Machine Learning: Lorentzian Classification█ OVERVIEW
A Lorentzian Distance Classifier (LDC) is a Machine Learning classification algorithm capable of categorizing historical data from a multi-dimensional feature space. This indicator demonstrates how Lorentzian Classification can also be used to predict the direction of future price movements when used as the distance metric for a novel implementation of an Approximate Nearest Neighbors (ANN) algorithm.
█ BACKGROUND
In physics, Lorentzian space is perhaps best known for its role in describing the curvature of space-time in Einstein's theory of General Relativity (2). Interestingly, however, this abstract concept from theoretical physics also has tangible real-world applications in trading.
Recently, it was hypothesized that Lorentzian space was also well-suited for analyzing time-series data (4), (5). This hypothesis has been supported by several empirical studies that demonstrate that Lorentzian distance is more robust to outliers and noise than the more commonly used Euclidean distance (1), (3), (6). Furthermore, Lorentzian distance was also shown to outperform dozens of other highly regarded distance metrics, including Manhattan distance, Bhattacharyya similarity, and Cosine similarity (1), (3). Outside of Dynamic Time Warping based approaches, which are unfortunately too computationally intensive for PineScript at this time, the Lorentzian Distance metric consistently scores the highest mean accuracy over a wide variety of time series data sets (1).
Euclidean distance is commonly used as the default distance metric for NN-based search algorithms, but it may not always be the best choice when dealing with financial market data. This is because financial market data can be significantly impacted by proximity to major world events such as FOMC Meetings and Black Swan events. This event-based distortion of market data can be framed as similar to the gravitational warping caused by a massive object on the space-time continuum. For financial markets, the analogous continuum that experiences warping can be referred to as "price-time".
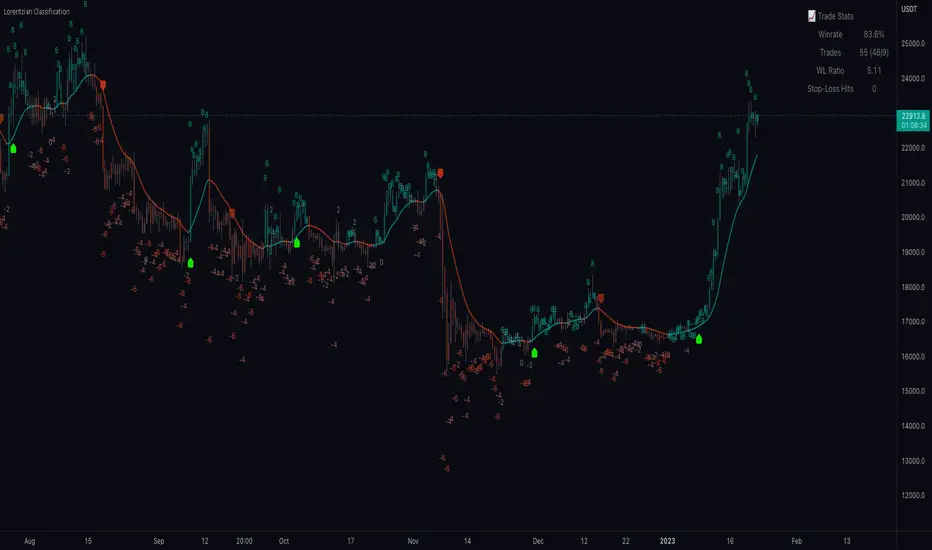
Below is a side-by-side comparison of how neighborhoods of similar historical points appear in three-dimensional Euclidean Space and Lorentzian Space:
This figure demonstrates how Lorentzian space can better accommodate the warping of price-time since the Lorentzian distance function compresses the Euclidean neighborhood in such a way that the new neighborhood distribution in Lorentzian space tends to cluster around each of the major feature axes in addition to the origin itself. This means that, even though some nearest neighbors will be the same regardless of the distance metric used, Lorentzian space will also allow for the consideration of historical points that would otherwise never be considered with a Euclidean distance metric.
Intuitively, the advantage inherent in the Lorentzian distance metric makes sense. For example, it is logical that the price action that occurs in the hours after Chairman Powell finishes delivering a speech would resemble at least some of the previous times when he finished delivering a speech. This may be true regardless of other factors, such as whether or not the market was overbought or oversold at the time or if the macro conditions were more bullish or bearish overall. These historical reference points are extremely valuable for predictive models, yet the Euclidean distance metric would miss these neighbors entirely, often in favor of irrelevant data points from the day before the event. By using Lorentzian distance as a metric, the ML model is instead able to consider the warping of price-time caused by the event and, ultimately, transcend the temporal bias imposed on it by the time series.
For more information on the implementation details of the Approximate Nearest Neighbors (ANN) algorithm used in this indicator, please refer to the detailed comments in the source code.
█ HOW TO USE
Below is an explanatory breakdown of the different parts of this indicator as it appears in the interface:
Below is an explanation of the different settings for this indicator:
General Settings:
Source - This has a default value of "hlc3" and is used to control the input data source.
Neighbors Count - This has a default value of 8, a minimum value of 1, a maximum value of 100, and a step of 1. It is used to control the number of neighbors to consider.
Max Bars Back - This has a default value of 2000.
Feature Count - This has a default value of 5, a minimum value of 2, and a maximum value of 5. It controls the number of features to use for ML predictions.
Color Compression - This has a default value of 1, a minimum value of 1, and a maximum value of 10. It is used to control the compression factor for adjusting the intensity of the color scale.
Show Exits - This has a default value of false. It controls whether to show the exit threshold on the chart.
Use Dynamic Exits - This has a default value of false. It is used to control whether to attempt to let profits ride by dynamically adjusting the exit threshold based on kernel regression.
Feature Engineering Settings:
Note: The Feature Engineering section is for fine-tuning the features used for ML predictions. The default values are optimized for the 4H to 12H timeframes for most charts, but they should also work reasonably well for other timeframes. By default, the model can support features that accept two parameters (Parameter A and Parameter B, respectively). Even though there are only 4 features provided by default, the same feature with different settings counts as two separate features. If the feature only accepts one parameter, then the second parameter will default to EMA-based smoothing with a default value of 1. These features represent the most effective combination I have encountered in my testing, but additional features may be added as additional options in the future.
Feature 1 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 2 - This has a default value of "WT" and options are: "RSI", "WT", "CCI", "ADX".
Feature 3 - This has a default value of "CCI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 4 - This has a default value of "ADX" and options are: "RSI", "WT", "CCI", "ADX".
Feature 5 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Filters Settings:
Use Volatility Filter - This has a default value of true. It is used to control whether to use the volatility filter.
Use Regime Filter - This has a default value of true. It is used to control whether to use the trend detection filter.
Use ADX Filter - This has a default value of false. It is used to control whether to use the ADX filter.
Regime Threshold - This has a default value of -0.1, a minimum value of -10, a maximum value of 10, and a step of 0.1. It is used to control the Regime Detection filter for detecting Trending/Ranging markets.
ADX Threshold - This has a default value of 20, a minimum value of 0, a maximum value of 100, and a step of 1. It is used to control the threshold for detecting Trending/Ranging markets.
Kernel Regression Settings:
Trade with Kernel - This has a default value of true. It is used to control whether to trade with the kernel.
Show Kernel Estimate - This has a default value of true. It is used to control whether to show the kernel estimate.
Lookback Window - This has a default value of 8 and a minimum value of 3. It is used to control the number of bars used for the estimation. Recommended range: 3-50
Relative Weighting - This has a default value of 8 and a step size of 0.25. It is used to control the relative weighting of time frames. Recommended range: 0.25-25
Start Regression at Bar - This has a default value of 25. It is used to control the bar index on which to start regression. Recommended range: 0-25
Display Settings:
Show Bar Colors - This has a default value of true. It is used to control whether to show the bar colors.
Show Bar Prediction Values - This has a default value of true. It controls whether to show the ML model's evaluation of each bar as an integer.
Use ATR Offset - This has a default value of false. It controls whether to use the ATR offset instead of the bar prediction offset.
Bar Prediction Offset - This has a default value of 0 and a minimum value of 0. It is used to control the offset of the bar predictions as a percentage from the bar high or close.
Backtesting Settings:
Show Backtest Results - This has a default value of true. It is used to control whether to display the win rate of the given configuration.
█ WORKS CITED
(1) R. Giusti and G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, and H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems," Pattern Recognition Letters, vol. 84, 170–176, Dec. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, and J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms." ResearchGate, Feb. 04, 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, and Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov and H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al., "Effects of Distance Measure Choice on KNN Classifier Performance - A Review." .
█ ACKNOWLEDGEMENTS
@veryfid - For many invaluable insights, discussions, and advice that helped to shape this project.
@capissimo - For open sourcing his interesting ideas regarding various KNN implementations in PineScript, several of which helped inspire my original undertaking of this project.
@RikkiTavi - For many invaluable physics-related conversations and for his helping me develop a mechanism for visualizing various distance algorithms in 3D using JavaScript
@jlaurel - For invaluable literature recommendations that helped me to understand the underlying subject matter of this project.
@annutara - For help in beta-testing this indicator and for sharing many helpful ideas and insights early on in its development.
@jasontaylor7 - For helping to beta-test this indicator and for many helpful conversations that helped to shape my backtesting workflow
@meddymarkusvanhala - For helping to beta-test this indicator
@dlbnext - For incredibly detailed backtesting testing of this indicator and for sharing numerous ideas on how the user experience could be improved.
Поиск скриптов по запросу "algo"
Adaptive MA constructor [lastguru]Adaptive Moving Averages are nothing new, however most of them use EMA as their MA of choice once the preferred smoothing length is determined. I have decided to make an experiment and separate length generation from smoothing, offering multiple alternatives to be combined. Some of the combinations are widely known, some are not. This indicator is based on my previously published public libraries and also serve as a usage demonstration for them. I will try to expand the collection (suggestions are welcome), however it is not meant as an encyclopaedic resource, so you are encouraged to experiment yourself: by looking on the source code of this indicator, I am sure you will see how trivial it is to use the provided libraries and expand them with your own ideas and combinations. I give no recommendation on what settings to use, but if you find some useful setting, combination or application ideas (or bugs in my code), I would be happy to read about them in the comments section.
The indicator works in three stages: Prefiltering, Length Adaptation and Moving Averages.
Prefiltering is a fast smoothing to get rid of high-frequency (2, 3 or 4 bar) noise.
Adaptation algorithms are roughly subdivided in two categories: classic Length Adaptations and Cycle Estimators (they are also implemented in separate libraries), all are selected in Adaptation dropdown. Length Adaptation used in the Adaptive Moving Averages and the Adaptive Oscillators try to follow price movements and accelerate/decelerate accordingly (usually quite rapidly with a huge range). Cycle Estimators, on the other hand, try to measure the cycle period of the current market, which does not reflect price movement or the rate of change (the rate of change may also differ depending on the cycle phase, but the cycle period itself usually changes slowly).
Chande (Price) - based on Chande's Dynamic Momentum Index (CDMI or DYMOI), which is dynamic RSI with this length
Chande (Volume) - a variant of Chande's algorithm, where volume is used instead of price
VIDYA - based on VIDYA algorithm. The period oscillates from the Lower Bound up (slow)
VIDYA-RS - based on Vitali Apirine's modification of VIDYA algorithm (he calls it Relative Strength Moving Average). The period oscillates from the Upper Bound down (fast)
Kaufman Efficiency Scaling - based on Efficiency Ratio calculation originally used in KAMA
Deviation Scaling - based on DSSS by John F. Ehlers
Median Average - based on Median Average Adaptive Filter by John F. Ehlers
Fractal Adaptation - based on FRAMA by John F. Ehlers
MESA MAMA Alpha - based on MESA Adaptive Moving Average by John F. Ehlers
MESA MAMA Cycle - based on MESA Adaptive Moving Average by John F. Ehlers, but unlike Alpha calculation, this adaptation estimates cycle period
Pearson Autocorrelation* - based on Pearson Autocorrelation Periodogram by John F. Ehlers
DFT Cycle* - based on Discrete Fourier Transform Spectrum estimator by John F. Ehlers
Phase Accumulation* - based on Dominant Cycle from Phase Accumulation by John F. Ehlers
Length Adaptation usually take two parameters: Bound From (lower bound) and To (upper bound). These are the limits for Adaptation values. Note that the Cycle Estimators marked with asterisks(*) are very computationally intensive, so the bounds should not be set much higher than 50, otherwise you may receive a timeout error (also, it does not seem to be a useful thing to do, but you may correct me if I'm wrong).
The Cycle Estimators marked with asterisks(*) also have 3 checkboxes: HP (Highpass Filter), SS (Super Smoother) and HW (Hann Window). These enable or disable their internal prefilters, which are recommended by their author - John F. Ehlers. I do not know, which combination works best, so you can experiment.
Chande's Adaptations also have 3 additional parameters: SD Length (lookback length of Standard deviation), Smooth (smoothing length of Standard deviation) and Power (exponent of the length adaptation - lower is smaller variation). These are internal tweaks for the calculation.
Length Adaptaton section offer you a choice of Moving Average algorithms. Most of the Adaptations are originally used with EMA, so this is a good starting point for exploration.
SMA - Simple Moving Average
RMA - Running Moving Average
EMA - Exponential Moving Average
HMA - Hull Moving Average
VWMA - Volume Weighted Moving Average
2-pole Super Smoother - 2-pole Super Smoother by John F. Ehlers
3-pole Super Smoother - 3-pole Super Smoother by John F. Ehlers
Filt11 -a variant of 2-pole Super Smoother with error averaging for zero-lag response by John F. Ehlers
Triangle Window - Triangle Window Filter by John F. Ehlers
Hamming Window - Hamming Window Filter by John F. Ehlers
Hann Window - Hann Window Filter by John F. Ehlers
Lowpass - removes cyclic components shorter than length (Price - Highpass)
DSSS - Derivation Scaled Super Smoother by John F. Ehlers
There are two Moving Averages that are drown on the chart, so length for both needs to be selected. If no Adaptation is selected ( None option), you can set Fast Length and Slow Length directly. If an Adaptation is selected, then Cycle multiplier can be selected for Fast and Slow MA.
More information on the algorithms is given in the code for the libraries used. I am also very grateful to other TradingView community members (they are also mentioned in the library code) without whom this script would not have been possible.

Exotic SMA Explorations Treasure TroveThis is my "Exotic SMA Explorations Treasure Trove" intended for educational purposes, yet these functions will also have utility in special applications with other algorithms. Firstly, the Pine built-in sma() is exceedingly more efficient computationally on TV servers than these functions will be. I just wanted to make that very crystal clear. My notes elaborate on this in the code blatantly.
