LANZ Strategy 6.0 [Backtest]🔷 LANZ Strategy 6.0 — Precision Backtesting Based on 09:00 NY Candle, Dynamic SL/TP, and Lot Size per Trade
LANZ Strategy 6.0 is the simulation version of the original LANZ 6.0 indicator. It executes a single LIMIT BUY order per day based on the 09:00 a.m. New York candle, using dynamic Stop Loss and Take Profit levels derived from the candle range. Position sizing is calculated automatically using capital, risk percentage, and pip value — allowing accurate trade simulation and performance tracking.
📌 This is a strategy script — It simulates real trades using strategy.entry() and strategy.exit() with full money management for risk-based backtesting.
🧠 Core Logic & Trade Conditions
🔹 BUY Signal Trigger:
At 09:00 a.m. NY (New York time), if:
The current candle is bullish (close > open)
→ A BUY order is placed at the candle’s close price (EP)
Only one signal is evaluated per day.
⚙️ Stop Loss / Take Profit Logic
SL can be:
Wick low (0%)
Or dynamically calculated using a % of the full candle range
TP is calculated using the user-defined Risk/Reward ratio (e.g., 1:4)
The TP and SL levels are passed to strategy.exit() for each trade simulation.
💰 Risk Management & Lot Size Calculation
Before placing the trade:
The system calculates pip distance from EP to SL
Computes the lot size based on:
Account capital
Risk % per trade
Pip value (auto or manual)
This ensures every trade uses consistent, scalable risk regardless of instrument.
🕒 Manual Close at 3:00 p.m. NY
If the trade is still open by 15:00 NY time, it will be closed using strategy.close().
The final result is the actual % gain/loss based on how far price moved relative to SL.
📊 Backtest Accuracy
One trade per day
LIMIT order at the candle close
SL and TP pre-defined at execution
No repainting
Session-restricted (only runs on 1H timeframe)
✅ Ideal For:
Traders who want to backtest a clean and simple daily entry system
Strategy developers seeking reproducible, high-conviction trades
Users who prefer non-repainting, session-based simulations
👨💻 Credits:
💡 Developed by: LANZ
🧠 Logic & Money Management Engine: LANZ
📈 Designed for: 1H charts
🧪 Purpose: Accurate simulation of LANZ 6.0's NY Candle Entry system
Forecasting

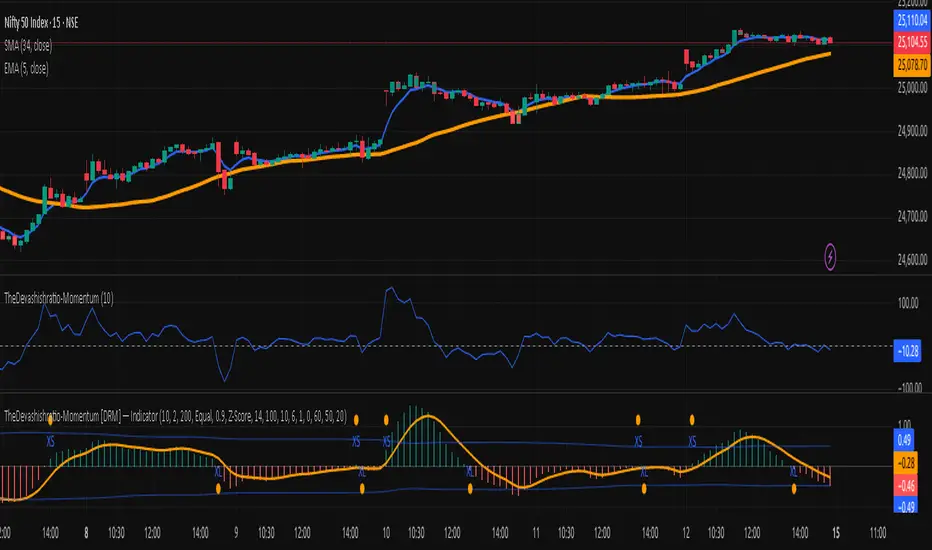
TheDevashishratio-MomentumThis custom momentum indicator is inspired by Fibonacci principles but builds a unique sequence with steps of 0.5 (i.e., 0, 0.5, 1, 1.5, 2, ...). Instead of traditional Fibonacci numbers, each step functions as a dynamic lookback period for a momentum calculation. By cycling through these fractional steps, you capture a layered view of price momentum over varying intervals.
The "Fibonacci" Series Used
Sequence:
0, 0.5, 1, 1.5, 2, … up to a user-defined maximum
For trading indicators, lag values (lookback) must be integers, so each step is rounded to the nearest integer and duplicates are removed, resulting in lookbacks:
1, 2, 3, 4, ... N
Indicator Logic
For each selected lookback, the indicator calculates momentum as:
Momentum
n
=
close
−
close
Momentum
n
=close−close
Where:
close = current price
n = integer from your series of
You can combine these momenta for an averaged or weighted momentum profile, displaying the composite as an oscillator.
How To Use
Bullish: Oscillator above zero indicates positive composite momentum.
Bearish: Oscillator below zero indicates negative composite momentum.
Crosses: A cross from below to above zero may signal emerging bullish momentum, and vice versa.
Customization
Adjust max_step to control how many interval lags you want in your composite.
This oscillator averages across many short and mid-term momenta, reducing noise while still being sensitive to changes.
Summary
TheDevashishratio-Momentum offers a fresh momentum oscillator, blending a "Fibonacci-like" progression with technical analysis, and can be easily copy-pasted into TradingView to experiment and refine your edge.
For more on momentum indicator logic or how to use arrays and series in Pine Script, explore TradingView's official documentation and open-source scripts
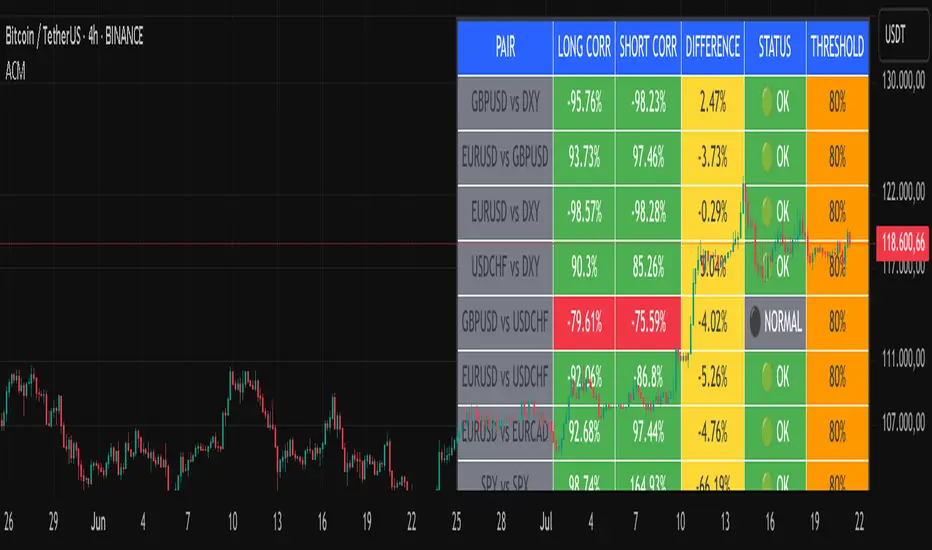
Advanced Correlation Monitor📊 Advanced Correlation Monitor - Pine Script v6
🎯 What does this indicator do?
Monitors real-time correlations between 13 different asset pairs and alerts you when historically strong correlations break, indicating potential trading opportunities or changes in market dynamics.
🚀 Key Features
✨ Multi-Market Monitoring
7 Forex Pairs (GBPUSD/DXY, EURUSD/GBPUSD, etc.)
6 Index/Stock Pairs (SPY/S&P500, DAX/NASDAQ, TSLA/NVDA, etc.)
Fully configurable - change any pair from inputs
📈 Dual Correlation Analysis
Long Period (90 bars): Identifies historically strong correlations
Short Period (6 bars): Detects recent breakdowns
Pearson Correlation using Pine Script v6 native functions
🎨 Intuitive Visualization
Real-time table with 6 information columns
Color coding: Green (correlated), Red (broken), Gray (normal)
Visual states: 🟢 OK, 🔴 BROKEN, ⚫ NORMAL
🚨 Smart Alert System
Only alerts previously correlated pairs (>80% historical)
Detects breakdowns when short correlation <80%
Consolidated alert with all affected pairs
🛠️ Flexible Configuration
Adjustable Parameters:
📅 Periods: Long (30-500), Short (2-50)
🎯 Threshold: 50%-99% (default 80%)
🎨 Table: Configurable position and size
📊 Symbols: All pairs are configurable
Default Pairs:
FOREX: INDICES/STOCKS:
- GBPUSD vs DXY • SPY vs S&P500
- EURUSD vs GBPUSD • DAX vs S&P500
- EURUSD vs DXY • DAX vs NASDAQ
- USDCHF vs DXY • TSLA vs NVDA
- GBPUSD vs USDCHF • MSFT vs NVDA
- EURUSD vs USDCHF • AAPL vs NVDA
- EURUSD vs EURCAD
💡 Practical Use Cases
🔄 Pairs Trading
Detects when strong correlations break for:
Statistical arbitrage
Mean reversion trading
Divergence opportunities
🛡️ Risk Management
Identifies when "safe" assets start moving independently:
Portfolio diversification
Smart hedging
Regime change detection
📊 Market Analysis
Understand underlying market structure:
Forex/DXY correlations
Tech sector rotation
Regional market disconnection
🎓 Results Interpretation
Reading Example:
EURUSD vs DXY: -98.57% → -98.27% | 🟢 OK
└─ Perfect negative correlation maintained (EUR rises when DXY falls)
TSLA vs NVDA: 78.12% → 0% | ⚫ NORMAL
└─ Lost tech correlation (divergence opportunity)
Trading Signals:
🟢 → 🔴: Broken correlation = Possible opportunity
Large difference: Indicates correlation tension
Multiple breaks: Market regime change
PnL_EMA_TRACK12_PRO_3.3_full_adjusted# Multi-Ticker Support
Manage up to 12 tickers simultaneously.
- For each symbol, input share quantities, entry prices, and two optional additional entry points (E2, E3) with their own shares and offset percentages.
- Dynamic handling of inputs using arrays for easier maintenance and scalability.
# Average Cost and PnL Calculation
- Computes weighted average entry costs across all position parts (E1 and optionally E2 and E3).
- Calculates real-time Profit & Loss (PnL) both in USD and percentage relative to the current price.
- Color-coded values: green for profit, red for loss — for quick visual feedback.
# Moving Averages as Benchmarks
- Uses daily EMAs (10, 21, 65) and 15-minute SMA 200 as reference levels.
- Calculates percentage deviations of these moving averages from the average entry price.
- Calculates dollar differences based on the total shares held.
# Chart Visualization
- Draws a dashed yellow line for the average cost of each position.
- Optionally draws two additional lines and labels for E2 (blue) and E3 (purple) if activated.
- Lines extend to the right to emphasize current relevance.
- Labels can be positioned left or right, with customizable horizontal offset.
# Interactive Table in Chart
- Positions the info table in any chosen corner or center of the chart (top/right/left/middle, etc.).
- Displays symbol, PnL (dollar and percentage), and deviations to key EMAs and SMA.
- Colors PnL values according to profit or loss for instant clarity.
# User-Friendly Settings
- Flexible font size options for both the table and labels.
- Customizable colors for positive and negative values (default green/red).
- Choice of label position and X-axis offset to fit your chart style.

