at time t+1 we see where the current bar lies in the interval, if the bar is the 78th in interval then the forecast on the next bar is made by taking the median of the 79th bar over N intervals, where N is the median memory.
This method ensures capturing the periodic fluctuation of volume.

Momentum Covariance Oscillator by TenozenWell, guess what? A new indicator is here! Again it's a coincidence, as I experiment with my formula. So far it's less noisy than Autoregressive Covariance Oscillator, so possibly this one is better. The formula is much simpler, care me to explain.
___________________________________________________________________________________________________
Yt = close - previous average
Val = Yt/close
___________________________________________________________________________________________________
Welp that's the formula lol. Funny thing is that it's so simple, but it's good! What matters is the use of it haha.
So how to use this Oscillator? If the value is above 0, we expect a bullish response, if the value is below 0 we expect a bearish response. That simple. Ciao.
(Any questions and suggestions? feel free to comment!)

Autoregressive Covariance Oscillator by TenozenWell to be honest I don't know what to name this indicator lol. But anyway, here is my another original work! Gonna give some background of why I create this indicator, it's all pretty much a coincidence when I'm learning about time series analysis.
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
Well, the formula of Auto-covariance is:
E{(X(t)-(t) * (X(t-s)-(t-s))}= Y_s
But I don't multiply both values but rather subtract them:
E{(X(t)-(t) - (X(t-s)-(t-s))}= Y_s?
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
For arm_vald, the equation is as follows:
arm_vald = val_mu + mu_plus_lsm + et
val_mu --> mean of time series
mu_plus_lsm --> val_mu + LSM
et --> error term
As you can see, val_mu^2. I did this so the oscillator is much smoother.
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
After I get the value, I normalize them:
aco = Y_s? / arm_vald
So by this calculation, I get something like an oscillator!
(more details in the code)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
So how to use this indicator? It's so easy! If the value is above 0, we gonna expect a bullish response, if the value is below 0, we gonna expect a bearish response; that simple. Be aware that you should wait for the price to be closed before executing a trade.
Well, try it out! So far this is the most powerful indicator that I've created, hope it's useful. Ciao.
(more updates for the indicator if needed)

Fed Projected Interest RatesThis script shows you the current interest rates by the FED (see ZQ symbol nearest expiration)
and the next expirations (see ZQ further expiration dates).
It is important to keep your expiration and descriptions up to date, to do that to the indicator inputs and change as you please.