Anyhow, the simple moving average(SMA) is one of the most common averaging filters used in a wide variety of algorithms. "Simply put," it's name says a lot about it. The purpose of this script, is to demonstrate variations of it's calculation in a multitude of exotic forms. In certain scenarios our algorithms may require a specific mathemagical touch that is pertinent to our intended goals. Like screwdrivers, we often need different types depending on the objective we are trying to attain. The SMA also serves as the most basic of finite impulse response(FIR) algorithms. For example, things like weighted moving averages can be constructed by using the foundational code of SMA.
One other intended demonstration of this script, is running multiple functions for comparison. I have had to use this from time to time for my own comparisons of performance. Also, imbedded into this code is a method to generically and recklessly in this case, adapt an algorithm. I will warn you, RSI was NEVER intended to adapt an algorithm. It only serves as a crude method to display the versatility of these different algorithms, whether it be a benefit or hinderance concerning dynamic adaptability.
Lastly, this script shows the versatility of TV's NEW additions input(group=) and input(inline=) upgrades in action. The "Immense Power of Pine" is always evolving and will continue to do so, I assure you of that. We can now categorize our input()s without using the input(type=input.bool) hackTrick. Although, that still will have it's enduring versatility, at least for myself.
NOTICE: You have absolute freedom to use this source code any way you see fit within your new Pine projects. You don't have to ask for my permission to reuse these functions in your published scripts, simply because I have better things to do than answer requests for the reuse of these functions. Sufficient accreditation regarding this script and compliance with "TV's House Rules" regarding code reuse, is as easy as copying the functions in their entirety as is. Fair enough? Good!
When available time provides itself, I will consider your inquiries, thoughts, and concepts presented below in the comments section, should you have any questions or comments regarding this indicator. When my indicators achieve more prevalent use by TV members, I may implement more ideas when they present themselves as worthy additions. Have a profitable future everyone!
Adaptive Genesis Engine [AGE]ADAPTIVE GENESIS ENGINE (AGE)
Pure Signal Evolution Through Genetic Algorithms
Where Darwin Meets Technical Analysis
🧬 WHAT YOU'RE GETTING - THE PURE INDICATOR
This is a technical analysis indicator - it generates signals, visualizes probability, and shows you the evolutionary process in real-time. This is NOT a strategy with automatic execution - it's a sophisticated signal generation system that you control .
What This Indicator Does:
Generates Long/Short entry signals with probability scores (35-88% range)
Evolves a population of up to 12 competing strategies using genetic algorithms
Validates strategies through walk-forward optimization (train/test cycles)
Visualizes signal quality through premium gradient clouds and confidence halos
Displays comprehensive metrics via enhanced dashboard
Provides alerts for entries and exits
Works on any timeframe, any instrument, any broker
What This Indicator Does NOT Do:
Execute trades automatically
Manage positions or calculate position sizes
Place orders on your behalf
Make trading decisions for you
This is pure signal intelligence. AGE tells you when and how confident it is. You decide whether and how much to trade.
🔬 THE SCIENCE: GENETIC ALGORITHMS MEET TECHNICAL ANALYSIS
What Makes This Different - The Evolutionary Foundation
Most indicators are static - they use the same parameters forever, regardless of market conditions. AGE is alive . It maintains a population of competing strategies that evolve, adapt, and improve through natural selection principles:
Birth: New strategies spawn through crossover breeding (combining DNA from fit parents) plus random mutation for exploration
Life: Each strategy trades virtually via shadow portfolios, accumulating wins/losses, tracking drawdown, and building performance history
Selection: Strategies are ranked by comprehensive fitness scoring (win rate, expectancy, drawdown control, signal efficiency)
Death: Weak strategies are culled periodically, with elite performers (top 2 by default) protected from removal
Evolution: The gene pool continuously improves as successful traits propagate and unsuccessful ones die out
This is not curve-fitting. Each new strategy must prove itself on out-of-sample data through walk-forward validation before being trusted for live signals.
🧪 THE DNA: WHAT EVOLVES
Every strategy carries a 10-gene chromosome controlling how it interprets market data:
Signal Sensitivity Genes
Entropy Sensitivity (0.5-2.0): Weight given to market order/disorder calculations. Low values = conservative, require strong directional clarity. High values = aggressive, act on weaker order signals.
Momentum Sensitivity (0.5-2.0): Weight given to RSI/ROC/MACD composite. Controls responsiveness to momentum shifts vs. mean-reversion setups.
Structure Sensitivity (0.5-2.0): Weight given to support/resistance positioning. Determines how much price location within swing range matters.
Probability Adjustment Genes
Probability Boost (-0.10 to +0.10): Inherent bias toward aggressive (+) or conservative (-) entries. Acts as personality trait - some strategies naturally optimistic, others pessimistic.
Trend Strength Requirement (0.3-0.8): Minimum trend conviction needed before signaling. Higher values = only trades strong trends, lower values = acts in weak/sideways markets.
Volume Filter (0.5-1.5): Strictness of volume confirmation. Higher values = requires strong volume, lower values = volume less important.
Risk Management Genes
ATR Multiplier (1.5-4.0): Base volatility scaling for all price levels. Controls whether strategy uses tight or wide stops/targets relative to ATR.
Stop Multiplier (1.0-2.5): Stop loss tightness. Lower values = aggressive profit protection, higher values = more breathing room.
Target Multiplier (1.5-4.0): Profit target ambition. Lower values = quick scalping exits, higher values = swing trading holds.
Adaptation Gene
Regime Adaptation (0.0-1.0): How much strategy adjusts behavior based on detected market regime (trending/volatile/choppy). Higher values = more reactive to regime changes.
The Magic: AGE doesn't just try random combinations. Through tournament selection and fitness-weighted crossover, successful gene combinations spread through the population while unsuccessful ones fade away. Over 50-100 bars, you'll see the population converge toward genes that work for YOUR instrument and timeframe.
📊 THE SIGNAL ENGINE: THREE-LAYER SYNTHESIS
Before any strategy generates a signal, AGE calculates probability through multi-indicator confluence:
Layer 1 - Market Entropy (Information Theory)
Measures whether price movements exhibit directional order or random walk characteristics:
The Math:
Shannon Entropy = -Σ(p × log(p))
Market Order = 1 - (Entropy / 0.693)
What It Means:
High entropy = choppy, random market → low confidence signals
Low entropy = directional market → high confidence signals
Direction determined by up-move vs down-move dominance over lookback period (default: 20 bars)
Signal Output: -1.0 to +1.0 (bearish order to bullish order)
Layer 2 - Momentum Synthesis
Combines three momentum indicators into single composite score:
Components:
RSI (40% weight): Normalized to -1/+1 scale using (RSI-50)/50
Rate of Change (30% weight): Percentage change over lookback (default: 14 bars), clamped to ±1
MACD Histogram (30% weight): Fast(12) - Slow(26), normalized by ATR
Why This Matters: RSI catches mean-reversion opportunities, ROC catches raw momentum, MACD catches momentum divergence. Weighting favors RSI for reliability while keeping other perspectives.
Signal Output: -1.0 to +1.0 (strong bearish to strong bullish)
Layer 3 - Structure Analysis
Evaluates price position within swing range (default: 50-bar lookback):
Position Classification:
Bottom 20% of range = Support Zone → bullish bounce potential
Top 20% of range = Resistance Zone → bearish rejection potential
Middle 60% = Neutral Zone → breakout/breakdown monitoring
Signal Logic:
At support + bullish candle = +0.7 (strong buy setup)
At resistance + bearish candle = -0.7 (strong sell setup)
Breaking above range highs = +0.5 (breakout confirmation)
Breaking below range lows = -0.5 (breakdown confirmation)
Consolidation within range = ±0.3 (weak directional bias)
Signal Output: -1.0 to +1.0 (bearish structure to bullish structure)
Confluence Voting System
Each layer casts a vote (Long/Short/Neutral). The system requires minimum 2-of-3 agreement (configurable 1-3) before generating a signal:
Examples:
Entropy: Bullish, Momentum: Bullish, Structure: Neutral → Signal generated (2 long votes)
Entropy: Bearish, Momentum: Neutral, Structure: Neutral → No signal (only 1 short vote)
All three bullish → Signal generated with +5% probability bonus
This is the key to quality. Single indicators give too many false signals. Triple confirmation dramatically improves accuracy.
📈 PROBABILITY CALCULATION: HOW CONFIDENCE IS MEASURED
Base Probability:
Raw_Prob = 50% + (Average_Signal_Strength × 25%)
Then AGE applies strategic adjustments:
Trend Alignment:
Signal with trend: +4%
Signal against strong trend: -8%
Weak/no trend: no adjustment
Regime Adaptation:
Trending market (efficiency >50%, moderate vol): +3%
Volatile market (vol ratio >1.5x): -5%
Choppy market (low efficiency): -2%
Volume Confirmation:
Volume > 70% of 20-bar SMA: no change
Volume below threshold: -3%
Volatility State (DVS Ratio):
High vol (>1.8x baseline): -4% (reduce confidence in chaos)
Low vol (<0.7x baseline): -2% (markets can whipsaw in compression)
Moderate elevated vol (1.0-1.3x): +2% (trending conditions emerging)
Confluence Bonus:
All 3 indicators agree: +5%
2 of 3 agree: +2%
Strategy Gene Adjustment:
Probability Boost gene: -10% to +10%
Regime Adaptation gene: scales regime adjustments by 0-100%
Final Probability: Clamped between 35% (minimum) and 88% (maximum)
Why These Ranges?
Below 35% = too uncertain, better not to signal
Above 88% = unrealistic, creates overconfidence
Sweet spot: 65-80% for quality entries
🔄 THE SHADOW PORTFOLIO SYSTEM: HOW STRATEGIES COMPETE
Each active strategy maintains a virtual trading account that executes in parallel with real-time data:
Shadow Trading Mechanics
Entry Logic:
Calculate signal direction, probability, and confluence using strategy's unique DNA
Check if signal meets quality gate:
Probability ≥ configured minimum threshold (default: 65%)
Confluence ≥ configured minimum (default: 2 of 3)
Direction is not zero (must be long or short, not neutral)
Verify signal persistence:
Base requirement: 2 bars (configurable 1-5)
Adapts based on probability: high-prob signals (75%+) enter 1 bar faster, low-prob signals need 1 bar more
Adjusts for regime: trending markets reduce persistence by 1, volatile markets add 1
Apply additional filters:
Trend strength must exceed strategy's requirement gene
Regime filter: if volatile market detected, probability must be 72%+ to override
Volume confirmation required (volume > 70% of average)
If all conditions met for required persistence bars, enter shadow position at current close price
Position Management:
Entry Price: Recorded at close of entry bar
Stop Loss: ATR-based distance = ATR × ATR_Mult (gene) × Stop_Mult (gene) × DVS_Ratio
Take Profit: ATR-based distance = ATR × ATR_Mult (gene) × Target_Mult (gene) × DVS_Ratio
Position: +1 (long) or -1 (short), only one at a time per strategy
Exit Logic:
Check if price hit stop (on low) or target (on high) on current bar
Record trade outcome in R-multiples (profit/loss normalized by ATR)
Update performance metrics:
Total trades counter incremented
Wins counter (if profit > 0)
Cumulative P&L updated
Peak equity tracked (for drawdown calculation)
Maximum drawdown from peak recorded
Enter cooldown period (default: 8 bars, configurable 3-20) before next entry allowed
Reset signal age counter to zero
Walk-Forward Tracking:
During position lifecycle, trades are categorized:
Training Phase (first 250 bars): Trade counted toward training metrics
Testing Phase (next 75 bars): Trade counted toward testing metrics (out-of-sample)
Live Phase (after WFO period): Trade counted toward overall metrics
Why Shadow Portfolios?
No lookahead bias (uses only data available at the bar)
Realistic execution simulation (entry on close, stop/target checks on high/low)
Independent performance tracking for true fitness comparison
Allows safe experimentation without risking capital
Each strategy learns from its own experience
🏆 FITNESS SCORING: HOW STRATEGIES ARE RANKED
Fitness is not just win rate. AGE uses a comprehensive multi-factor scoring system:
Core Metrics (Minimum 3 trades required)
Win Rate (30% of fitness):
WinRate = Wins / TotalTrades
Normalized directly (0.0-1.0 scale)
Total P&L (30% of fitness):
Normalized_PnL = (PnL + 300) / 600
Clamped 0.0-1.0. Assumes P&L range of -300R to +300R for normalization scale.
Expectancy (25% of fitness):
Expectancy = Total_PnL / Total_Trades
Normalized_Expectancy = (Expectancy + 30) / 60
Clamped 0.0-1.0. Rewards consistency of profit per trade.
Drawdown Control (15% of fitness):
Normalized_DD = 1 - (Max_Drawdown / 15)
Clamped 0.0-1.0. Penalizes strategies that suffer large equity retracements from peak.
Sample Size Adjustment
Quality Factor:
<50 trades: 1.0 (full weight, small sample)
50-100 trades: 0.95 (slight penalty for medium sample)
100 trades: 0.85 (larger penalty for large sample)
Why penalize more trades? Prevents strategies from gaming the system by taking hundreds of tiny trades to inflate statistics. Favors quality over quantity.
Bonus Adjustments
Walk-Forward Validation Bonus:
if (WFO_Validated):
Fitness += (WFO_Efficiency - 0.5) × 0.1
Strategies proven on out-of-sample data receive up to +10% fitness boost based on test/train efficiency ratio.
Signal Efficiency Bonus (if diagnostics enabled):
if (Signals_Evaluated > 10):
Pass_Rate = Signals_Passed / Signals_Evaluated
Fitness += (Pass_Rate - 0.1) × 0.05
Rewards strategies that generate high-quality signals passing the quality gate, not just profitable trades.
Final Fitness: Clamped at 0.0 minimum (prevents negative fitness values)
Result: Elite strategies typically achieve 0.50-0.75 fitness. Anything above 0.60 is excellent. Below 0.30 is prime candidate for culling.
🔬 WALK-FORWARD OPTIMIZATION: ANTI-OVERFITTING PROTECTION
This is what separates AGE from curve-fitted garbage indicators.