No Supply No Demand (NSND) – Volume Spread Analysis ToolThis indicator is designed for traders utilizing Volume Spread Analysis (VSA) techniques. It automatically detects potential No Demand (ND) and No Supply (NS) candles based on volume and price behavior, and confirms them using future price action within a user-defined number of lookahead bars.
Confirmed No Demand (ND): Detected when a bullish candle has volume lower than the previous two bars and is followed by weakness (next highs swept, close below).
Confirmed No Supply (NS): Detected when a bearish candle has volume lower than the previous two bars and is followed by strength (next lows swept, close above).
Adjustable lookahead bars parameter to control the confirmation window.
This tool helps identify potential distribution (ND) and accumulation (NS) areas, providing early signs of market turning points based on professional volume logic. The dot appears next to ND or NS.

PCR tableOverview
This indicator displays a multi-period table of forward-looking price projections. It combines normalized directional momentum (Positive Change Ratio, PCR) with volatility (ATR) and presents a forecast for upcoming time intervals, adjusted for your local UTC offset.
Concepts & Calculations
Positive Change Ratio (PCR):
((total positive change)/(total change)-0.5)*2, producing a value between –100 and +100.
Synthetic ATR: Calculates average true range over the same lookbacks to capture volatility.
PCR × ATR: Forms a volatility-weighted directional forecast, indicating expected move magnitude.
Future Price Projection: Adds PCR × ATR value to current close to estimate future price at each lookahead interval.
Table Layout
There are 12 forecast horizons—1× to 12× the chart timeframe (e.g., minutes, hours, days). Each row displays:
1. Future Time: Timestamp of each projection (adjustable via UTC offset)
2. PCR: Directional bias per period (–1 to +1)
3. PCR × ATR: E xpected move magnitude
4. Future Price: Close + (PCR × ATR)
High and low PCR×ATR rows are highlighted green for minimum value in the price forecast (buy signal) or red for maximum value in the price forecast (sell signal).
How to Use
1. Set UTC offset to your time zone for accurate future timestamps.
2. View PCR to assess bullish (positive) or bearish (negative) momentum.
3. Use PCR × ATR to estimate move strength and direction.
4. Reference Future Price for potential levels over upcoming intervals, and for buy and sell signals.
Limitations & Disclaimers
* This model uses linear extrapolation based on recent price behavior. It does not guarantee future prices.
* It uses only current bar data and no lookahead logic—compliant with Pine Script rules.
* Designed for analytical insight, not as an automated signal or trade executor.
* Best used on standard bar/candle charts (avoid non-standard types like Heikin‑Ashi or Renko).