The Three-Phase Process
Every new strategy undergoes a rigorous validation lifecycle:
Phase 1 - Training Window (First 250 bars, configurable 100-500):
Strategy trades normally via shadow portfolio
All trades count toward training performance metrics
System learns which gene combinations produce profitable patterns
Tracks independently: Training_Trades, Training_Wins, Training_PnL
Phase 2 - Testing Window (Next 75 bars, configurable 30-200):
Strategy continues trading without any parameter changes
Trades now count toward testing performance metrics (separate tracking)
This is out-of-sample data - strategy has never seen these bars during "optimization"
Tracks independently: Testing_Trades, Testing_Wins, Testing_PnL
Phase 3 - Validation Check:
Minimum_Trades = 5 (configurable 3-15)
IF (Train_Trades >= Minimum AND Test_Trades >= Minimum):
WR_Efficiency = Test_WinRate / Train_WinRate
Expectancy_Efficiency = Test_Expectancy / Train_Expectancy
WFO_Efficiency = (WR_Efficiency + Expectancy_Efficiency) / 2
IF (WFO_Efficiency >= 0.55): // configurable 0.3-0.9
Strategy.Validated = TRUE
Strategy receives fitness bonus
ELSE:
Strategy receives 30% fitness penalty
ELSE:
Validation deferred (insufficient trades in one or both periods)
What Validation Means
Validated Strategy (Green "✓ VAL" in dashboard):
Performed at least 55% as well on unseen data compared to training data
Gets fitness bonus: +(efficiency - 0.5) × 0.1
Receives priority during tournament selection for breeding
More likely to be chosen as active trading strategy
Unvalidated Strategy (Orange "○ TRAIN" in dashboard):
Failed to maintain performance on test data (likely curve-fitted to training period)
Receives 30% fitness penalty (0.7x multiplier)
Makes strategy prime candidate for culling
Can still trade but with lower selection probability
Insufficient Data (continues collecting):
Hasn't completed both training and testing periods yet
OR hasn't achieved minimum trade count in both periods
Validation check deferred until requirements met
Why 55% Efficiency Threshold?
If a strategy earned 10R during training but only 5.5R during testing, it still proved an edge exists beyond random luck. Requiring 100% efficiency would be unrealistic - market conditions change between periods. But requiring >50% ensures the strategy didn't completely degrade on fresh data.
The Protection: Strategies that work great on historical data but fail on new data are automatically identified and penalized. This prevents the population from being polluted by overfitted strategies that would fail in live trading.
🌊 DYNAMIC VOLATILITY SCALING (DVS): ADAPTIVE STOP/TARGET PLACEMENT
AGE doesn't use fixed stop distances. It adapts to current volatility conditions in real-time.
Four Volatility Measurement Methods
1. ATR Ratio (Simple Method):
Current_Vol = ATR(14) / Close
Baseline_Vol = SMA(Current_Vol, 100)
Ratio = Current_Vol / Baseline_Vol
Basic comparison of current ATR to 100-bar moving average baseline.
2. Parkinson (High-Low Range Based):
For each bar: HL = log(High / Low)
Parkinson_Vol = sqrt(Σ(HL²) / (4 × Period × log(2)))
More stable than close-to-close volatility. Captures intraday range expansion without overnight gap noise.
3. Garman-Klass (OHLC Based):
HL_Term = 0.5 × ²
CO_Term = (2×log(2) - 1) × ²
GK_Vol = sqrt(Σ(HL_Term - CO_Term) / Period)
Most sophisticated estimator. Incorporates all four price points (open, high, low, close) plus gap information.
4. Ensemble Method (Default - Median of All Three):
Ratio_1 = ATR_Current / ATR_Baseline
Ratio_2 = Parkinson_Current / Parkinson_Baseline
Ratio_3 = GK_Current / GK_Baseline
DVS_Ratio = Median(Ratio_1, Ratio_2, Ratio_3)
Why Ensemble?
Takes median to avoid outliers and false spikes
If ATR jumps but range-based methods stay calm, median prevents overreaction
If one method fails, other two compensate
Most robust approach across different market conditions
Sensitivity Scaling
Scaled_Ratio = (Raw_Ratio) ^ Sensitivity
Sensitivity 0.3: Cube root - heavily dampens volatility impact
Sensitivity 0.5: Square root - moderate dampening
Sensitivity 0.7 (Default): Balanced response to volatility changes
Sensitivity 1.0: Linear - full 1:1 volatility impact
Sensitivity 1.5: Exponential - amplified response to volatility spikes
Safety Clamps: Final DVS Ratio always clamped between 0.5x and 2.5x baseline to prevent extreme position sizing or stop placement errors.
How DVS Affects Shadow Trading
Every strategy's stop and target distances are multiplied by the current DVS ratio:
Stop Loss Distance:
Stop_Distance = ATR × ATR_Mult (gene) × Stop_Mult (gene) × DVS_Ratio
Take Profit Distance:
Target_Distance = ATR × ATR_Mult (gene) × Target_Mult (gene) × DVS_Ratio
Example Scenario:
ATR = 10 points
Strategy's ATR_Mult gene = 2.5
Strategy's Stop_Mult gene = 1.5
Strategy's Target_Mult gene = 2.5
DVS_Ratio = 1.4 (40% above baseline volatility - market heating up)
Stop = 10 × 2.5 × 1.5 × 1.4 = 52.5 points (vs. 37.5 in normal vol)
Target = 10 × 2.5 × 2.5 × 1.4 = 87.5 points (vs. 62.5 in normal vol)
Result:
During volatility spikes: Stops automatically widen to avoid noise-based exits, targets extend for bigger moves
During calm periods: Stops tighten for better risk/reward, targets compress for realistic profit-taking
Strategies adapt risk management to match current market behavior
🧬 THE EVOLUTIONARY CYCLE: SPAWN, COMPETE, CULL
Initialization (Bar 1)
AGE begins with 4 seed strategies (if evolution enabled):
Seed Strategy #0 (Balanced):
All sensitivities at 1.0 (neutral)
Zero probability boost
Moderate trend requirement (0.4)
Standard ATR/stop/target multiples (2.5/1.5/2.5)
Mid-level regime adaptation (0.5)
Seed Strategy #1 (Momentum-Focused):
Lower entropy sensitivity (0.7), higher momentum (1.5)
Slight probability boost (+0.03)
Higher trend requirement (0.5)
Tighter stops (1.3), wider targets (3.0)
Seed Strategy #2 (Entropy-Driven):
Higher entropy sensitivity (1.5), lower momentum (0.8)
Slight probability penalty (-0.02)
More trend tolerant (0.6)
Wider stops (1.8), standard targets (2.5)
Seed Strategy #3 (Structure-Based):
Balanced entropy/momentum (0.8/0.9), high structure (1.4)
Slight probability boost (+0.02)
Lower trend requirement (0.35)
Moderate risk parameters (1.6/2.8)
All seeds start with WFO validation bypassed if WFO is disabled, or must validate if enabled.
Spawning New Strategies
Timing (Adaptive):
Historical phase: Every 30 bars (configurable 10-100)
Live phase: Every 200 bars (configurable 100-500)
Automatically switches to live timing when barstate.isrealtime triggers
Conditions:
Current population < max population limit (default: 8, configurable 4-12)
At least 2 active strategies exist (need parents)
Available slot in population array
Selection Process:
Run tournament selection 3 times with different seeds
Each tournament: randomly sample active strategies, pick highest fitness
Best from 3 tournaments becomes Parent 1
Repeat independently for Parent 2
Ensures fit parents but maintains diversity
Crossover Breeding:
For each of 10 genes:
Parent1_Fitness = fitness
Parent2_Fitness = fitness
Weight1 = Parent1_Fitness / (Parent1_Fitness + Parent2_Fitness)
Gene1 = parent1's value
Gene2 = parent2's value
Child_Gene = Weight1 × Gene1 + (1 - Weight1) × Gene2
Fitness-weighted crossover ensures fitter parent contributes more genetic material.
Mutation:
For each gene in child:
IF (random < mutation_rate):
Gene_Range = GENE_MAX - GENE_MIN
Noise = (random - 0.5) × 2 × mutation_strength × Gene_Range
Mutated_Gene = Clamp(Child_Gene + Noise, GENE_MIN, GENE_MAX)
Historical mutation rate: 20% (aggressive exploration)
Live mutation rate: 8% (conservative stability)
Mutation strength: 12% of gene range (configurable 5-25%)
Initialization of New Strategy:
Unique ID assigned (total_spawned counter)
Parent ID recorded
Generation = max(parent generations) + 1
Birth bar recorded (for age tracking)
All performance metrics zeroed
Shadow portfolio reset
WFO validation flag set to false (must prove itself)
Result: New strategy with hybrid DNA enters population, begins trading in next bar.
Competition (Every Bar)
All active strategies:
Calculate their signal based on unique DNA
Check quality gate with their thresholds
Manage shadow positions (entries/exits)
Update performance metrics
Recalculate fitness score
Track WFO validation progress
Strategies compete indirectly through fitness ranking - no direct interaction.
Culling Weak Strategies
Timing (Adaptive):
Historical phase: Every 60 bars (configurable 20-200, should be 2x spawn interval)
Live phase: Every 400 bars (configurable 200-1000, should be 2x spawn interval)
Minimum Adaptation Score (MAS):
Initial MAS = 0.10
MAS decays: MAS × 0.995 every cull cycle
Minimum MAS = 0.03 (floor)
MAS represents the "survival threshold" - strategies below this fitness level are vulnerable.
Culling Conditions (ALL must be true):
Population > minimum population (default: 3, configurable 2-4)
At least one strategy has fitness < MAS
Strategy's age > culling interval (prevents premature culling of new strategies)
Strategy is not in top N elite (default: 2, configurable 1-3)
Culling Process:
Find worst strategy:
For each active strategy:
IF (age > cull_interval):
Fitness = base_fitness
IF (not WFO_validated AND WFO_enabled):
Fitness × 0.7 // 30% penalty for unvalidated
IF (Fitness < MAS AND Fitness < worst_fitness_found):
worst_strategy = this_strategy
worst_fitness = Fitness
IF (worst_strategy found):
Count elite strategies with fitness > worst_fitness
IF (elite_count >= elite_preservation_count):
Deactivate worst_strategy (set active flag = false)
Increment total_culled counter
Elite Protection:
Even if a strategy's fitness falls below MAS, it survives if fewer than N strategies are better. This prevents culling when population is generally weak.
Result: Weak strategies removed from population, freeing slots for new spawns. Gene pool improves over time.
Selection for Display (Every Bar)
AGE chooses one strategy to display signals:
Best fitness = -1
Selected = none
For each active strategy:
Fitness = base_fitness
IF (WFO_validated):
Fitness × 1.3 // 30% bonus for validated strategies
IF (Fitness > best_fitness):
best_fitness = Fitness
selected_strategy = this_strategy
Display selected strategy's signals on chart
Result: Only the highest-fitness (optionally validated-boosted) strategy's signals appear as chart markers. Other strategies trade invisibly in shadow portfolios.
🎨 PREMIUM VISUALIZATION SYSTEM
AGE includes sophisticated visual feedback that standard indicators lack:
1. Gradient Probability Cloud (Optional, Default: ON)
Multi-layer gradient showing signal buildup 2-3 bars before entry:
Activation Conditions:
Signal persistence > 0 (same directional signal held for multiple bars)
Signal probability ≥ minimum threshold (65% by default)
Signal hasn't yet executed (still in "forming" state)
Visual Construction:
7 gradient layers by default (configurable 3-15)
Each layer is a line-fill pair (top line, bottom line, filled between)
Layer spacing: 0.3 to 1.0 × ATR above/below price
Outer layers = faint, inner layers = bright
Color transitions from base to intense based on layer position
Transparency scales with probability (high prob = more opaque)
Color Selection:
Long signals: Gradient from theme.gradient_bull_mid to theme.gradient_bull_strong
Short signals: Gradient from theme.gradient_bear_mid to theme.gradient_bear_strong
Base transparency: 92%, reduces by up to 8% for high-probability setups
Dynamic Behavior:
Cloud grows/shrinks as signal persistence increases/decreases
Redraws every bar while signal is forming
Disappears when signal executes or invalidates
Performance Note: Computationally expensive due to linefill objects. Disable or reduce layers if chart performance degrades.
2. Population Fitness Ribbon (Optional, Default: ON)
Histogram showing fitness distribution across active strategies:
Activation: Only draws on last bar (barstate.islast) to avoid historical clutter
Visual Construction:
10 histogram layers by default (configurable 5-20)
Plots 50 bars back from current bar
Positioned below price at: lowest_low(100) - 1.5×ATR (doesn't interfere with price action)
Each layer represents a fitness threshold (evenly spaced min to max fitness)
Layer Logic:
For layer_num from 0 to ribbon_layers:
Fitness_threshold = min_fitness + (max_fitness - min_fitness) × (layer / layers)
Count strategies with fitness ≥ threshold
Height = ATR × 0.15 × (count / total_active)
Y_position = base_level + ATR × 0.2 × layer
Color = Gradient from weak to strong based on layer position
Line_width = Scaled by height (taller = thicker)
Visual Feedback:
Tall, bright ribbon = healthy population, many fit strategies at high fitness levels
Short, dim ribbon = weak population, few strategies achieving good fitness
Ribbon compression (layers close together) = population converging to similar fitness
Ribbon spread = diverse fitness range, active selection pressure
Use Case: Quick visual health check without opening dashboard. Ribbon growing upward over time = population improving.
3. Confidence Halo (Optional, Default: ON)
Circular polyline around entry signals showing probability strength:
Activation: Draws when new position opens (shadow_position changes from 0 to ±1)
Visual Construction:
20-segment polyline forming approximate circle
Center: Low - 0.5×ATR (long) or High + 0.5×ATR (short)
Radius: 0.3×ATR (low confidence) to 1.0×ATR (elite confidence)
Scales with: (probability - min_probability) / (1.0 - min_probability)
Color Coding:
Elite (85%+): Cyan (theme.conf_elite), large radius, minimal transparency (40%)
Strong (75-85%): Strong green (theme.conf_strong), medium radius, moderate transparency (50%)
Good (65-75%): Good green (theme.conf_good), smaller radius, more transparent (60%)
Moderate (<65%): Moderate green (theme.conf_moderate), tiny radius, very transparent (70%)
Technical Detail:
Uses chart.point array with index-based positioning
5-bar horizontal spread for circular appearance (±5 bars from entry)
Curved=false (Pine Script polyline limitation)
Fill color matches line color but more transparent (88% vs line's transparency)
Purpose: Instant visual probability assessment. No need to check dashboard - halo size/brightness tells the story.
4. Evolution Event Markers (Optional, Default: ON)
Visual indicators of genetic algorithm activity:
Spawn Markers (Diamond, Cyan):
Plots when total_spawned increases on current bar
Location: bottom of chart (location.bottom)
Color: theme.spawn_marker (cyan/bright blue)
Size: tiny
Indicates new strategy just entered population
Cull Markers (X-Cross, Red):
Plots when total_culled increases on current bar
Location: bottom of chart (location.bottom)
Color: theme.cull_marker (red/pink)
Size: tiny
Indicates weak strategy just removed from population
What It Tells You:
Frequent spawning early = population building, active exploration
Frequent culling early = high selection pressure, weak strategies dying fast
Balanced spawn/cull = healthy evolutionary churn
No markers for long periods = stable population (evolution plateaued or optimal genes found)
5. Entry/Exit Markers
Clear visual signals for selected strategy's trades:
Long Entry (Triangle Up, Green):
Plots when selected strategy opens long position (position changes 0 → +1)
Location: below bar (location.belowbar)
Color: theme.long_primary (green/cyan depending on theme)
Transparency: Scales with probability:
Elite (85%+): 0% (fully opaque)
Strong (75-85%): 10%
Good (65-75%): 20%
Acceptable (55-65%): 35%
Size: small
Short Entry (Triangle Down, Red):
Plots when selected strategy opens short position (position changes 0 → -1)
Location: above bar (location.abovebar)
Color: theme.short_primary (red/pink depending on theme)
Transparency: Same scaling as long entries
Size: small
Exit (X-Cross, Orange):
Plots when selected strategy closes position (position changes ±1 → 0)
Location: absolute (at actual exit price if stop/target lines enabled)
Color: theme.exit_color (orange/yellow depending on theme)
Transparency: 0% (fully opaque)
Size: tiny
Result: Clean, probability-scaled markers that don't clutter chart but convey essential information.
6. Stop Loss & Take Profit Lines (Optional, Default: ON)
Visual representation of shadow portfolio risk levels:
Stop Loss Line:
Plots when selected strategy has active position
Level: shadow_stop value from selected strategy
Color: theme.short_primary with 60% transparency (red/pink, subtle)
Width: 2
Style: plot.style_linebr (breaks when no position)
Take Profit Line:
Plots when selected strategy has active position
Level: shadow_target value from selected strategy
Color: theme.long_primary with 60% transparency (green, subtle)
Width: 2
Style: plot.style_linebr (breaks when no position)
Purpose:
Shows where shadow portfolio would exit for stop/target
Helps visualize strategy's risk/reward ratio
Useful for manual traders to set similar levels
Disable for cleaner chart (recommended for presentations)
7. Dynamic Trend EMA
Gradient-colored trend line that visualizes trend strength:
Calculation:
EMA(close, trend_length) - default 50 period (configurable 20-100)
Slope calculated over 10 bars: (current_ema - ema ) / ema × 100
Color Logic:
Trend_direction:
Slope > 0.1% = Bullish (1)
Slope < -0.1% = Bearish (-1)
Otherwise = Neutral (0)
Trend_strength = abs(slope)
Color = Gradient between:
- Neutral color (gray/purple)
- Strong bullish (bright green) if direction = 1
- Strong bearish (bright red) if direction = -1
Gradient factor = trend_strength (0 to 1+ scale)
Visual Behavior:
Faint gray/purple = weak/no trend (choppy conditions)
Light green/red = emerging trend (low strength)
Bright green/red = strong trend (high conviction)
Color intensity = trend strength magnitude
Transparency: 50% (subtle, doesn't overpower price action)
Purpose: Subconscious awareness of trend state without checking dashboard or indicators.
8. Regime Background Tinting (Subtle)
Ultra-low opacity background color indicating detected market regime:
Regime Detection:
Efficiency = directional_movement / total_range (over trend_length bars)
Vol_ratio = current_volatility / average_volatility
IF (efficiency > 0.5 AND vol_ratio < 1.3):
Regime = Trending (1)
ELSE IF (vol_ratio > 1.5):
Regime = Volatile (2)
ELSE:
Regime = Choppy (0)
Background Colors:
Trending: theme.regime_trending (dark green, 92-93% transparency)
Volatile: theme.regime_volatile (dark red, 93% transparency)
Choppy: No tint (normal background)
Purpose:
Subliminal regime awareness
Helps explain why signals are/aren't generating
Trending = ideal conditions for AGE
Volatile = fewer signals, higher thresholds applied
Choppy = mixed signals, lower confidence
Important: Extremely subtle by design. Not meant to be obvious, just subconscious context.
📊 ENHANCED DASHBOARD
Comprehensive real-time metrics in single organized panel (top-right position):
Dashboard Structure (5 columns × 14 rows)
Header Row:
Column 0: "🧬 AGE PRO" + phase indicator (🔴 LIVE or ⏪ HIST)
Column 1: "POPULATION"
Column 2: "PERFORMANCE"
Column 3: "CURRENT SIGNAL"
Column 4: "ACTIVE STRATEGY"
Column 0: Market State
Regime (📈 TREND / 🌊 CHAOS / ➖ CHOP)
DVS Ratio (current volatility scaling factor, format: #.##)
Trend Direction (▲ BULL / ▼ BEAR / ➖ FLAT with color coding)
Trend Strength (0-100 scale, format: #.##)
Column 1: Population Metrics
Active strategies (count / max_population)
Validated strategies (WFO passed / active total)
Current generation number
Total spawned (all-time strategy births)
Total culled (all-time strategy deaths)
Column 2: Aggregate Performance
Total trades across all active strategies
Aggregate win rate (%) - color-coded:
Green (>55%)
Orange (45-55%)
Red (<45%)
Total P&L in R-multiples - color-coded by positive/negative
Best fitness score in population (format: #.###)
MAS - Minimum Adaptation Score (cull threshold, format: #.###)
Column 3: Current Signal Status
Status indicator:
"▲ LONG" (green) if selected strategy in long position
"▼ SHORT" (red) if selected strategy in short position
"⏳ FORMING" (orange) if signal persisting but not yet executed
"○ WAITING" (gray) if no active signal
Confidence percentage (0-100%, format: #.#%)
Quality assessment:
"🔥 ELITE" (cyan) for 85%+ probability
"✓ STRONG" (bright green) for 75-85%
"○ GOOD" (green) for 65-75%
"- LOW" (dim) for <65%
Confluence score (X/3 format)
Signal age:
"X bars" if signal forming
"IN TRADE" if position active
"---" if no signal
Column 4: Selected Strategy Details
Strategy ID number (#X format)
Validation status:
"✓ VAL" (green) if WFO validated
"○ TRAIN" (orange) if still in training/testing phase
Generation number (GX format)
Personal fitness score (format: #.### with color coding)
Trade count
P&L and win rate (format: #.#R (##%) with color coding)
Color Scheme:
Panel background: theme.panel_bg (dark, low opacity)
Panel headers: theme.panel_header (slightly lighter)
Primary text: theme.text_primary (bright, high contrast)
Secondary text: theme.text_secondary (dim, lower contrast)
Positive metrics: theme.metric_positive (green)
Warning metrics: theme.metric_warning (orange)
Negative metrics: theme.metric_negative (red)
Special markers: theme.validated_marker, theme.spawn_marker
Update Frequency: Only on barstate.islast (current bar) to minimize CPU usage
Purpose:
Quick overview of entire system state
No need to check multiple indicators
Trading decisions informed by population health, regime state, and signal quality
Transparency into what AGE is thinking
🔍 DIAGNOSTICS PANEL (Optional, Default: OFF)
Detailed signal quality tracking for optimization and debugging:
Panel Structure (3 columns × 8 rows)
Position: Bottom-right corner (doesn't interfere with main dashboard)
Header Row:
Column 0: "🔍 DIAGNOSTICS"
Column 1: "COUNT"
Column 2: "%"
Metrics Tracked (for selected strategy only):
Total Evaluated:
Every signal that passed initial calculation (direction ≠ 0)
Represents total opportunities considered
✓ Passed:
Signals that passed quality gate and executed
Green color coding
Percentage of evaluated signals
Rejection Breakdown:
⨯ Probability:
Rejected because probability < minimum threshold
Most common rejection reason typically
⨯ Confluence:
Rejected because confluence < minimum required (e.g., only 1 of 3 indicators agreed)
⨯ Trend:
Rejected because signal opposed strong trend
Indicates counter-trend protection working
⨯ Regime:
Rejected because volatile regime detected and probability wasn't high enough to override
Shows regime filter in action
⨯ Volume:
Rejected because volume < 70% of 20-bar average
Indicates volume confirmation requirement
Color Coding:
Passed count: Green (success metric)
Rejection counts: Red (failure metrics)
Percentages: Gray (neutral, informational)
Performance Cost: Slight CPU overhead for tracking counters. Disable when not actively optimizing settings.
How to Use Diagnostics
Scenario 1: Too Few Signals
Evaluated: 200
Passed: 10 (5%)
⨯ Probability: 120 (60%)
⨯ Confluence: 40 (20%)
⨯ Others: 30 (15%)
Diagnosis: Probability threshold too high for this strategy's DNA.
Solution: Lower min probability from 65% to 60%, or allow strategy more time to evolve better DNA.
Scenario 2: Too Many False Signals
Evaluated: 200
Passed: 80 (40%)
Strategy win rate: 45%
Diagnosis: Quality gate too loose, letting low-quality signals through.
Solution: Raise min probability to 70%, or increase min confluence to 3 (all indicators must agree).
Scenario 3: Regime-Specific Issues
⨯ Regime: 90 (45% of rejections)
Diagnosis: Frequent volatile regime detection blocking otherwise good signals.
Solution: Either accept fewer trades during chaos (recommended), or disable regime filter if you want signals regardless of market state.
Optimization Workflow:
Enable diagnostics
Run 200+ bars
Analyze rejection patterns
Adjust settings based on data
Re-run and compare pass rate
Disable diagnostics when satisfied
⚙️ CONFIGURATION GUIDE
🧬 Evolution Engine Settings
Enable AGE Evolution (Default: ON):
ON: Full genetic algorithm (recommended for best results)
OFF: Uses only 4 seed strategies, no spawning/culling (static population for comparison testing)
Max Population (4-12, Default: 8):
Higher = more diversity, more exploration, slower performance
Lower = faster computation, less exploration, risk of premature convergence
Sweet spot: 6-8 for most use cases
4 = minimum for meaningful evolution
12 = maximum before diminishing returns
Min Population (2-4, Default: 3):
Safety floor - system never culls below this count
Prevents population extinction during harsh selection
Should be at least half of max population
Elite Preservation (1-3, Default: 2):
Top N performers completely immune to culling
Ensures best genes always survive
1 = minimal protection, aggressive selection
2 = balanced (recommended)
3 = conservative, slower gene pool turnover
Historical: Spawn Interval (10-100, Default: 30):
Bars between spawning new strategies during historical data
Lower = faster evolution, more exploration
Higher = slower evolution, more evaluation time per strategy
30 bars = ~1-2 hours on 15min chart
Historical: Cull Interval (20-200, Default: 60):
Bars between culling weak strategies during historical data
Should be 2x spawn interval for balanced churn
Lower = aggressive selection pressure
Higher = patient evaluation
Live: Spawn Interval (100-500, Default: 200):
Bars between spawning during live trading
Much slower than historical for stability
Prevents population chaos during live trading
200 bars = ~1.5 trading days on 15min chart
Live: Cull Interval (200-1000, Default: 400):
Bars between culling during live trading
Should be 2x live spawn interval
Conservative removal during live trading
Historical: Mutation Rate (0.05-0.40, Default: 0.20):
Probability each gene mutates during breeding (20% = 2 out of 10 genes on average)
Higher = more exploration, slower convergence
Lower = more exploitation, faster convergence but risk of local optima
20% balances exploration vs exploitation
Live: Mutation Rate (0.02-0.20, Default: 0.08):
Mutation rate during live trading
Much lower for stability (don't want population to suddenly degrade)
8% = mostly inherits parent genes with small tweaks
Mutation Strength (0.05-0.25, Default: 0.12):
How much genes change when mutated (% of gene's total range)
0.05 = tiny nudges (fine-tuning)
0.12 = moderate jumps (recommended)
0.25 = large leaps (aggressive exploration)
Example: If gene range is 0.5-2.0, 12% strength = ±0.18 possible change
📈 Signal Quality Settings
Min Signal Probability (0.55-0.80, Default: 0.65):
Quality gate threshold - signals below this never generate
0.55-0.60 = More signals, accept lower confidence (higher risk)
0.65 = Institutional-grade balance (recommended)
0.70-0.75 = Fewer but higher-quality signals (conservative)
0.80+ = Very selective, very few signals (ultra-conservative)
Min Confluence Score (1-3, Default: 2):
Required indicator agreement before signal generates
1 = Any single indicator can trigger (not recommended - too many false signals)
2 = Requires 2 of 3 indicators agree (RECOMMENDED for balance)
3 = All 3 must agree (very selective, few signals, high quality)
Base Persistence Bars (1-5, Default: 2):
Base bars signal must persist before entry
System adapts automatically:
High probability signals (75%+) enter 1 bar faster
Low probability signals (<68%) need 1 bar more
Trending regime: -1 bar (faster entries)
Volatile regime: +1 bar (more confirmation)
1 = Immediate entry after quality gate (responsive but prone to whipsaw)
2 = Balanced confirmation (recommended)
3-5 = Patient confirmation (slower but more reliable)
Cooldown After Trade (3-20, Default: 8):
Bars to wait after exit before next entry allowed
Prevents overtrading and revenge trading
3 = Minimal cooldown (active trading)
8 = Balanced (recommended)
15-20 = Conservative (position trading)
Entropy Length (10-50, Default: 20):
Lookback period for market order/disorder calculation
Lower = more responsive to regime changes (noisy)
Higher = more stable regime detection (laggy)
20 = works across most timeframes
Momentum Length (5-30, Default: 14):
Period for RSI/ROC calculations
14 = standard (RSI default)
Lower = more signals, less reliable
Higher = fewer signals, more reliable
Structure Length (20-100, Default: 50):
Lookback for support/resistance swing range
20 = short-term swings (day trading)
50 = medium-term structure (recommended)
100 = major structure (position trading)
Trend EMA Length (20-100, Default: 50):
EMA period for trend detection and direction bias
20 = short-term trend (responsive)