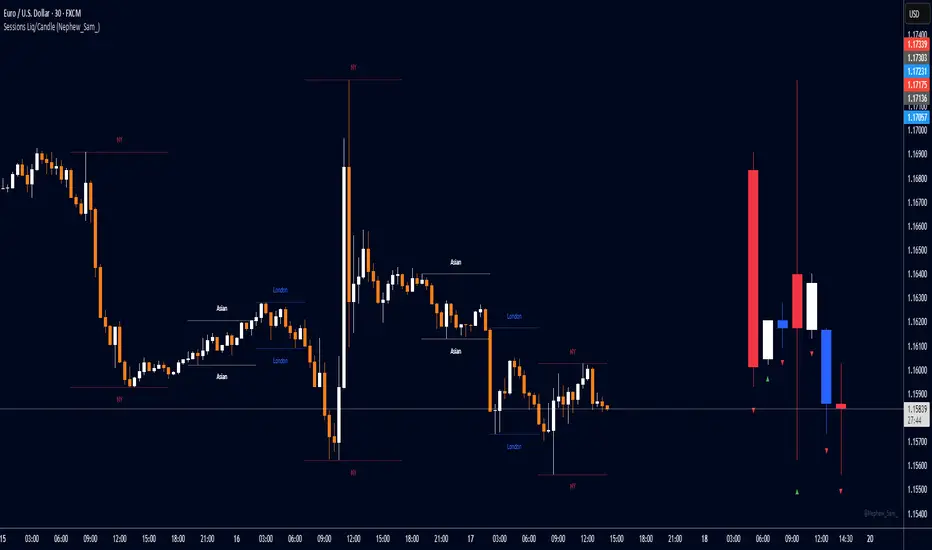
Session HL + Candles + AMD (Nephew_Sam_)Session HL + Candles + AMD (Nephew_Sam_)
This indicator marks out intraday sessions summarized into single candles, with an additional option to mark out the HL of each session. Perfect for understanding AMD within a glance (accumulation-manipulation-distribution)
Features:
Session High/Low lines with customizable colors and labels
Optional session candles displayed on the right side of the chart
Timezone support for global traders
Customizable bull/bear candle colors
Works on timeframes up to 1 hour
Perfect for:
Identifying session liquidity levels
Tracking session ranges and breakouts
Multi-timeframe session analysis
ICT methodology traders
Settings:
Choose your timezone for accurate session detection
Toggle session candles and HL lines independently
Customize colors, line styles, and labels
Set maximum timeframe (up to 1 hour)
AI Breakout Bands (Zeiierman)█ Overview
AI Breakout Bands (Zeiierman) is an adaptive trend and breakout detection system that combines Kalman filtering with advanced K-Nearest Neighbor (KNN) smoothing. The result is a smart, self-adjusting band structure that adapts to dynamic market behavior, identifying breakout conditions with precision and visual clarity.
At its core, this indicator estimates price behavior using a two-dimensional Kalman filter (position + velocity), then enhances the smoothing process with a nonlinear, similarity-based KNN filter. This unique blend enables it to handle noisy markets and directional shifts with both speed and stability — providing breakout traders and trend followers a reliable framework to act on.
Whether you're identifying volatility expansions, capturing trend continuations, or spotting early breakout conditions, AI Breakout Bands gives you a mathematically grounded, visually adaptive roadmap of real-time market structure.
█ How It Works
⚪ Kalman Filter Engine
The Kalman filter models price movement as a state system with two components:
Position (price)
Velocity (trend direction)
It recursively updates predictions using real-time price as a noisy observation, balancing responsiveness with smoothness.
Process Noise (Position) controls sensitivity to sudden moves.
Process Noise (Velocity) controls smoothing of directional flow.
Measurement Noise (R) defines how much the filter "trusts" live price data.
This component alone creates a responsive yet stable estimate of the market’s center of gravity.
⚪ Advanced K-Neighbor Smoothing
After the Kalman estimate is computed, the script applies a custom K-Nearest Neighbor (KNN) smoother.
Rather than averaging raw values, this method:
Finds K most similar past Kalman values
Weighs them by similarity (inverse of absolute distance)
Produces a smoother that emphasizes structural similarity
This nonlinear approach gives the indicator an AI feature — reacting fast when needed, yet staying calm in consolidation.
█ How to Use
⚪ Trend Recognition
The line color shifts dynamically based on slope direction and breakout confirmation.
Bullish conditions: price above the mid band with positive slope
Bearish conditions: price below the mid band with negative slope
⚪ Breakout Signals
Price breaking above or below the bands may signal momentum acceleration.
Combine with your own volume or momentum confirmation for stronger entries.
Bands adapt to market noise, helping filter out low-quality whipsaws.
█ Settings
Process Noise (Position): Controls Kalman filter’s sensitivity to price changes.
Process Noise (Velocity): Controls smoothing of directional component.
Measurement Noise (R): Defines how much trust is placed in price data.
K-Neighbor Length: Number of historical Kalman values considered for smoothing.
Slope Calculation Window: Number of bars used to compute trend slope of the smoothed Kalman.
Band Lookback (MAE): Rolling period for average absolute error.
Band Multiplier: Multiplies MAE to determine band width.
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.

Checklist Dashboard Table# Checklist Dashboard Table – ICT/SMC Trading Helper
Overview
The “Checklist Dashboard Table” is a TradingView indicator designed to help traders structure, organize, and validate their market analyses following the ICT/SMC (Inner Circle Trader / Smart Money Concepts) methodology. It provides a visual and interactive checklist directly on your chart, ensuring you never miss a crucial step in your decision-making process.
Key Features
- Visual Checklist : All your trading criteria are displayed as color-coded checkboxes (green for validated, red for not validated), making your analysis process both clear and efficient.
- Clear Separation Between Analysis and Confirmations :
- Analysis : Reminders for your routine, such as timeframe selection (M3 to H4), trend analysis via RSI, and identification of key zones (Midnight Open, SSL/BSL, Asian High/Low).
- Confirmations : Six customizable criteria to check off as you validate your setup (clear trend, OB + FVG, OTE zone, Premium/Discount, R/R > 1:2, CBDR/Midnight).
- Personal Notes Section : Keep your trade entries, observations, or comments in a dedicated field in the indicator’s settings. Your notes are displayed right in the checklist for quick reference and journaling.
- Elegant and Compact Display : The table is styled for readability and can be positioned anywhere on your chart.
- Quick Customization : Instantly update any criterion or your personal notes via the script settings.
How to Use
1. Add the indicator to your chart.
2. Review the “Analysis” section as your pre-trade routine reminder.
3. Check off the “Confirmations” criteria as you validate your entry strategy.
4. Write your trade notes or comments in the provided notes section.
5. Use the checklist to reinforce discipline and repeatability in your trading.
Why Use This Checklist?
- Prevents you from skipping important steps in your analysis.
- Reinforces trading discipline and consistency.
- Allows you to document and review your trade decisions for ongoing improvement.
Who Is It For?
Perfect for ICT/SMC traders, but also valuable for anyone looking to organize and systematize their trading process.
Happy trading!

Sniper Mini VWAPThis script plots dynamic, session-based VWAPs for key intraday timeframes:
1H (green), 4H (orange), 8H (purple), and Daily (red).
Each VWAP resets at the start of its own session, giving traders a real-time view of price relative to average volume-weighted value. These lines often act as intraday support, resistance, or liquidity magnets — great for scalping, fade setups, and sniper-style entries.
You can toggle each VWAP on or off for a cleaner chart.
This version does not use anchored VWAPs — it’s designed for traders who need fast feedback as price develops within active sessions.

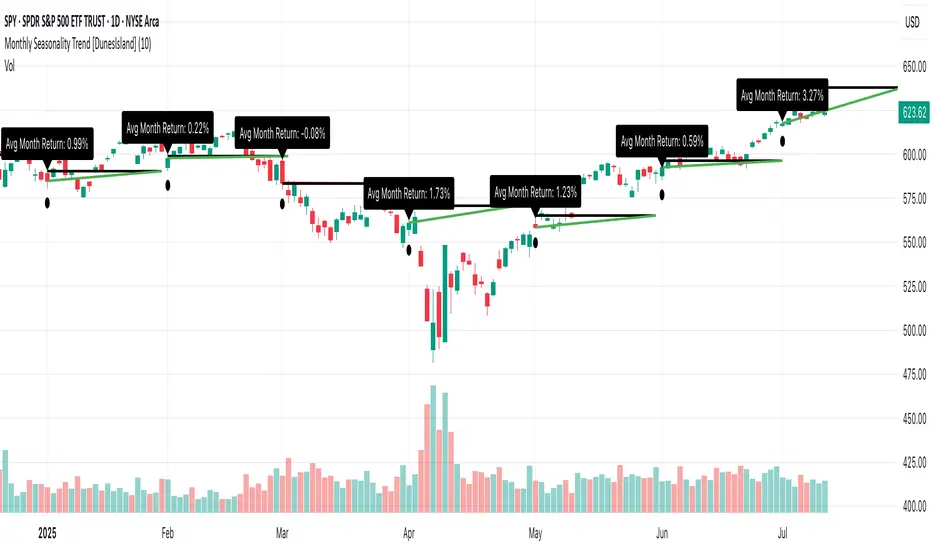
Monthly Seasonality Trend [DunesIsland]The Monthly Seasonality Trend is a indicator designed to analyze and visualize historical monthly seasonality patterns in financial markets. By calculating the average monthly return over a user-configurable lookback period (1 to 10 years), this indicator provides traders and investors with a clear projection of potential price movements for the current month, enabling data-driven decision-making.
How It Works
The indicator operates by retrieving monthly open and close prices for the specified lookback period (up to 10 years) and computing the average percentage return for the current month based on historical data. Key functionalities include:
Dynamic Trend Line: On the first trading day of each month, the indicator plots a line projecting the expected price trajectory, starting from the current close price and extending to the estimated end-of-month price based on the average historical return. The line is colored green for anticipated price increases or red for expected declines, offering an intuitive visual cue.
Average Return Label: A label is displayed at the start of each month, detailing the calculated average historical return for that month, expressed as a percentage, to provide context for the projected trend.
First Trading Day Marker: A small circle is plotted below the bar on the first trading day of each month, clearly marking the start of the projection period.
Adaptive Bar Counting: The indicator dynamically adjusts the length of the trend line based on the actual number of trading days in the previous month, ensuring accurate projections.
How to Interpret
Bullish Projection (Green Line): Indicates that historical data suggests an average price increase for the current month, potentially signaling buying opportunities.
Bearish Projection (Red Line): Suggests an average price decline based on historical trends, which may prompt caution or short-selling strategies.
Historical Context: The average return label provides a quantitative measure of past performance, helping traders assess the reliability of the projected trend.
Institutional Sweep Zone (Range-Based)Institutional Sweep Zone (Range-Based)
This indicator models potential stop sweep zones based on institutional capital ranges, helping traders visualize where high-probability liquidity grabs are likely to occur.
Unlike traditional volatility bands, this tool estimates price movement by calculating how far a specific amount of capital—entered into the market—can push price. By defining a lower and upper capital range (in millions of USD), the indicator dynamically draws bands representing the distance institutions could realistically move price in either direction.
It supports directional control, allowing you to focus on long sweeps, short sweeps, or both simultaneously. The pip cost is auto-calibrated based on the selected currency pair, making it highly adaptive to major FX pairs.
Key Features:
-Capital input range (in millions of USD)
-Directional sweep targeting: Long, Short, or Both
-Auto-detection of pip value based on FX pair
-Visual sweep zone mapped above and below current price
-Designed to highlight areas of institutional stop hunts
Why use it?
-Helps avoid setting stops inside common sweep zones
-Improves trade survivability when paired with higher timeframe strategies
-Offers a unique way to view price through an institutional lens
Created by: The_Forex_Steward
Explore more advanced tools and concepts on my TradingView profile.