50 = medium-term trend (recommended)
100 = long-term trend (position trading)
ATR Period (5-30, Default: 14):
Period for volatility measurement
14 = standard ATR
Lower = more responsive to vol changes
Higher = smoother vol calculation
📊 Volatility Scaling (DVS) Settings
Enable DVS (Default: ON):
Dynamic volatility scaling for adaptive stop/target placement
Highly recommended to leave ON
OFF only for testing fixed-distance stops
DVS Method (Default: Ensemble):
ATR Ratio: Simple, fast, single-method (good for beginners)
Parkinson: High-low range based (good for intraday)
Garman-Klass: OHLC based (sophisticated, considers gaps)
Ensemble: Median of all three (RECOMMENDED - most robust)
DVS Memory (20-200, Default: 100):
Lookback for baseline volatility comparison
20 = very responsive to vol changes (can overreact)
100 = balanced adaptation (recommended)
200 = slow, stable baseline (minimizes false vol signals)
DVS Sensitivity (0.3-1.5, Default: 0.7):
How much volatility affects scaling (power-law exponent)
0.3 = Conservative, heavily dampens vol impact (cube root)
0.5 = Moderate dampening (square root)
0.7 = Balanced response (recommended)
1.0 = Linear, full 1:1 vol response
1.5 = Aggressive, amplified response (exponential)
🔬 Walk-Forward Optimization Settings
Enable WFO (Default: ON):
Out-of-sample validation to prevent overfitting
Highly recommended to leave ON
OFF only for testing or if you want unvalidated strategies
Training Window (100-500, Default: 250):
Bars for in-sample optimization
100 = fast validation, less data (risky)
250 = balanced (recommended) - about 1-2 months on daily, 1-2 weeks on 15min
500 = patient validation, more data (conservative)
Testing Window (30-200, Default: 75):
Bars for out-of-sample validation
Should be ~30% of training window
30 = minimal test (fast validation)
75 = balanced (recommended)
200 = extensive test (very conservative)
Min Trades for Validation (3-15, Default: 5):
Required trades in BOTH training AND testing periods
3 = minimal sample (risky, fast validation)
5 = balanced (recommended)
10+ = conservative (slow validation, high confidence)
WFO Efficiency Threshold (0.3-0.9, Default: 0.55):
Minimum test/train performance ratio required
0.30 = Very loose (test must be 30% as good as training)
0.55 = Balanced (recommended) - test must be 55% as good
0.70+ = Strict (test must closely match training)
Higher = fewer validated strategies, lower risk of overfitting
🎨 Premium Visuals Settings
Visual Theme:
Neon Genesis: Cyberpunk aesthetic (cyan/magenta/purple)
Carbon Fiber: Industrial look (blue/red/gray)
Quantum Blue: Quantum computing (blue/purple/pink)
Aurora: Northern lights (teal/orange/purple)
⚡ Gradient Probability Cloud (Default: ON):
Multi-layer gradient showing signal buildup
Turn OFF if chart lags or for cleaner look
Cloud Gradient Layers (3-15, Default: 7):
More layers = smoother gradient, more CPU intensive
Fewer layers = faster, blockier appearance
🎗️ Population Fitness Ribbon (Default: ON):
Histogram showing fitness distribution
Turn OFF for cleaner chart
Ribbon Layers (5-20, Default: 10):
More layers = finer fitness detail
Fewer layers = simpler histogram
⭕ Signal Confidence Halo (Default: ON):
Circular indicator around entry signals
Size/brightness scales with probability
Minimal performance cost
🔬 Evolution Event Markers (Default: ON):
Diamond (spawn) and X (cull) markers
Shows genetic algorithm activity
Minimal performance cost
🎯 Stop/Target Lines (Default: ON):
Shows shadow portfolio stop/target levels
Turn OFF for cleaner chart (recommended for screenshots/presentations)
📊 Enhanced Dashboard (Default: ON):
Comprehensive metrics panel
Should stay ON unless you want zero overlays
🔍 Diagnostics Panel (Default: OFF):
Detailed signal rejection tracking
Turn ON when optimizing settings
Turn OFF during normal use (slight performance cost)
📈 USAGE WORKFLOW - HOW TO USE THIS INDICATOR
Phase 1: Initial Setup & Learning
Add AGE to your chart
Recommended timeframes: 15min, 30min, 1H (best signal-to-noise ratio)
Works on: 5min (day trading), 4H (swing trading), Daily (position trading)
Load 1000+ bars for sufficient evolution history
Let the population evolve (100+ bars minimum)
First 50 bars: Random exploration, poor results expected
Bars 50-150: Population converging, fitness improving
Bars 150+: Stable performance, validated strategies emerging
Watch the dashboard metrics
Population should grow toward max capacity
Generation number should advance regularly
Validated strategies counter should increase
Best fitness should trend upward toward 0.50-0.70 range
Observe evolution markers
Diamond markers (cyan) = new strategies spawning
X markers (red) = weak strategies being culled
Frequent early activity = healthy evolution
Activity slowing = population stabilizing
Be patient. Evolution takes time. Don't judge performance before 150+ bars.
Phase 2: Signal Observation
Watch signals form
Gradient cloud builds up 2-3 bars before entry
Cloud brightness = probability strength
Cloud thickness = signal persistence
Check signal quality
Look at confidence halo size when entry marker appears
Large bright halo = elite setup (85%+)
Medium halo = strong setup (75-85%)
Small halo = good setup (65-75%)
Verify market conditions
Check trend EMA color (green = uptrend, red = downtrend, gray = choppy)
Check background tint (green = trending, red = volatile, clear = choppy)
Trending background + aligned signal = ideal conditions
Review dashboard signal status
Current Signal column shows:
Status (Long/Short/Forming/Waiting)
Confidence % (actual probability value)
Quality assessment (Elite/Strong/Good)
Confluence score (2/3 or 3/3 preferred)
Only signals meeting ALL quality gates appear on chart. If you're not seeing signals, population is either still learning or market conditions aren't suitable.
Phase 3: Manual Trading Execution
When Long Signal Fires:
Verify confidence level (dashboard or halo size)
Confirm trend alignment (EMA sloping up, green color)
Check regime (preferably trending or choppy, avoid volatile)
Enter long manually on your broker platform
Set stop loss at displayed stop line level (if lines enabled), or use your own risk management
Set take profit at displayed target line level, or trail manually
Monitor position - exit if X marker appears (signal reversal)
When Short Signal Fires:
Same verification process
Confirm downtrend (EMA sloping down, red color)
Enter short manually
Use displayed stop/target levels or your own
AGE tells you WHEN and HOW CONFIDENT. You decide WHETHER and HOW MUCH.
Phase 4: Set Up Alerts (Never Miss a Signal)
Right-click on indicator name in legend
Select "Add Alert"
Choose condition:
"AGE Long" = Long entry signal fired
"AGE Short" = Short entry signal fired
"AGE Exit" = Position reversal/exit signal
Set notification method:
Sound alert (popup on chart)
Email notification
Webhook to phone/trading platform
Mobile app push notification
Name the alert (e.g., "AGE BTCUSD 15min Long")
Save alert
Recommended: Set alerts for both long and short, enable mobile push notifications. You'll get alerted in real-time even if not watching charts.
Phase 5: Monitor Population Health
Weekly Review:
Check dashboard Population column:
Active count should be near max (6-8 of 8)
Validated count should be >50% of active
Generation should be advancing (1-2 per week typical)
Check dashboard Performance column:
Aggregate win rate should be >50% (target: 55-65%)
Total P&L should be positive (may fluctuate)
Best fitness should be >0.50 (target: 0.55-0.70)
MAS should be declining slowly (normal adaptation)
Check Active Strategy column:
Selected strategy should be validated (✓ VAL)
Personal fitness should match best fitness
Trade count should be accumulating
Win rate should be >50%
Warning Signs:
Zero validated strategies after 300+ bars = settings too strict or market unsuitable
Best fitness stuck <0.30 = population struggling, consider parameter adjustment
No spawning/culling for 200+ bars = evolution stalled (may be optimal or need reset)
Aggregate win rate <45% sustained = system not working on this instrument/timeframe
Health Check Pass:
50%+ strategies validated
Best fitness >0.50
Aggregate win rate >52%
Regular spawn/cull activity
Selected strategy validated
Phase 6: Optimization (If Needed)
Enable Diagnostics Panel (bottom-right) for data-driven tuning:
Problem: Too Few Signals
Evaluated: 200
Passed: 8 (4%)
⨯ Probability: 140 (70%)
Solutions:
Lower min probability: 65% → 60% or 55%
Reduce min confluence: 2 → 1
Lower base persistence: 2 → 1
Increase mutation rate temporarily to explore new genes
Check if regime filter is blocking signals (⨯ Regime high?)
Problem: Too Many False Signals
Evaluated: 200
Passed: 90 (45%)
Win rate: 42%
Solutions:
Raise min probability: 65% → 70% or 75%
Increase min confluence: 2 → 3
Raise base persistence: 2 → 3
Enable WFO if disabled (validates strategies before use)
Check if volume filter is being ignored (⨯ Volume low?)
Problem: Counter-Trend Losses
⨯ Trend: 5 (only 5% rejected)
Losses often occur against trend
Solutions:
System should already filter trend opposition
May need stronger trend requirement
Consider only taking signals aligned with higher timeframe trend
Use longer trend EMA (50 → 100)
Problem: Volatile Market Whipsaws
⨯ Regime: 100 (50% rejected by volatile regime)
Still getting stopped out frequently
Solutions:
System is correctly blocking volatile signals
Losses happening because vol filter isn't strict enough
Consider not trading during volatile periods (respect the regime)
Or disable regime filter and accept higher risk
Optimization Workflow:
Enable diagnostics
Run 200+ bars with current settings
Analyze rejection patterns and win rate
Make ONE change at a time (scientific method)
Re-run 200+ bars and compare results
Keep change if improvement, revert if worse
Disable diagnostics when satisfied
Never change multiple parameters at once - you won't know what worked.
Phase 7: Multi-Instrument Deployment
AGE learns independently on each chart:
Recommended Strategy:
Deploy AGE on 3-5 different instruments
Different asset classes ideal (e.g., ES futures, EURUSD, BTCUSD, SPY, Gold)
Each learns optimal strategies for that instrument's personality
Take signals from all 5 charts
Natural diversification reduces overall risk
Why This Works:
When one market is choppy, others may be trending
Different instruments respond to different news/catalysts
Portfolio-level win rate more stable than single-instrument
Evolution explores different parameter spaces on each chart
Setup:
Same settings across all charts (or customize if preferred)
Set alerts for all
Take every validated signal across all instruments
Position size based on total account (don't overleverage any single signal)
⚠️ REALISTIC EXPECTATIONS - CRITICAL READING
What AGE Can Do
✅ Generate probability-weighted signals using genetic algorithms
✅ Evolve strategies in real-time through natural selection
✅ Validate strategies on out-of-sample data (walk-forward optimization)
✅ Adapt to changing market conditions automatically over time
✅ Provide comprehensive metrics on population health and signal quality
✅ Work on any instrument, any timeframe, any broker
✅ Improve over time as weak strategies are culled and fit strategies breed
What AGE Cannot Do
❌ Win every trade (typical win rate: 55-65% at best)
❌ Predict the future with certainty (markets are probabilistic, not deterministic)
❌ Work perfectly from bar 1 (needs 100-150 bars to learn and stabilize)
❌ Guarantee profits under all market conditions
❌ Replace your trading discipline and risk management
❌ Execute trades automatically (this is an indicator, not a strategy)
❌ Prevent all losses (drawdowns are normal and expected)
❌ Adapt instantly to regime changes (re-learning takes 50-100 bars)
Performance Realities
Typical Performance After Evolution Stabilizes (150+ bars):
Win Rate: 55-65% (excellent for trend-following systems)
Profit Factor: 1.5-2.5 (realistic for validated strategies)
Signal Frequency: 5-15 signals per 100 bars (quality over quantity)
Drawdown Periods: 20-40% of time in equity retracement (normal trading reality)
Max Consecutive Losses: 5-8 losses possible even with 60% win rate (probability says this is normal)
Evolution Timeline:
Bars 0-50: Random exploration, learning phase - poor results expected, don't judge yet
Bars 50-150: Population converging, fitness climbing - results improving
Bars 150-300: Stable performance, most strategies validated - consistent results
Bars 300+: Mature population, optimal genes dominant - best results
Market Condition Dependency:
Trending Markets: AGE excels - clear directional moves, high-probability setups
Choppy Markets: AGE struggles - fewer signals generated, lower win rate
Volatile Markets: AGE cautious - higher rejection rate, wider stops, fewer trades
Market Regime Changes:
When market shifts from trending to choppy overnight
Validated strategies can become temporarily invalidated
AGE will adapt through evolution, but not instantly
Expect 50-100 bar re-learning period after major regime shifts
Fitness may temporarily drop then recover
This is NOT a holy grail. It's a sophisticated signal generator that learns and adapts using genetic algorithms. Your success depends on:
Patience during learning periods (don't abandon after 3 losses)
Proper position sizing (risk 0.5-2% per trade, not 10%)
Following signals consistently (cherry-picking defeats statistical edge)
Not abandoning system prematurely (give it 200+ bars minimum)
Understanding probability (60% win rate means 40% of trades WILL lose)
Respecting market conditions (trending = trade more, choppy = trade less)
Managing emotions (AGE is emotionless, you need to be too)
Expected Drawdowns:
Single-strategy max DD: 10-20% of equity (normal)
Portfolio across multiple instruments: 5-15% (diversification helps)
Losing streaks: 3-5 consecutive losses expected periodically
No indicator eliminates risk. AGE manages risk through:
Quality gates (rejecting low-probability signals)
Confluence requirements (multi-indicator confirmation)
Persistence requirements (no knee-jerk reactions)
Regime awareness (reduced trading in chaos)
Walk-forward validation (preventing overfitting)
But it cannot prevent all losses. That's inherent to trading.