Golden Ratio Trend Persistence [EWT]Golden Ratio Trend Persistence
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Overview
The Golden Ratio Trend Persistence is a dynamic tool designed to identify the strength and persistence of market trends. It operates on a simple yet powerful premise: a trend is likely to continue as long as it doesn't retrace beyond the key Fibonacci golden ratio of 61.8%.
This indicator automatically identifies the most significant swing high or low and plots a single, dynamic line representing the 61.8% retracement level of the current move. This line acts as a "line in the sand" for the prevailing trend. The background color also changes to provide an immediate visual cue of the current market direction.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The Power of the Golden Ratio (61.8%)
The golden ratio (ϕ≈1.618) and its inverse (0.618, or 61.8%) are fundamental mathematical constants that appear throughout nature, art, and science, often representing harmony and structure. In financial markets, this ratio is a cornerstone of Fibonacci analysis and is considered one of the most critical levels for price retracements.
Market movements are not linear; they progress in waves of impulse and correction. The 61.8% level often acts as the ultimate point of support or resistance. A trend that can hold this level demonstrates underlying strength and is likely to persist. A breach of this level, however, suggests a fundamental shift in market sentiment and a potential reversal.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
How to Use This Indicator
This indicator is designed for clarity and ease of use.
Identifying the Trend : The visual cues make the current trend instantly recognizable.
A teal line with a teal background signifies a bullish trend. The line acts as dynamic support.
A maroon line with a maroon background signifies a bearish trend. The line acts as dynamic resistance.
Confirming Trend Persistence : As long as the price respects the plotted level, the trend is considered intact.
In an uptrend, prices should remain above the teal line. The indicator will automatically adjust its anchor to new, higher lows, causing the support line to trail the price.
In a downtrend, prices should remain below the maroon line.
Spotting Trend Reversals : The primary signal is a trend reversal, which occurs when the price closes decisively beyond the plotted level.
Potential Sell Signal : When the price closes below the teal support line, it indicates that buying pressure has failed, and the uptrend is likely over.
Potential Buy Signal : When the price closes above the maroon resistance line, it indicates that selling pressure has subsided, and a new uptrend may be starting.
Think of this tool as an intelligent, adaptive trailing stop that is based on market structure and the time-tested principles of Fibonacci analysis.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Input Parameters
You can customize the indicator's sensitivity through the following inputs in the settings menu:
Pivot Lookback Left : This number defines how many bars to the left of a candle must be lower (for a pivot high) or higher (for a pivot low) to identify a potential swing point. A higher value will result in fewer, but more significant, pivots being detected.
Pivot Lookback Right : This defines the number of bars that must close to the right before a swing point is confirmed. This parameter prevents the indicator from repainting. A higher value increases confirmation strength but also adds a slight lag.
Fibonacci Ratio : While the default is the golden ratio (0.618), you can adjust this to other key Fibonacci levels, such as 0.5 (50%) or 0.382 (38.2%), to test for different levels of trend persistence.
Adjusting these parameters allows you to fine-tune the indicator for different assets, timeframes, and trading styles, from short-term scalping to long-term trend following.
Quantum Harmonic Oscillator Overlay🧪 Quantum Harmonic Oscillator Overlay
A visual model of price behavior using quantum harmonic oscillation principles
📜 Indicator Overview
The Quantum Harmonic Oscillator Overlay applies concepts from both classical physics (harmonic motion) and quantum mechanics (energy states) to model and visualize how price orbits around a central trend line. It overlays a Linear Regression line (representing the “mean position” or ground state of price) and calculates surrounding energy levels (σ-zones) akin to quantum shells that price can "jump" between.
This indicator is particularly useful for visualizing mean reversion, volatility compression/expansion, and momentum-driven price breakthroughs.
🧠 Core Concepts
Linear Regression Line (LSR): This is the calculated center of gravity or equilibrium path of price over a user-defined period. Think of it like the lowest energy state or central axis around which price vibrates.
Standard Deviation Zones (σ-levels):
1σ: The majority of normal price activity; within this range, price tends to fluctuate if in balance.
2σ: Indicates volatility or possible breakout pressure.
3σ: Represents extreme movement — a phase shift in energy, potentially leading to reversal or continuation with higher momentum.
Quantum Analogy: Just like in a quantum harmonic oscillator, particles (here, prices) move probabilistically between discrete energy states. The further the price moves from the center, the more "energy" (momentum, volume, volatility) is implied.
⚙️ Input Parameters
Setting Description
Linear Regression Length The number of bars used to calculate the regression trend (default 100). Affects the central path and responsiveness.
σ Multipliers (1σ, 2σ, 3σ) Determine how far each band is from the regression line. Adjusting these can highlight different price behaviors.
Show Energy Level Zones Toggle visibility of the colored bands around the regression line.
Show LSR Center Line Toggles visibility of the white Linear Regression line itself.
🎨 Visual Components
Color Zone Interpretation
✅ Green ±1σ Normal oscillation / mean reversion area. Ideal for range-bound strategies.
🟧 Orange ±2σ Warning zone; price may be gaining momentum or volatility.
🔴 Red ±3σ High-momentum state or anomaly. These regions may imply trend exhaustion, reversals, or breakouts.
White Line: The LSR — the average trajectory of the price movement.
Pink Dots: Appear when price exceeds Zone 3 (outside ±3σ) — a signal of extreme behavior or a possible regime shift.
📈 How to Use This Indicator
1. Detect Overextensions
When price touches or breaches the 3σ zone, it is likely overextended. This can be used to anticipate potential snapbacks or strong breakout trends.
2. Identify Mean Reversion Trades
If price exits the 2σ or 3σ zones and returns toward the center line, this signals a likely mean reversion setup.
3. Volatility Compression or Expansion
Flat zones between σ levels suggest calm markets; widening bands suggest expanding volatility.
4. Use with Confirmation Tools
Combine with momentum oscillators (MACD, RSI) or volume-based signals to confirm reversals or continuation outside Zone 3.
🔮 Philosophical Note
This indicator embodies the metaphor that the market behaves like a quantum oscillator — price particles exist in a probabilistic field and jump between discrete zones of volatility and energy. Tracking these transitions allows the trader to see price behavior as rhythmic, wave-like, and multidimensional rather than purely linear.