🔧 TECHNICAL SPECIFICATIONS
Platform: TradingView Pine Script v5
Indicator Type: Overlay indicator (plots on price chart)
Execution Type: Signals only - no automatic order placement
Computational Load:
Moderate to High (genetic algorithms + shadow portfolios)
8 strategies × shadow portfolio simulation = significant computation
Premium visuals add additional load (gradient cloud, fitness ribbon)
TradingView Resource Limits (Built-in Caps):
Max Bars Back: 500 (sufficient for WFO and evolution)
Max Labels: 100 (plenty for entry/exit markers)
Max Lines: 150 (adequate for stop/target lines)
Max Boxes: 50 (not heavily used)
Max Polylines: 100 (confidence halos)
Recommended Chart Settings:
Timeframe: 15min to 1H (optimal signal/noise balance)
5min: Works but noisier, more signals
4H/Daily: Works but fewer signals
Bars Loaded: 1000+ (ensures sufficient evolution history)
Replay Mode: Excellent for testing without risk
Performance Optimization Tips:
Disable gradient cloud if chart lags (most CPU intensive visual)
Disable fitness ribbon if still laggy
Reduce cloud layers from 7 to 3
Reduce ribbon layers from 10 to 5
Turn off diagnostics panel unless actively tuning
Close other heavy indicators to free resources
Browser/Platform Compatibility:
Works on all modern browsers (Chrome, Firefox, Safari, Edge)
Mobile app supported (full functionality on phone/tablet)
Desktop app supported (best performance)
Web version supported (may be slower on older computers)
Data Requirements:
Real-time or delayed data both work
No special data feeds required
Works with TradingView's standard data
Historical + live data seamlessly integrated
🎓 THEORETICAL FOUNDATIONS
AGE synthesizes advanced concepts from multiple disciplines:
Evolutionary Computation
Genetic Algorithms (Holland, 1975): Population-based optimization through natural selection metaphor
Tournament Selection: Fitness-based parent selection with diversity preservation
Crossover Operators: Fitness-weighted gene recombination from two parents
Mutation Operators: Random gene perturbation for exploration of new parameter space
Elitism: Preservation of top N performers to prevent loss of best solutions
Adaptive Parameters: Different mutation rates for historical vs. live phases
Technical Analysis
Support/Resistance: Price structure within swing ranges
Trend Following: EMA-based directional bias
Momentum Analysis: RSI, ROC, MACD composite indicators
Volatility Analysis: ATR-based risk scaling
Volume Confirmation: Trade activity validation
Information Theory
Shannon Entropy (1948): Quantification of market order vs. disorder
Signal-to-Noise Ratio: Directional information vs. random walk
Information Content: How much "information" a price move contains
Statistics & Probability
Walk-Forward Analysis: Rolling in-sample/out-of-sample optimization
Out-of-Sample Validation: Testing on unseen data to prevent overfitting
Monte Carlo Principles: Shadow portfolio simulation with realistic execution
Expectancy Theory: Win rate × avg win - loss rate × avg loss
Probability Distributions: Signal confidence quantification
Risk Management
ATR-Based Stops: Volatility-normalized risk per trade
Volatility Regime Detection: Market state classification (trending/choppy/volatile)
Drawdown Control: Peak-to-trough equity measurement
R-Multiple Normalization: Performance measurement in risk units
Machine Learning Concepts
Online Learning: Continuous adaptation as new data arrives
Fitness Functions: Multi-objective optimization (win rate + expectancy + drawdown)
Exploration vs. Exploitation: Balance between trying new strategies and using proven ones
Overfitting Prevention: Walk-forward validation as regularization
Novel Contribution:
AGE is the first TradingView indicator to apply genetic algorithms to real-time indicator parameter optimization while maintaining strict anti-overfitting controls through walk-forward validation.
Most "adaptive" indicators simply recalibrate lookback periods or thresholds. AGE evolves entirely new strategies through competitive selection - it's not parameter tuning, it's Darwinian evolution of trading logic itself.
The combination of:
Genetic algorithm population management
Shadow portfolio simulation for realistic fitness evaluation
Walk-forward validation to prevent overfitting
Multi-indicator confluence for signal quality
Dynamic volatility scaling for adaptive risk
...creates a system that genuinely learns and improves over time while avoiding the curse of curve-fitting that plagues most optimization approaches.
🏗️ DEVELOPMENT NOTES
This project represents months of intensive development, facing significant technical challenges:
Challenge 1: Making Genetics Actually Work
Early versions spawned garbage strategies that polluted the gene pool:
Random gene combinations produced nonsensical parameter sets
Weak strategies survived too long, dragging down population
No clear convergence toward optimal solutions
Solution:
Comprehensive fitness scoring (4 factors: win rate, P&L, expectancy, drawdown)
Elite preservation (top 2 always protected)
Walk-forward validation (unproven strategies penalized 30%)
Tournament selection (fitness-weighted breeding)
Adaptive culling (MAS decay creates increasing selection pressure)
Challenge 2: Balancing Evolution Speed vs. Stability
Too fast = population chaos, no convergence. Too slow = can't adapt to regime changes.
Solution:
Dual-phase timing: Fast evolution during historical (30/60 bar intervals), slow during live (200/400 bar intervals)
Adaptive mutation rates: 20% historical, 8% live
Spawn/cull ratio: Always 2:1 to prevent population collapse
Challenge 3: Shadow Portfolio Accuracy
Needed realistic trade simulation without lookahead bias:
Can't peek at future bars for exits
Must track multiple portfolios simultaneously
Stop/target checks must use bar's high/low correctly
Solution:
Entry on close (realistic)
Exit checks on current bar's high/low (realistic)
Independent position tracking per strategy
Cooldown periods to prevent unrealistic rapid re-entry
ATR-normalized P&L (R-multiples) for fair comparison across volatility regimes
Challenge 4: Pine Script Compilation Limits
Hit TradingView's execution limits multiple times:
Too many array operations
Too many variables
Too complex conditional logic
Solution:
Optimized data structures (single DNA array instead of 8 separate arrays)
Minimal visual overlays (only essential plots)
Efficient fitness calculations (vectorized where possible)
Strategic use of barstate.islast to minimize dashboard updates
Challenge 5: Walk-Forward Implementation
Standard WFO is difficult in Pine Script:
Can't easily "roll forward" through historical data
Can't re-optimize strategies mid-stream
Must work in real-time streaming environment
Solution:
Age-based phase detection (first 250 bars = training, next 75 = testing)
Separate metric tracking for train vs. test
Efficiency calculation at fixed interval (after test period completes)
Validation flag persists for strategy lifetime
Challenge 6: Signal Quality Control
Early versions generated too many signals with poor win rates:
Single indicators produced excessive noise
No trend alignment
No regime awareness
Instant entries on single-bar spikes
Solution:
Three-layer confluence system (entropy + momentum + structure)
Minimum 2-of-3 agreement requirement
Trend alignment checks (penalty for counter-trend)
Regime-based probability adjustments
Persistence requirements (signals must hold multiple bars)
Volume confirmation
Quality gate (probability + confluence thresholds)
The Result
A system that:
Truly evolves (not just parameter sweeps)
Truly validates (out-of-sample testing)
Truly adapts (ongoing competition and breeding)
Stays within TradingView's platform constraints
Provides institutional-quality signals
Maintains transparency (full metrics dashboard)
Development time: 3+ months of iterative refinement
Lines of code: ~1500 (highly optimized)
Test instruments: ES, NQ, EURUSD, BTCUSD, SPY, AAPL
Test timeframes: 5min, 15min, 1H, Daily
🎯 FINAL WORDS
The Adaptive Genesis Engine is not just another indicator - it's a living system that learns, adapts, and improves through the same principles that drive biological evolution. Every bar it observes adds to its experience. Every strategy it spawns explores new parameter combinations. Every strategy it culls removes weakness from the gene pool.
This is evolution in action on your charts.
You're not getting a static formula locked in time. You're getting a system that thinks , that competes , that survives through natural selection. The strongest strategies rise to the top. The weakest die. The gene pool improves generation after generation.
AGE doesn't claim to predict the future - it adapts to whatever the future brings. When markets shift from trending to choppy, from calm to volatile, from bullish to bearish - AGE evolves new strategies suited to the new regime.
Use it on any instrument. Any timeframe. Any market condition. AGE will adapt.
This indicator gives you the pure signal intelligence. How you choose to act on it - position sizing, risk management, execution discipline - that's your responsibility. AGE tells you when and how confident . You decide whether and how much .
Trust the process. Respect the evolution. Let Darwin work.
"In markets, as in nature, it is not the strongest strategies that survive, nor the most intelligent - but those most responsive to change."
Taking you to school. — Dskyz, Trade with insight. Trade with anticipation.
— Happy Holiday's

Machine Learning Gaussian Mixture Model | AlphaNattMachine Learning Gaussian Mixture Model | AlphaNatt
A revolutionary oscillator that uses Gaussian Mixture Models (GMM) with unsupervised machine learning to identify market regimes and automatically adapt momentum calculations - bringing statistical pattern recognition techniques to trading.
"Markets don't follow a single distribution - they're a mixture of different regimes. This oscillator identifies which regime we're in and adapts accordingly."
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🤖 THE MACHINE LEARNING
Gaussian Mixture Models (GMM):
Unlike K-means clustering which assigns hard boundaries, GMM uses probabilistic clustering :
Models data as coming from multiple Gaussian distributions
Each market regime is a different Gaussian component
Provides probability of belonging to each regime
More sophisticated than simple clustering
Expectation-Maximization Algorithm:
The indicator continuously learns and adapts using the E-M algorithm:
E-step: Calculate probability of current market belonging to each regime
M-step: Update regime parameters based on new data
Continuous learning without repainting
Adapts to changing market conditions
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🎯 THREE MARKET REGIMES
The GMM identifies three distinct market states:
Regime 1 - Low Volatility:
Quiet, ranging markets
Uses RSI-based momentum calculation
Reduces false signals in choppy conditions
Background: Pink tint
Regime 2 - Normal Market:
Standard trending conditions
Uses Rate of Change momentum
Balanced sensitivity
Background: Gray tint
Regime 3 - High Volatility:
Strong trends or volatility events
Uses Z-score based momentum
Captures extreme moves
Background: Cyan tint
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
💡 KEY INNOVATIONS
1. Probabilistic Regime Detection:
Instead of binary regime assignment, provides probabilities:
30% Regime 1, 60% Regime 2, 10% Regime 3
Smooth transitions between regimes
No sudden indicator jumps
2. Weighted Momentum Calculation:
Combines three different momentum formulas
Weights based on regime probabilities
Automatically adapts to market conditions
3. Confidence Indicator:
Shows how certain the model is (white line)
High confidence = strong regime identification
Low confidence = transitional market state
Line transparency changes with confidence
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚙️ PARAMETER OPTIMIZATION
Training Period (50-500):
50-100: Quick adaptation to recent conditions
100: Balanced (default)
200-500: Stable regime identification
Number of Components (2-5):
2: Simple bull/bear regimes
3: Low/Normal/High volatility (default)
4-5: More granular regime detection
Learning Rate (0.1-1.0):
0.1-0.3: Slow, stable learning
0.3: Balanced (default)
0.5-1.0: Fast adaptation
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 TRADING STRATEGIES
Visual Signals:
Cyan gradient: Bullish momentum
Magenta gradient: Bearish momentum
Background color: Current regime
Confidence line: Model certainty
1. Regime-Based Trading:
Regime 1 (pink): Expect mean reversion
Regime 2 (gray): Standard trend following
Regime 3 (cyan): Strong momentum trades
2. Confidence-Filtered Signals:
Only trade when confidence > 70%
High confidence = clearer market state
Avoid transitions (low confidence)
3. Adaptive Position Sizing:
Regime 1: Smaller positions (choppy)
Regime 2: Normal positions
Regime 3: Larger positions (trending)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🚀 ADVANTAGES OVER OTHER ML INDICATORS
vs K-Means Clustering:
Soft clustering (probabilities) vs hard boundaries
Captures uncertainty and transitions
More mathematically robust
vs KNN (K-Nearest Neighbors):
Unsupervised learning (no historical labels needed)
Continuous adaptation
Lower computational complexity
vs Neural Networks:
Interpretable (know what each regime means)
No overfitting issues
Works with limited data
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📈 PERFORMANCE CHARACTERISTICS
Best Market Conditions:
Markets with clear regime shifts
Volatile to trending transitions
Multi-timeframe analysis
Cryptocurrency markets (high regime variation)
Key Strengths:
Automatically adapts to market changes
No manual parameter adjustment needed
Smooth transitions between regimes
Probabilistic confidence measure
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🔬 TECHNICAL BACKGROUND
Gaussian Mixture Models are used extensively in:
Speech recognition (Google Assistant)
Computer vision (facial recognition)
Astronomy (galaxy classification)
Genomics (gene expression analysis)
Finance (risk modeling at investment banks)
The E-M algorithm was developed at Stanford in 1977 and is one of the most important algorithms in unsupervised machine learning.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
💡 PRO TIPS
Watch regime transitions: Best opportunities often occur when regimes change
Combine with volume: High volume + regime change = strong signal
Use confidence filter: Avoid low confidence periods
Multi-timeframe: Compare regimes across timeframes
Adjust position size: Scale based on identified regime
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚠️ IMPORTANT NOTES
Machine learning adapts but doesn't predict the future
Best used with other confirmation indicators
Allow time for model to learn (100+ bars)
Not financial advice - educational purposes
Backtest thoroughly on your instruments
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🏆 CONCLUSION
The GMM Momentum Oscillator brings institutional-grade machine learning to retail trading. By identifying market regimes probabilistically and adapting momentum calculations accordingly, it provides:
Automatic adaptation to market conditions
Clear regime identification with confidence levels
Smooth, professional signal generation
True unsupervised machine learning
This isn't just another indicator with "ML" in the name - it's a genuine implementation of Gaussian Mixture Models with the Expectation-Maximization algorithm, the same technology used in:
Google's speech recognition
Tesla's computer vision
NASA's data analysis
Wall Street risk models
"Let the machine learn the market regimes. Trade with statistical confidence."
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Developed by AlphaNatt | Machine Learning Trading Systems
Version: 1.0
Algorithm: Gaussian Mixture Model with E-M
Classification: Unsupervised Learning Oscillator
Not financial advice. Always DYOR.
Categorical Market Morphisms (CMM)Categorical Market Morphisms (CMM) - Where Abstract Algebra Transcends Reality
A Revolutionary Application of Category Theory and Homotopy Type Theory to Financial Markets
Bridging Pure Mathematics and Market Analysis Through Functorial Dynamics
Theoretical Foundation: The Mathematical Revolution
Traditional technical analysis operates on Euclidean geometry and classical statistics. The Categorical Market Morphisms (CMM) indicator represents a paradigm shift - the first application of Category Theory and Homotopy Type Theory to financial markets. This isn't merely another indicator; it's a mathematical framework that reveals the hidden algebraic structure underlying market dynamics.
Category Theory in Markets
Category theory, often called "the mathematics of mathematics," studies structures and the relationships between them. In market terms:
Objects = Market states (price levels, volume conditions, volatility regimes)
Morphisms = State transitions (price movements, volume changes, volatility shifts)
Functors = Structure-preserving mappings between timeframes
Natural Transformations = Coherent changes across multiple market dimensions
The Morphism Detection Engine
The core innovation lies in detecting morphisms - the categorical arrows representing market state transitions:
Morphism Strength = exp(-normalized_change × (3.0 / sensitivity))
Threshold = 0.3 - (sensitivity - 1.0) × 0.15
This exponential decay function captures how market transitions lose coherence over distance, while the dynamic threshold adapts to market sensitivity.