Futures Support & Resistance LevelsMulti-Timeframe Support & Resistance Levels for Futures Trading
Description:
This indicator automatically identifies and displays key support and resistance levels using multiple technical analysis methods. Designed specifically for futures traders (ES, NQ, etc.), it provides a clean, organized view of important price levels.
Key Features:
Multiple Detection Methods: Combines pivot points, daily ranges, and psychological levels
Smart Ranking System: Levels are numbered by strength (1 = strongest)
Clean Visualization: Extended lines across the chart with clear price labels
Confluence Detection: Highlights areas where multiple levels converge
Customizable Display: Adjust colors, line styles, and label sizes
Level Types Identified:
Daily High/Low (current session)
Previous Daily High/Low
Pivot-based Support/Resistance
Psychological Round Numbers
Confluence Zones (multiple levels clustering)
Technical Approach:
The indicator uses a strength-scoring algorithm to rank levels by importance. Daily levels receive the highest weighting (2.0), followed by previous daily levels (1.5), pivot points (1.0), and psychological levels (0.5). This helps traders focus on the most significant levels.
Visual Elements:
Solid lines = Strong levels
Dashed lines = Medium levels
Dotted lines = Weak levels
Optional technical condition markers for educational analysis
Best Used For:
Identifying key intraday levels for futures trading
Finding high-probability reversal zones
Setting logical stop-loss and take-profit levels
Recognizing confluence areas for stronger setups
Note:
This is a technical analysis tool for educational purposes. No indicator can predict future price movements. Always use proper risk management and combine with other forms of analysis.

Mongoose Capital: BTC ETF DriftScope ProMongoose Capital: BTC ETF DriftScope Pro
A proprietary indicator for monitoring drift between Bitcoin Spot (BTCUSD) and Bitcoin Spot ETFs (such as IBIT). Designed to detect ETF premium/discount zones and generate actionable Fade or Long bias signals.
What it Does
Tracks IBIT and BTCUSD spread to highlight ETF price deviations.
Calculates correlation Z-Score for ETF/Spot alignment.
Outputs numeric bias signals: Fade (1), Long (1), Neutral (1).
How to Use
Apply to a BTCUSD chart (4H, 1D, or higher recommended).
Open the Data Window to view:
IBIT Spread %
Correlation Z-Score
Correlation %
Bias Flags (Fade, Long, Neutral)
Configure alerts for Fade and Long Bias conditions.
Confirm all signals with your trade plan and risk management.
Methodology
This tool calculates the percentage spread between IBIT and BTC Spot. A rolling Z-Score of the correlation is used to detect periods of significant divergence.
Fade Bias suggests potential short setups in premium zones with high Z-Scores.
Long Bias suggests potential long setups in discount zones with low Z-Scores.
Disclaimer
This indicator is for educational purposes only. It is not financial advice. Use at your own risk and verify signals independently.

IU Inside/Harami candlestick patternDESCRIPTION
The IU Inside/Harami Candlestick Pattern indicator is designed to detect bullish and bearish inside bar formations, also known as Harami patterns. This tool gives users flexibility by allowing pattern detection based on candle wicks, bodies, or a combination of both. It highlights detected patterns using colored boxes and optional text labels on the chart, helping traders quickly identify areas of consolidation and potential reversals.
USER INPUTS :
Pattern Recognition Based on =
Choose between "Wicks", "Body", or "Both" to determine how the inside candle pattern is identified.
Show Box =
Toggle the appearance of colored boxes that highlight the pattern zone.
Show Text =
Toggle on-screen labels for "Bullish Inside" or "Bearish Inside" when patterns are detected.
INDICATOR LOGIC :
Bullish Inside Bar (Harami) is detected when:
* The current candle's high is lower and low is higher than the previous candle (wick-based),
* or the current candle’s open and close are inside the previous candle’s body (body-based),
* and the current candle is bullish while the previous is bearish.
Bearish Inside Bar (Harami) is detected when:
* The current candle's high is lower and low is higher than the previous candle (wick-based),
* or the current candle’s open and close are inside the previous candle’s body (body-based),
* and the current candle is bearish while the previous is bullish.
The user can choose wick-based, body-based, or both logics for pattern confirmation.
Boxes are drawn between the highs and lows of the pattern, and alert messages are generated upon confirmation.
Optional labels show the pattern name for quick visual identification.
WHY IT IS UNIQUE :
Offers three different logic modes: wick-based, body-based, or combined.
Highlights patterns visually with customizable boxes and labels.
Includes built-in alerts for immediate notifications.
Uses clean and transparent plotting without repainting.
HOW USER CAN BENEFIT FROM IT :
Receive real-time alerts when Inside/Harami patterns are formed.
Use the boxes and text labels to spot price compression zones and breakout potential.
Combine it with other tools like trendlines or support/resistance for enhanced accuracy.
Suitable for scalpers, swing traders, and price action traders looking to trade inside bar breakouts or reversals.
DISCLAIMER :
This indicator is not financial advice, it's for educational purposes only highlighting the power of coding( pine script) in TradingView, I am not a SEBI-registered advisor. Trading and investing involve risk, and you should consult with a qualified financial advisor before making any trading decisions. I do not guarantee profits or take responsibility for any losses you may incur.

Position Size Calculator with Fees# Position Size Calculator with Portfolio Management - Manual
## Overview
The Position Size Calculator with Portfolio Management is an advanced Pine Script indicator designed to help traders calculate optimal position sizes based on their total portfolio value and risk management strategy. This tool automatically calculates your risk amount based on portfolio allocation percentages and determines the exact position size needed while accounting for trading fees.
## Key Features
- **Portfolio-Based Risk Management**: Calculates risk based on total portfolio value
- **Tiered Risk Allocation**: Separates trading allocation from total portfolio
- **Automatic Trade Direction Detection**: Determines long/short based on entry vs stop loss
- **Fee Integration**: Accounts for trading fees in position size calculations
- **Risk Factor Adjustment**: Allows scaling of position size up or down
- **Visual Display**: Shows all calculations in a clear, color-coded table
- **Automatic Risk Calculation**: No need to manually input risk amount
## Input Parameters
### Total Portfolio ($)
- **Purpose**: The total value of your investment portfolio
- **Default**: 0.0
- **Range**: Any positive value
- **Step**: 0.01
- **Example**: If your total portfolio is worth $100,000, enter 100000
### Trading Portfolio Allocation (%)
- **Purpose**: The percentage of your total portfolio allocated to active trading
- **Default**: 20.0%
- **Range**: 0.0% to 100.0%
- **Step**: 0.01
- **Example**: If you allocate 20% of your portfolio to trading, enter 20
### Risk from Trading (%)
- **Purpose**: The percentage of your trading allocation you're willing to risk per trade
- **Default**: 0.1%
- **Range**: Any positive value
- **Step**: 0.01
- **Example**: If you risk 0.1% of your trading allocation per trade, enter 0.1
### Entry Price ($)
- **Purpose**: The price at which you plan to enter the trade
- **Default**: 0.0
- **Range**: Any positive value
- **Step**: 0.01
### Stop Loss ($)
- **Purpose**: The price at which you will exit if the trade goes against you
- **Default**: 0.0
- **Range**: Any positive value
- **Step**: 0.01
### Risk Factor
- **Purpose**: A multiplier to scale your position size up or down
- **Default**: 1.0 (no scaling)
- **Range**: 0.0 to 10.0
- **Step**: 0.1
- **Examples**:
- 1.0 = Normal position size
- 2.0 = Double the position size
- 0.5 = Half the position size
### Fee (%)
- **Purpose**: The percentage fee charged per transaction
- **Default**: 0.01% (0.01)
- **Range**: 0.0% to 1.0%
- **Step**: 0.001
## How Risk Amount is Calculated
The script automatically calculates your risk amount using this formula:
```
Risk Amount = Total Portfolio × Trading Allocation (%) × Risk % ÷ 10,000
```
### Example Calculation:
- Total Portfolio: $100,000
- Trading Allocation: 20%
- Risk per Trade: 0.1%
**Risk Amount = $100,000 × 20 × 0.1 ÷ 10,000 = $20**
This means you would risk $20 per trade, which is 0.1% of your $20,000 trading allocation.
## Portfolio Structure Example
Let's say you have a $100,000 portfolio:
### Allocation Structure:
- **Total Portfolio**: $100,000
- **Trading Allocation (20%)**: $20,000
- **Long-term Investments (80%)**: $80,000
### Risk Management:
- **Risk per Trade (0.1% of trading)**: $20
- **Maximum trades at risk**: Could theoretically have 1,000 trades before risking entire trading allocation
## How Position Size is Calculated
### Trade Direction Detection
- **Long Trade**: Entry price > Stop loss price
- **Short Trade**: Entry price < Stop loss price
### Position Size Formulas
#### For Long Trades:
```
Position Size = -Risk Factor × Risk Amount / (Stop Loss × (1 - Fee) - Entry Price × (1 + Fee))
```
#### For Short Trades:
```
Position Size = -Risk Factor × Risk Amount / (Entry Price × (1 - Fee) - Stop Loss × (1 + Fee))
```
## Output Display
The indicator displays a comprehensive table with color-coded sections:
### Portfolio Information (Light Blue Background)
- **Portfolio (USD)**: Your total portfolio value
- **Trading Portfolio Allocation (%)**: Percentage allocated to trading
- **Risk as % of Trading**: Risk percentage per trade
### Trade Setup (Gray Background)
- **Entry Price**: Your specified entry price
- **Stop Loss**: Your specified stop loss price
- **Fee (%)**: Trading fee percentage
- **Risk Factor**: Position size multiplier
### Risk Analysis (Red Background)
- **Risk Amount**: Automatically calculated dollar risk
- **Effective Entry**: Actual entry cost including fees
- **Effective Exit**: Actual exit value including fees
- **Expected Loss**: Calculated loss if stop loss is hit
- **Deviation from Risk %**: Accuracy of risk calculation
### Final Result (Blue Background)
- **Position Size**: Number of shares/units to trade
## Usage Examples
### Example 1: Conservative Long Trade
- **Total Portfolio**: $50,000
- **Trading Allocation**: 15%
- **Risk per Trade**: 0.05%
- **Entry Price**: $25.00
- **Stop Loss**: $24.00
- **Risk Factor**: 1.0
- **Fee**: 0.01%
**Calculated Risk Amount**: $50,000 × 15% × 0.05% ÷ 100 = $3.75
### Example 2: Aggressive Short Trade
- **Total Portfolio**: $200,000
- **Trading Allocation**: 30%
- **Risk per Trade**: 0.2%
- **Entry Price**: $150.00
- **Stop Loss**: $155.00
- **Risk Factor**: 2.0
- **Fee**: 0.01%
**Calculated Risk Amount**: $200,000 × 30% × 0.2% ÷ 100 = $120
**Actual Risk**: $120 × 2.0 = $240 (due to risk factor)
## Color Coding System
- **Green/Red Header**: Trade direction (Long/Short)
- **Light Blue**: Portfolio management parameters
- **Gray**: Trade setup parameters
- **Red**: Risk-related calculations and results
- **Blue**: Final position size result
## Best Practices
### Portfolio Management
1. **Keep trading allocation reasonable** (typically 10-30% of total portfolio)
2. **Use conservative risk percentages** (0.05-0.2% per trade)
3. **Don't risk more than you can afford to lose**
### Risk Management
1. **Start with small risk factors** (1.0 or less) until comfortable
2. **Monitor your total exposure** across all open positions
3. **Adjust risk based on market conditions**
### Trade Execution
1. **Always validate calculations** before placing trades
2. **Account for slippage** in volatile markets
3. **Consider position size relative to liquidity**
## Risk Management Guidelines
### Conservative Approach
- Trading Allocation: 10-20%
- Risk per Trade: 0.05-0.1%
- Risk Factor: 0.5-1.0
### Moderate Approach
- Trading Allocation: 20-30%
- Risk per Trade: 0.1-0.15%
- Risk Factor: 1.0-1.5
### Aggressive Approach
- Trading Allocation: 30-40%
- Risk per Trade: 0.15-0.25%
- Risk Factor: 1.5-2.0
## Troubleshooting
### Common Issues
1. **Position Size shows 0**
- Verify all portfolio inputs are greater than 0
- Check that entry price differs from stop loss
- Ensure calculated risk amount is positive
2. **Very small position sizes**
- Increase risk percentage or risk factor
- Check if your risk amount is too small for the price difference
3. **Large risk deviation**
- Normal for very small positions
- Consider adjusting entry/stop loss levels
### Validation Checklist
- Total portfolio value is realistic
- Trading allocation percentage makes sense
- Risk percentage is conservative
- Entry and stop loss prices are valid
- Trade direction matches your intention
## Advanced Features
### Risk Factor Usage
- **Scaling up**: Use risk factors > 1.0 for high-confidence trades
- **Scaling down**: Use risk factors < 1.0 for uncertain trades
- **Never exceed**: Risk factors that would risk more than your comfort level
### Multiple Timeframe Analysis
- Use different risk factors for different timeframes
- Consider correlation between positions
- Adjust trading allocation based on market conditions
## Disclaimer
This tool is for educational and planning purposes only. Always verify calculations manually and consider market conditions, liquidity, and correlation between positions. The automated risk calculation assumes you're comfortable with the mathematical relationship between portfolio allocation and individual trade risk. Past performance doesn't guarantee future results, and all trading involves risk of loss.