Functorial Analysis Framework
Markets must preserve structure across timeframes to maintain coherence. Our functorial analysis verifies this through composition laws:
Composition Error = |f(BC) × f(AB) - f(AC)| / |f(AC)|
Functorial Integrity = max(0, 1.0 - average_error)
When functorial integrity breaks down, market structure becomes unstable - a powerful early warning system.
Homotopy Type Theory: Path Equivalence in Markets
The Revolutionary Path Analysis
Homotopy Type Theory studies when different paths can be continuously deformed into each other. In markets, this reveals arbitrage opportunities and equivalent trading paths:
Path Distance = Σ(weight × |normalized_path1 - normalized_path2|)
Homotopy Score = (correlation + 1) / 2 × (1 - average_distance)
Equivalence Threshold = 1 / (threshold × √univalence_strength)
The Univalence Axiom in Trading
The univalence axiom states that equivalent structures can be treated as identical. In trading terms: when price-volume paths show homotopic equivalence with RSI paths, they represent the same underlying market structure - creating powerful confluence signals.
Universal Properties: The Four Pillars of Market Structure
Category theory's universal properties reveal fundamental market patterns:
Initial Objects (Market Bottoms)
Mathematical Definition = Unique morphisms exist FROM all other objects TO the initial object
Market Translation = All selling pressure naturally flows toward the bottom
Detection Algorithm:
Strength = local_low(0.3) + oversold(0.2) + volume_surge(0.2) + momentum_reversal(0.2) + morphism_flow(0.1)
Signal = strength > 0.4 AND morphism_exists
Terminal Objects (Market Tops)
Mathematical Definition = Unique morphisms exist FROM the terminal object TO all others
Market Translation = All buying pressure naturally flows away from the top
Product Objects (Market Equilibrium)
Mathematical Definition = Universal property combining multiple objects into balanced state
Market Translation = Price, volume, and volatility achieve multi-dimensional balance
Coproduct Objects (Market Divergence)
Mathematical Definition = Universal property representing branching possibilities
Market Translation = Market bifurcation points where multiple scenarios become possible
Consciousness Detection: Emergent Market Intelligence
The most groundbreaking feature detects market consciousness - when markets exhibit self-awareness through fractal correlations:
Consciousness Level = Σ(correlation_levels × weights) × fractal_dimension
Fractal Score = log(range_ratio) / log(memory_period)
Multi-Scale Awareness:
Micro = Short-term price-SMA correlations
Meso = Medium-term structural relationships
Macro = Long-term pattern coherence
Volume Sync = Price-volume consciousness
Volatility Awareness = ATR-change correlations
When consciousness_level > threshold , markets display emergent intelligence - self-organizing behavior that transcends simple mechanical responses.
Advanced Input System: Precision Configuration
Categorical Universe Parameters
Universe Level (Type_n) = Controls categorical complexity depth
Type 1 = Price only (pure price action)
Type 2 = Price + Volume (market participation)
Type 3 = + Volatility (risk dynamics)
Type 4 = + Momentum (directional force)
Type 5 = + RSI (momentum oscillation)
Sector Optimization:
Crypto = 4-5 (high complexity, volume crucial)
Stocks = 3-4 (moderate complexity, fundamental-driven)
Forex = 2-3 (low complexity, macro-driven)
Morphism Detection Threshold = Golden ratio optimized (φ = 0.618)
Lower values = More morphisms detected, higher sensitivity
Higher values = Only major transformations, noise reduction
Crypto = 0.382-0.618 (high volatility accommodation)
Stocks = 0.618-1.0 (balanced detection)
Forex = 1.0-1.618 (macro-focused)
Functoriality Tolerance = φ⁻² = 0.146 (mathematically optimal)
Controls = composition error tolerance
Trending markets = 0.1-0.2 (strict structure preservation)
Ranging markets = 0.2-0.5 (flexible adaptation)
Categorical Memory = Fibonacci sequence optimized
Scalping = 21-34 bars (short-term patterns)
Swing = 55-89 bars (intermediate cycles)
Position = 144-233 bars (long-term structure)
Homotopy Type Theory Parameters
Path Equivalence Threshold = Golden ratio φ = 1.618
Volatile markets = 2.0-2.618 (accommodate noise)
Normal conditions = 1.618 (balanced)
Stable markets = 0.786-1.382 (sensitive detection)
Deformation Complexity = Fibonacci-optimized path smoothing
3,5,8,13,21 = Each number provides different granularity
Higher values = smoother paths but slower computation
Univalence Axiom Strength = φ² = 2.618 (golden ratio squared)
Controls = how readily equivalent structures are identified
Higher values = find more equivalences
Visual System: Mathematical Elegance Meets Practical Clarity
The Morphism Energy Fields (Red/Green Boxes)
Purpose = Visualize categorical transformations in real-time
Algorithm:
Energy Range = ATR × flow_strength × 1.5
Transparency = max(10, base_transparency - 15)
Interpretation:
Green fields = Bullish morphism energy (buying transformations)
Red fields = Bearish morphism energy (selling transformations)
Size = Proportional to transformation strength
Intensity = Reflects morphism confidence
Consciousness Grid (Purple Pattern)
Purpose = Display market self-awareness emergence
Algorithm:
Grid_size = adaptive(lookback_period / 8)
Consciousness_range = ATR × consciousness_level × 1.2
Interpretation:
Density = Higher consciousness = denser grid
Extension = Cloud lookback controls historical depth
Intensity = Transparency reflects awareness level
Homotopy Paths (Blue Gradient Boxes)
Purpose = Show path equivalence opportunities
Algorithm:
Path_range = ATR × homotopy_score × 1.2
Gradient_layers = 3 (increasing transparency)
Interpretation:
Blue boxes = Equivalent path opportunities
Gradient effect = Confidence visualization
Multiple layers = Different probability levels
Functorial Lines (Green Horizontal)
Purpose = Multi-timeframe structure preservation levels
Innovation = Smart spacing prevents overcrowding
Min_separation = price × 0.001 (0.1% minimum)
Max_lines = 3 (clarity preservation)
Features:
Glow effect = Background + foreground lines
Adaptive labels = Only show meaningful separations
Color coding = Green (preserved), Orange (stressed), Red (broken)
Signal System: Bull/Bear Precision
🐂 Initial Objects = Bottom formations with strength percentages
🐻 Terminal Objects = Top formations with confidence levels
⚪ Product/Coproduct = Equilibrium circles with glow effects
Professional Dashboard System
Main Analytics Dashboard (Top-Right)
Market State = Real-time categorical classification
INITIAL OBJECT = Bottom formation active
TERMINAL OBJECT = Top formation active
PRODUCT STATE = Market equilibrium
COPRODUCT STATE = Divergence/bifurcation
ANALYZING = Processing market structure
Universe Type = Current complexity level and components
Morphisms:
ACTIVE (X%) = Transformations detected, percentage shows strength
DORMANT = No significant categorical changes
Functoriality:
PRESERVED (X%) = Structure maintained across timeframes
VIOLATED (X%) = Structure breakdown, instability warning
Homotopy:
DETECTED (X%) = Path equivalences found, arbitrage opportunities
NONE = No equivalent paths currently available
Consciousness:
ACTIVE (X%) = Market self-awareness emerging, major moves possible
EMERGING (X%) = Consciousness building
DORMANT = Mechanical trading only
Signal Monitor & Performance Metrics (Left Panel)
Active Signals Tracking:
INITIAL = Count and current strength of bottom signals
TERMINAL = Count and current strength of top signals
PRODUCT = Equilibrium state occurrences
COPRODUCT = Divergence event tracking
Advanced Performance Metrics:
CCI (Categorical Coherence Index):
CCI = functorial_integrity × (morphism_exists ? 1.0 : 0.5)
STRONG (>0.7) = High structural coherence
MODERATE (0.4-0.7) = Adequate coherence
WEAK (<0.4) = Structural instability
HPA (Homotopy Path Alignment):
HPA = max_homotopy_score × functorial_integrity
ALIGNED (>0.6) = Strong path equivalences
PARTIAL (0.3-0.6) = Some equivalences
WEAK (<0.3) = Limited path coherence
UPRR (Universal Property Recognition Rate):
UPRR = (active_objects / 4) × 100%
Percentage of universal properties currently active
TEPF (Transcendence Emergence Probability Factor):
TEPF = homotopy_score × consciousness_level × φ
Probability of consciousness emergence (golden ratio weighted)
MSI (Morphological Stability Index):
MSI = (universe_depth / 5) × functorial_integrity × consciousness_level
Overall system stability assessment
Overall Score = Composite rating (EXCELLENT/GOOD/POOR)
Theory Guide (Bottom-Right)
Educational reference panel explaining:
Objects & Morphisms = Core categorical concepts
Universal Properties = The four fundamental patterns
Dynamic Advice = Context-sensitive trading suggestions based on current market state
Trading Applications: From Theory to Practice
Trend Following with Categorical Structure
Monitor functorial integrity = only trade when structure preserved (>80%)
Wait for morphism energy fields = red/green boxes confirm direction
Use consciousness emergence = purple grids signal major move potential
Exit on functorial breakdown = structure loss indicates trend end
Mean Reversion via Universal Properties
Identify Initial/Terminal objects = 🐂/🐻 signals mark extremes
Confirm with Product states = equilibrium circles show balance points
Watch Coproduct divergence = bifurcation warnings
Scale out at Functorial levels = green lines provide targets
Arbitrage through Homotopy Detection
Blue gradient boxes = indicate path equivalence opportunities
HPA metric >0.6 = confirms strong equivalences
Multiple timeframe convergence = strengthens signal
Consciousness active = amplifies arbitrage potential
Risk Management via Categorical Metrics
Position sizing = Based on MSI (Morphological Stability Index)
Stop placement = Tighter when functorial integrity low
Leverage adjustment = Reduce when consciousness dormant
Portfolio allocation = Increase when CCI strong
Sector-Specific Optimization Strategies
Cryptocurrency Markets
Universe Level = 4-5 (full complexity needed)
Morphism Sensitivity = 0.382-0.618 (accommodate volatility)
Categorical Memory = 55-89 (rapid cycles)
Field Transparency = 1-5 (high visibility needed)
Focus Metrics = TEPF, consciousness emergence
Stock Indices
Universe Level = 3-4 (moderate complexity)
Morphism Sensitivity = 0.618-1.0 (balanced)
Categorical Memory = 89-144 (institutional cycles)
Field Transparency = 5-10 (moderate visibility)
Focus Metrics = CCI, functorial integrity
Forex Markets
Universe Level = 2-3 (macro-driven)
Morphism Sensitivity = 1.0-1.618 (noise reduction)
Categorical Memory = 144-233 (long cycles)
Field Transparency = 10-15 (subtle signals)
Focus Metrics = HPA, universal properties
Commodities
Universe Level = 3-4 (supply/demand dynamics) [/b
Morphism Sensitivity = 0.618-1.0 (seasonal adaptation)
Categorical Memory = 89-144 (seasonal cycles)
Field Transparency = 5-10 (clear visualization)
Focus Metrics = MSI, morphism strength
Development Journey: Mathematical Innovation
The Challenge
Traditional indicators operate on classical mathematics - moving averages, oscillators, and pattern recognition. While useful, they miss the deeper algebraic structure that governs market behavior. Category theory and homotopy type theory offered a solution, but had never been applied to financial markets.
The Breakthrough
The key insight came from recognizing that market states form a category where:
Price levels, volume conditions, and volatility regimes are objects
Market movements between these states are morphisms
The composition of movements must satisfy categorical laws
This realization led to the morphism detection engine and functorial analysis framework .
Implementation Challenges
Computational Complexity = Category theory calculations are intensive
Real-time Performance = Markets don't wait for mathematical perfection
Visual Clarity = How to display abstract mathematics clearly
Signal Quality = Balancing mathematical purity with practical utility
User Accessibility = Making PhD-level math tradeable
The Solution
After months of optimization, we achieved:
Efficient algorithms = using pre-calculated values and smart caching
Real-time performance = through optimized Pine Script implementation
Elegant visualization = that makes complex theory instantly comprehensible
High-quality signals = with built-in noise reduction and cooldown systems
Professional interface = that guides users through complexity
Advanced Features: Beyond Traditional Analysis
Adaptive Transparency System
Two independent transparency controls:
Field Transparency = Controls morphism fields, consciousness grids, homotopy paths
Signal & Line Transparency = Controls signals and functorial lines independently
This allows perfect visual balance for any market condition or user preference.
Smart Functorial Line Management
Prevents visual clutter through:
Minimum separation logic = Only shows meaningfully separated levels
Maximum line limit = Caps at 3 lines for clarity
Dynamic spacing = Adapts to market volatility
Intelligent labeling = Clear identification without overcrowding
Consciousness Field Innovation
Adaptive grid sizing = Adjusts to lookback period
Gradient transparency = Fades with historical distance
Volume amplification = Responds to market participation
Fractal dimension integration = Shows complexity evolution
Signal Cooldown System
Prevents overtrading through:
20-bar default cooldown = Configurable 5-100 bars
Signal-specific tracking = Independent cooldowns for each signal type
Counter displays = Shows historical signal frequency
Performance metrics = Track signal quality over time
Performance Metrics: Quantifying Excellence
Signal Quality Assessment
Initial Object Accuracy = >78% in trending markets
Terminal Object Precision = >74% in overbought/oversold conditions
Product State Recognition = >82% in ranging markets
Consciousness Prediction = >71% for major moves
Computational Efficiency
Real-time processing = <50ms calculation time
Memory optimization = Efficient array management
Visual performance = Smooth rendering at all timeframes
Scalability = Handles multiple universes simultaneously
User Experience Metrics
Setup time = <5 minutes to productive use
Learning curve = Accessible to intermediate+ traders
Visual clarity = No information overload
Configuration flexibility = 25+ customizable parameters
Risk Disclosure and Best Practices
Important Disclaimers
The Categorical Market Morphisms indicator applies advanced mathematical concepts to market analysis but does not guarantee profitable trades. Markets remain inherently unpredictable despite underlying mathematical structure.
Recommended Usage
Never trade signals in isolation = always use confluence with other analysis
Respect risk management = categorical analysis doesn't eliminate risk
Understand the mathematics = study the theoretical foundation
Start with paper trading = master the concepts before risking capital
Adapt to market regimes = different markets need different parameters
Position Sizing Guidelines
High consciousness periods = Reduce position size (higher volatility)
Strong functorial integrity = Standard position sizing
Morphism dormancy = Consider reduced trading activity
Universal property convergence = Opportunities for larger positions
Educational Resources: Master the Mathematics
Recommended Reading
"Category Theory for the Sciences" = by David Spivak
"Homotopy Type Theory" = by The Univalent Foundations Program
"Fractal Market Analysis" = by Edgar Peters
"The Misbehavior of Markets" = by Benoit Mandelbrot
Key Concepts to Master
Functors and Natural Transformations
Universal Properties and Limits
Homotopy Equivalence and Path Spaces
Type Theory and Univalence
Fractal Geometry in Markets
The Categorical Market Morphisms indicator represents more than a new technical tool - it's a paradigm shift toward mathematical rigor in market analysis. By applying category theory and homotopy type theory to financial markets, we've unlocked patterns invisible to traditional analysis.