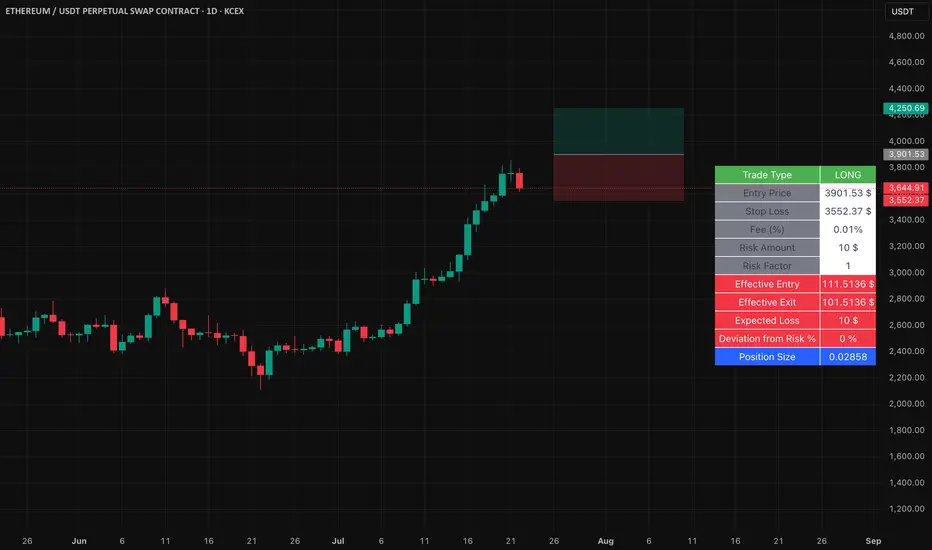
Easy Position Size Calculator with Fees# Easy Position Size Calculator with Fees - Manual
## Overview
The Easy Position Size Calculator is a Pine Script indicator designed to help traders calculate the optimal position size for their trades while accounting for trading fees. This tool automatically determines whether you're planning a long or short position and calculates the exact position size needed to risk a specific dollar amount.
## Key Features
- **Automatic Trade Direction Detection**: Determines if you're going long or short based on entry price vs stop loss
- **Fee Integration**: Accounts for trading fees in position size calculations
- **Risk Management**: Calculates position size based on your specified risk amount
- **Risk Factor Adjustment**: Allows you to scale your position size up or down
- **Visual Display**: Shows all calculations in a clear, organized table
## Input Parameters
### Entry Price ($)
- **Purpose**: The price at which you plan to enter the trade
- **Default**: 0.0
- **Range**: Any positive value
- **Step**: 0.01
### Stop Loss ($)
- **Purpose**: The price at which you will exit the trade if it goes against you
- **Default**: 0.0
- **Range**: Any positive value
- **Step**: 0.01
### Risk ($)
- **Purpose**: The maximum dollar amount you're willing to lose on this trade
- **Default**: 0.0
- **Range**: Any positive value
- **Step**: 0.01
### Risk Factor
- **Purpose**: A multiplier to scale your position size up or down
- **Default**: 1.0 (no scaling)
- **Range**: 0.0 to 10.0
- **Step**: 0.1
- **Examples**:
- 1.0 = Normal position size
- 2.0 = Double the position size
- 0.5 = Half the position size
### Fee (%)
- **Purpose**: The percentage fee charged per transaction (buy/sell)
- **Default**: 0.01% (0.01)
- **Range**: 0.0% to 1.0%
- **Step**: 0.001
## How It Works
### Trade Direction Detection
The script automatically determines your trade direction:
- **Long Trade**: Entry price > Stop loss price
- **Short Trade**: Entry price < Stop loss price
### Position Size Calculation
#### For Long Trades:
```
Position Size = -Risk Factor × Risk Amount / (Stop Loss × (1 - Fee) - Entry Price × (1 + Fee))
```
#### For Short Trades:
```
Position Size = -Risk Factor × Risk Amount / (Entry Price × (1 - Fee) - Stop Loss × (1 + Fee))
```
### Fee Adjustment
The script accounts for fees on both entry and exit:
- **Long trades**: You pay fees when buying (entry) and selling (exit)
- **Short trades**: You pay fees when shorting (entry) and covering (exit)
## Output Display
The indicator displays a table with the following information:
### Trade Information
- **Trade Type**: Shows whether it's a LONG, SHORT, or INVALID trade
- **Entry Price**: Your specified entry price
- **Stop Loss**: Your specified stop loss price
- **Fee (%)**: The fee percentage being used
### Risk Parameters
- **Risk Amount**: The dollar amount you're willing to risk
- **Risk Factor**: The multiplier being applied
### Calculated Values
- **Effective Entry**: The actual cost per share including fees
- **Effective Exit**: The actual exit value per share including fees
- **Expected Loss**: The calculated loss if stop loss is hit
- **Deviation from Risk %**: Shows how close the expected loss is to your target risk
- **Position Size**: The number of shares/units to trade
## Usage Examples
### Example 1: Long Trade
- Entry Price: $100.00
- Stop Loss: $95.00
- Risk Amount: $500.00
- Risk Factor: 1.0
- Fee: 0.01%
**Result**: The script will calculate how many shares to buy so that if the stop loss is hit, you lose approximately $500 (accounting for fees). Position Size: 99.61152
### Example 2: Short Trade
- Entry Price: $50.00
- Stop Loss: $55.00
- Risk Amount: $300.00
- Risk Factor: 1.0
- Fee: 0.01%
**Result**: The script will calculate how many shares to short so that if the stop loss is hit, you lose approximately $300 (accounting for fees). Position Size: 59.87426
## Important Notes
### Validation Requirements
For the script to work properly, all of the following must be true:
- Entry price > 0
- Stop loss > 0
- Risk amount > 0
- Entry price ≠ Stop loss (to determine direction)
### Negative Position Sizes
The script may show negative position sizes, which is normal:
- **Negative values for long trades**: Represents shares to buy
- **Negative values for short trades**: Represents shares to short
### Risk Deviation
The "Deviation from Risk %" shows how closely the calculated position size matches your target risk. Small deviations are normal due to:
- Fee calculations
- Rounding
- Market precision
## Color Coding
The table uses color coding for easy identification:
- **Green**: Long trade information
- **Red**: Short trade information
- **Gray**: Invalid trade (when inputs are incorrect)
- **Blue**: Final position size
- **Red background**: Risk-related calculations
## Troubleshooting
### Common Issues
1. **Position Size shows 0**
- Check that all inputs are greater than 0
- Ensure entry price is different from stop loss
2. **Trade Type shows INVALID**
- Verify that entry price and stop loss are both positive
- Make sure entry price ≠ stop loss
3. **Large Risk Deviation**
- This is normal for very small position sizes
- Consider adjusting your risk amount or price levels
## Best Practices
1. **Always validate your inputs** before placing actual trades
2. **Double-check the trade direction** shown in the table
3. **Review the expected loss** to ensure it aligns with your risk management
4. **Consider the effective entry/exit prices** which include fees
5. **Use appropriate risk factors** - avoid extreme values that could lead to overexposure
## Disclaimer
This tool is for educational and planning purposes only. Always verify calculations manually and consider market conditions, liquidity, and other factors before placing actual trades. The script assumes that fees are charged on both entry and exit transactions.
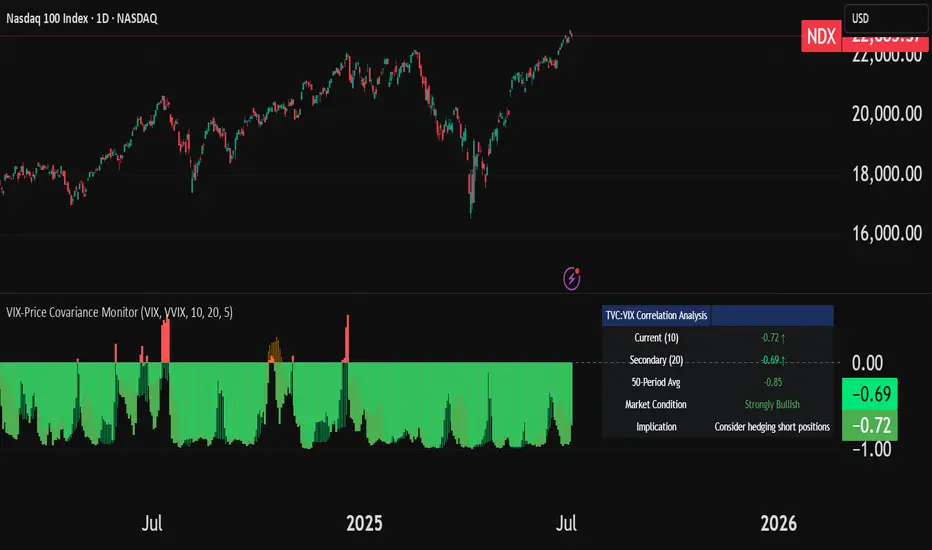
VIX-Price Covariance MonitorThe VIX-Price Covariance Monitor is a statistical tool that measures the evolving relationship between a security's price and volatility indices such as the VIX (or VVIX).
It can give indication of potential market reversal, as typically, volatility and the VIX increase before markets turn red,
This indicator calculates the Pearson correlation coefficient using the formula:
ρ(X,Y) = cov(X,Y) / (σₓ × σᵧ)
Where:
ρ is the correlation coefficient
cov(X,Y) is the covariance between price and the volatility index
σₓ and σᵧ are the standard deviations of price and the volatility index
Enjoy!
Features
Dual Correlation Periods: Analyze both short-term and long-term correlation trends simultaneously
Adaptive Color Coding: Correlation strength is visually represented through color intensity
Market Condition Assessment: Automatic interpretation of correlation values into actionable market insights
Leading/Lagging Analysis: Optional time-shift analysis to detect predictive relationships
Detailed Information Panel: Real-time statistics including current correlation values, historical averages, and trading implications
Interpretation
Positive Correlation (Red): Typically bearish for price, as rising VIX correlates with falling markets. This is what traders should be looking for.
Negative Correlation (Green): Typically bullish for price, as falling VIX correlates with rising markets
How to use it
Apply the indicator to any chart to see its correlation with the default VIX index
Adjust the correlation length to match your trading timeframe (shorter for day trading, longer for swing trading)
Enable the secondary correlation period to compare different timeframes simultaneously
For advanced analysis, enable the Leading/Lagging feature to detect if VIX changes precede or follow price movements
Use the information panel to quickly assess the current market condition and potential trading implications
Smart Directional Fib Zone (Selectable Session)🎯 Overview
This indicator plots a dynamic Fibonacci zone between the 0.5 and 0.618 levels , calculated from the previous day’s price action , and is designed specifically for intraday traders.
It visually highlights key retracement or reaction areas where the market often pauses or reverses.
🔍 How it works
At the start of each day, the script automatically captures:
the previous day’s open (pdo),
high (pdh),
low (pdl),
and close (pdc).
It then determines if the previous day was bullish (Close > Open) or bearish (Close < Open).
Based on that:
If the previous day was bullish, it projects the Fibonacci levels down from the high (typical for expecting retracements).
If bearish, it projects them up from the low.
The two key levels are:
0.5 (50%) retracement / projection
0.618 (61.8%) retracement / projection
A colored zone is plotted between these levels to act as a leading guide for intraday setups.
⏰ Time filtering & session customization
A unique feature is the dynamic session filtering:
By default, the zone is only plotted during active market hours, keeping your chart clean outside trading hours.
The script provides a dropdown selector so you can quickly switch between:
India session (9:15 to 15:30)
Europe session (9:00 to 17:30)
US session (9:30 to 16:00)
Or even define your own custom session times.
This makes it ideal for intraday traders in any region.
🎨 Visual features
The fill zone changes color based on the previous day’s sentiment:
Green zone if the previous day was bullish
Red zone if the previous day was bearish
🚨 Alerts
The script includes an alert condition, so you can easily set up TradingView alerts to notify you when:
Price enters the Fibonacci zone.
This is extremely helpful for catching retracements or reversals without staring at the screen all day.
⚙️ How to use
✅ Works on any intraday timeframe (1 min, 5 min, 15 min, etc.).
✅ Simply add it to your chart, pick your session in the dropdown, and watch the Fibonacci zone automatically adjust to your selected market hours.
Use it as a confluence tool alongside other indicators like VWAP, EMAs, Bollinger Bands, or price action patterns to time entries and exits.
💪 Why this is powerful
This is more than a simple Fib retracement tool:
It dynamically adapts to the previous day’s sentiment, helping you trade in alignment with recent market psychology.
The session filtering ensures your charts are focused only on the periods

Dynamic Gap Probability ToolDynamic Gap Probability Tool measures the percentage gap between price and a chosen moving average, then analyzes your chart history to estimate the likelihood of the next candle moving up or down. It dynamically adjusts its sample size to ensure statistical robustness while focusing on the exact deviation level.
Originality and Value:
• Combines gap-based analysis with dynamic sample aggregation to balance precision and reliability.
• Automatically extends the sample when exact matches are scarce, avoiding misleading signals on rare extreme moves.
• Provides real “next-candle” probabilities based on historical occurrences rather than fixed thresholds or untested heuristics.
• Adds value by giving traders an evidence-based edge: you see how similar past deviations actually played out.
How It Works:
1. Calculate gap = (close – moving average) / moving average * 100.
2. Round the absolute gap to nearest percent (X%).
3. Count historical bars where gap ≥ X% above or ≤ –X% below.
4. If exact X% count is below the minimum occurrences threshold, include gaps at X+1%, X+2%, etc., until threshold is reached.
5. Compute “next-candle” green vs. red probabilities from the aggregated sample.
6. Display current gap, sample size, green probability, and red probability in a table.
Inputs:
• Moving Average Type (SMA, EMA, WMA, VWMA, HMA, SMMA, TMA)
• Moving Average Period (default 200)
• Minimum Occurrences Threshold (default 50)
• Table position and styling options
Examples:
• If price is 3% above the 200-period SMA and 120 occurrences ≥3% are found, with 84 green next candles (70%) and 36 red (30%), the script displays “3% | 120 | 70% green | 30% red.”
• If price is 8% below the SMA but only 20 exact matches exist, the script will include 9% and 10% gaps until it reaches 50 samples, then calculate probabilities from that broader set.
Why It’s Useful:
• Mean-reversion traders see green-probability signals at extreme overbought or oversold levels.
• Trend-followers identify continuation likelihood when red probability is high.
• Risk managers gauge reliability by inspecting sample size before acting on any signal.
Limitations:
• Historical probabilities do not guarantee future performance.
• Results depend on timeframe and symbol, backtest with your data before trading.
• Use realistic slippage and commission when overlaying on strategy scripts.

EVaR Indicator and Position SizingThe Problem:
Financial markets consistently show "fat-tailed" distributions where extreme events occur with higher frequency than predicted by normal distributions (Gaussian or even log-normal). These fat tails manifest in sudden price crashes, volatility spikes, and black swan events that traditional risk measures like volatility can underestimate. Standard deviation and conventional VaR calculations assume normally distributed returns, leaving traders vulnerable to severe drawdowns during market stress.
Cryptocurrencies and volatile instruments display particularly pronounced fat-tailed behavior, with extreme moves occurring 5-10 times more frequently than normal distribution models would predict. This reality demands a more sophisticated approach to risk measurement and position sizing.
The Solution: Entropic Value at Risk (EVAR)
EVaR addresses these limitations by incorporating principles from statistical mechanics and information theory through Tsallis entropy. This advanced approach captures the non-linear dependencies and power-law distributions characteristic of real financial markets.
Entropy is more adaptive than standard deviations and volatility measures.
I was inspired to create this indicator after reading the paper " The End of Mean-Variance? Tsallis Entropy Revolutionises Portfolio Optimisation in Cryptocurrencies " by by Sana Gaied Chortane and Kamel Naoui.
Key advantages of EVAR over traditional risk measures:
Superior tail risk capture: More accurately quantifies the probability of extreme market moves
Adaptability to market regimes: Self-calibrates to changing volatility environments
Non-parametric flexibility: Makes less assumptions about the underlying return distribution
Forward-looking risk assessment: Better anticipates potential market changes (just look at the charts :)
Mathematically, EVAR is defined as:
EVAR_α(X) = inf_{z>0} {z * log(1/α * M_X(1/z))}
Where the moment-generating function is calculated using q-exponentials rather than conventional exponentials, allowing precise modeling of fat-tailed behavior.
Technical Implementation
This indicator implements EVAR through a q-exponential approach from Tsallis statistics:
Returns Calculation: Price returns are calculated over the lookback period
Moment Generating Function: Approximated using q-exponentials to account for fat tails
EVAR Computation: Derived from the MGF and confidence parameter
Normalization: Scaled to for intuitive visualization
Position Sizing: Inversely modulated based on normalized EVAR
The q-parameter controls tail sensitivity—higher values (1.5-2.0) increase the weighting of extreme events in the calculation, making the model more conservative during potentially turbulent conditions.
Indicator Components
1. EVAR Risk Visualization
Dynamic EVAR Plot: Color-coded from red to green normalized risk measurement (0-1)
Risk Thresholds: Reference lines at 0.3, 0.5, and 0.7 delineating risk zones
2. Position Sizing Matrix
Risk Assessment: Current risk level and raw EVAR value
Position Recommendations: Percentage allocation, dollar value, and quantity
Stop Parameters: Mathematically derived stop price with percentage distance
Drawdown Projection: Maximum theoretical loss if stop is triggered
Interpretation and Application
The normalized EVAR reading provides a probabilistic risk assessment:
< 0.3: Low risk environment with minimal tail concerns
0.3-0.5: Moderate risk with standard tail behavior
0.5-0.7: Elevated risk with increased probability of significant moves
> 0.7: High risk environment with substantial tail risk present
Position sizing is automatically calculated using an inverse relationship to EVAR, contracting during high-risk periods and expanding during low-risk conditions. This is a counter-cyclical approach that ensures consistent risk exposure across varying market regimes, especially when the market is hyped or overheated.
Parameter Optimization
For optimal risk assessment across market conditions:
Lookback Period: Determines the historical window for risk calculation
Q Parameter: Controls tail sensitivity (higher values increase conservatism)
Confidence Level: Sets the statistical threshold for risk assessment
For cryptocurrencies and highly volatile instruments, a q-parameter between 1.5-2.0 typically provides the most accurate risk assessment because it helps capturing the fat-tailed behavior characteristic of these markets. You can also increase the q-parameter for more conservative approaches.
Practical Applications
Adaptive Risk Management: Quantify and respond to changing tail risk conditions
Volatility-Normalized Positioning: Maintain consistent exposure across market regimes
Black Swan Detection: Early identification of potential extreme market conditions
Portfolio Construction: Apply consistent risk-based sizing across diverse instruments
This indicator is my own approach to entropy-based risk measures as an alterative to volatility and standard deviations and it helps with fat-tailed markets.
Enjoy!