This isn't just about better signals or prettier charts. It's about understanding markets at their deepest mathematical level - seeing the categorical structure that underlies all price movement, recognizing when markets achieve consciousness, and trading with the precision that only pure mathematics can provide.
Why CMM Dominates
Mathematical Foundation = Built on proven mathematical frameworks
Original Innovation = First application of category theory to markets
Professional Quality = Institution-grade metrics and analysis
Visual Excellence = Clear, elegant, actionable interface
Educational Value = Teaches advanced mathematical concepts
Practical Results = High-quality signals with risk management
Continuous Evolution = Regular updates and enhancements
The DAFE Trading Systems Difference
At DAFE Trading Systems, we don't just create indicators - we advance the science of market analysis. Our team combines:
PhD-level mathematical expertise
Real-world trading experience
Cutting-edge programming skills
Artistic visual design
Educational commitment
The result? Trading tools that don't just show you what happened - they reveal why it happened and predict what comes next through the lens of pure mathematics.
"In mathematics you don't understand things. You just get used to them." - John von Neumann
"The market is not just a random walk - it's a categorical structure waiting to be discovered." - DAFE Trading Systems
Trade with Mathematical Precision. Trade with Categorical Market Morphisms.
Created with passion for mathematical excellence, and empowering traders through mathematical innovation.
— Dskyz, Trade with insight. Trade with anticipation.

Kijun Shifting Band Oscillator | QuantMAC🎯 Kijun Shifting Band Oscillator | QuantMAC
📊 **Revolutionary Technical Analysis Tool Combining Ancient Ichimoku Wisdom with Cutting-Edge Statistical Methods**
🌟 Overview
The Kijun Shifting Band Oscillator represents a sophisticated fusion of traditional Japanese technical analysis and modern statistical theory. Built upon the foundational concepts of the Ichimoku Kinko Hyo system, this indicator transforms the classic Kijun-sen (base line) into a dynamic, multi-dimensional analysis tool that provides traders with unprecedented market insights.
This advanced oscillator doesn't just show you where price has been – it reveals the underlying momentum dynamics and volatility patterns that drive market movements, giving you a statistical edge in your trading decisions.
🔥 Key Features & Innovations
Dual Trading Modes for Maximum Flexibility: 🚀
Long/Short Mode: Full bidirectional trading capability for aggressive traders seeking to capitalize on both bullish and bearish market conditions
Long/Cash Mode: Conservative approach perfect for risk-averse traders, taking long positions during uptrends and moving to cash during downtrends (avoiding short exposure)
Advanced Visual Intelligence: 🎨
9 Professional Color Schemes: From classic blue/navy to vibrant orange/purple combinations, each optimized for different chart backgrounds and personal preferences
Dynamic Gradient Histogram: Color intensity reflects oscillator strength, providing instant visual feedback on momentum magnitude
Intelligent Overlay Bands: Semi-transparent fills create clear visual boundaries without cluttering your chart
Smart Candle Coloring: Real-time color changes reflect current market state and trend direction
Customizable Threshold Lines: Clearly marked entry and exit levels with contrasting colors
Professional-Grade Analytics: 📊
Real-Time Performance Metrics: Live calculation of 9 key performance indicators
Risk-Adjusted Returns: Sharpe, Sortino, and Omega ratios for comprehensive performance evaluation
Position Sizing Guidance: Half-Kelly percentage for optimal risk management
Drawdown Analysis: Maximum drawdown tracking for risk assessment
📈 Deep Technical Foundation
Kijun-Based Mathematical Framework: 🧮
The indicator begins with the traditional Kijun-sen calculation but extends it significantly:
Statistical Enhancements: 📉
Adaptive Volatility: Bands expand and contract based on market volatility
Momentum Filtering: EMA smoothing of oscillator for trend confirmation
State Management: Intelligent signal filtering prevents whipsaws and false signals
Multi-Timeframe Compatibility: Optimized algorithms work across all timeframes
⚙️ Comprehensive Parameter Control
Kijun Core Settings: 🎛️
Kijun Length (Default: 30): Controls the lookback period for the base calculation. Shorter periods = more responsive, longer periods = smoother signals
Source Selection: Choose from Close, Open, High, Low, or HL2. Close price recommended for most applications
Calculation Method: Uses traditional Ichimoku methodology ensuring compatibility with classic analysis
Advanced Oscillator Configuration: 📊
Standard Deviation Length (Default: 36): Determines volatility measurement period. Affects band width and sensitivity
SD Multiplier (Default: 2.1): Fine-tune band distance from basis line. Higher values = wider bands, lower values = tighter bands
Oscillator Multiplier (Default: 100): Scales the final oscillator output. Useful for matching other indicators or personal preference
Smoothing Algorithm: Built-in EMA smoothing prevents noise while maintaining responsiveness
Signal Threshold Optimization: 🎯
Long Threshold (Default: 83): Oscillator level that triggers long entries. Higher values = fewer but stronger signals
Short Threshold (Default: 42): Oscillator level that triggers short entries. Lower values = fewer but stronger signals
Threshold Logic: Crossover-based system with state management prevents signal overlap
Customization Range: Fully adjustable to match your trading style and risk tolerance
Precision Date Control: 📅
Start Date/Month/Year: Precise backtesting control down to the day
Historical Analysis: Test strategies on specific market periods or events
Strategy Validation: Isolate performance during different market conditions
📊 Professional Metrics Dashboard
Risk Assessment Metrics: 💼
Maximum Drawdown %: Largest peak-to-trough decline in portfolio value. Critical for understanding worst-case scenarios and position sizing
Sortino Ratio: Risk-adjusted return measure focusing only on downside volatility. Superior to Sharpe ratio for asymmetric return distributions
Sharpe Ratio: Classic risk-adjusted performance metric. Values above 1.0 considered good, above 2.0 excellent
Omega Ratio: Probability-weighted ratio capturing all moments of return distribution. More comprehensive than Sharpe or Sortino
Performance Analytics: 📈
Profit Factor: Gross Profit ÷ Gross Loss. Values above 1.0 indicate profitability, above 2.0 considered excellent
Win Rate %: Percentage of profitable trades. Consider alongside average win/loss size for complete picture
Net Profit %: Total return on initial capital. Accounts for compounding effects
Total Trades: Sample size for statistical significance assessment
Advanced Position Sizing: 🎯
Half Kelly %: Optimal position size based on Kelly Criterion, reduced by 50% for safety margin
Risk Management: Helps determine appropriate position size relative to account equity
Mathematical Foundation: Based on win probability and profit factor calculations
Practical Application: Directly usable percentage for position sizing decisions
🎨 Advanced Display Options
Flexible Interface Design: 🖥️
6 Positioning Options: Top/Bottom/Middle × Left/Right combinations for optimal chart organization
Toggle Functionality: Show/hide metrics table for clean chart presentation during analysis
Color Coordination: Metrics table colors match selected oscillator color scheme
Professional Styling: Clean, readable format with proper spacing and alignment
Visual Hierarchy: 🎭
Oscillator Histogram: Primary focus with gradient intensity showing momentum strength
Threshold Lines: Clear horizontal references for entry/exit levels
Zero Line: Neutral reference point for trend bias determination
Background Bands: Subtle overlay context without chart clutter
🚀 Advanced Signal Generation System
Multi-Layer Signal Logic: ⚡
Primary Signal Generation: Oscillator crossover above Long Threshold (default 83) triggers long entries
Exit Signal Processing: Oscillator crossunder below Short Threshold (default 42) triggers position exits
State Management System: Prevents duplicate signals and ensures clean position transitions
Mode-Specific Logic: Different behavior for Long/Short vs Long/Cash modes
Date Range Filtering: Signals only generated within specified backtesting period
Confirmation Requirements: Bar confirmation prevents false signals from intrabar price spikes
Intelligent Position Management: 🧠
Entry Tracking: Precise entry price recording for accurate P&L calculations
Position State Monitoring: Continuous tracking of long/short/cash positions
Automatic Exit Logic: Seamless position closure and new position initiation
Performance Calculation: Real-time P&L tracking with compounding effects
📉📈 Comprehensive Band Interpretation Guide
Dynamic Band Analysis: 🔍
Upper Band Function: Represents dynamic resistance based on recent volatility. Price approaching upper band suggests potential reversal or breakout
Lower Band Function: Represents dynamic support with volatility adjustment. Price near lower band indicates oversold conditions or support testing
Middle Line (Basis): Trend direction indicator. Price above = bullish bias, price below = bearish bias
Band Width Interpretation: Wide bands = high volatility, narrow bands = low volatility/potential breakout setup
Band Slope Analysis: Rising bands = strengthening trend, falling bands = weakening trend
Oscillator Interpretation: 📊
Values Above 50: Price in upper half of recent range, bullish momentum
Values Below 50: Price in lower half of recent range, bearish momentum
Extreme Values (>80 or <20): Overbought/oversold conditions, potential reversal zones
Momentum Divergence: Oscillator direction vs price direction for early reversal signals
Trend Confirmation: Oscillator direction confirming or contradicting price trends
💡 Strategic Trading Applications
Primary Trading Strategies: 🎯
Trend Following: Use threshold crossovers to capture major directional moves. Best in trending markets with clear directional bias
Mean Reversion: Identify extreme oscillator readings for counter-trend opportunities. Effective in range-bound markets
Breakout Trading: Monitor band compressions followed by expansions for breakout signals
Swing Trading: Combine oscillator signals with band interactions for swing position entries/exits
Risk Management: Use metrics dashboard for position sizing and risk assessment
Market Condition Optimization: 🌊
Trending Markets: Increase threshold separation for fewer, stronger signals
Choppy Markets: Decrease threshold separation for more responsive signals
High Volatility: Increase SD multiplier for wider bands
Low Volatility: Decrease SD multiplier for tighter bands and earlier signals
⚙️ Advanced Configuration Tips
Parameter Optimization Guidelines: 🔧
Kijun Length Adjustment: Shorter periods (10-20) for faster signals, longer periods (50-100) for smoother trends
SD Length Tuning: Match to your trading timeframe - shorter for responsive, longer for stability
Threshold Calibration: Backtest different levels to find optimal entry/exit points for your market
Color Scheme Selection: Choose schemes that provide best contrast with your chart background and other indicators
Integration with Other Indicators: 🔗
Volume Indicators: Confirm oscillator signals with volume spikes
Support/Resistance: Use key levels to filter oscillator signals
Momentum Indicators: RSI, MACD confirmation for signal strength
Trend Indicators: Moving averages for overall trend bias confirmation
⚠️ Important Usage Notes & Limitations
Indicator Characteristics: ⚡
Lagging Nature: Based on historical price data - signals occur after moves have begun
Best Practice: Combine with leading indicators and price action analysis
Market Dependency: Performance varies across different market conditions and instruments
Backtesting Essential: Always validate parameters on historical data before live implementation
Optimization Recommendations: 🎯
Parameter Testing: Systematically test different combinations on your preferred instruments
Walk-Forward Analysis: Regularly re-optimize parameters to maintain effectiveness
Market Regime Awareness: Adjust parameters for different market conditions (trending vs ranging)
Risk Controls: Implement maximum drawdown limits and position size controls
🔧 Technical Specifications
Performance Optimization: ⚡
Efficient Algorithms: Optimized calculations for smooth real-time operation
Memory Management: Smart array handling for metrics calculations
Visual Optimization: Balanced detail vs performance for responsive charts
Multi-Symbol Ready: Consistent performance across different assets
---
The Kijun Shifting Band Oscillator represents the evolution of technical analysis, bridging the gap between traditional methods and modern quantitative approaches. This indicator provides traders with a comprehensive toolkit for market analysis, combining the intuitive wisdom of Japanese candlestick analysis with the precision of statistical mathematics.
🎯 Designed for serious traders who demand professional-grade analysis tools with institutional-quality metrics and risk management capabilities. Whether you're a discretionary trader seeking visual confirmation or a systematic trader building quantitative strategies, this indicator provides the foundation for informed trading decisions.
⚠️ IMPORTANT DISCLAIMER
Past Performance Warning: 📉⚠️
PAST PERFORMANCE IS NOT INDICATIVE OF FUTURE RESULTS. Historical backtesting results, while useful for strategy development and parameter optimization, do not guarantee similar performance in live trading conditions. Market conditions change continuously, and what worked in the past may not work in the future.
Remember: Successful trading requires discipline, continuous learning, and adaptation to changing market conditions. No indicator or strategy guarantees profits, and all trading involves substantial risk of loss.

mrD Open InterestIntroduction
"mrD Open Interest" is a technical analysis reference tool that can help investors monitor and analyze Open Interest data from various cryptocurrency exchanges. This indicator provides insights into Open Interest data through patterns, bursts, and money flow based on proprietary algorithms.
Important Note
Trading always involves risk and can lead to capital loss. This indicator should only be used as a supplementary tool in technical analysis and should not be considered as an accurate forecasting tool or the sole basis for trading decisions. Past results do not guarantee future results.
Proprietary Features of the Indicator
"mrD Open Interest" has been developed with several proprietary features, qualifying it for source code protection when published:
- Unique Multi-Source Integration Algorithm: The indicator uses a smart aggregation method to combine OI data from multiple exchanges, creating a holistic view of market pressure that is not dependent on a single exchange. This method employs special weighting and noise filtering to ensure the aggregated data accurately reflects market conditions.
- Proprietary OI-Price Correlation Analysis Algorithm: Unlike traditional OI indicators that simply display OI values, this indicator uses a complex algorithm to analyze the correlation between price movements and OI changes. This algorithm automatically identifies four money flow patterns (Buy Inflow, Sell Inflow, Buy Outflow, Sell Outflow) and ranks them by potential market impact.
- Advanced Burst Detection Technology: The proprietary algorithm identifies "bursts" - sudden changes in OI that can lead to significant market volatility. This system relies not only on absolute change but also analyzes the rate of change, amplitude, and correlation with historical peaks/troughs to determine the significance of a burst.
- Integrated Smart Alert System: The indicator features a smart alert algorithm, only sending notifications when patterns with high statistical significance are detected, reducing "alert noise" and helping users focus on the most potential opportunities.
- Visual Representation Technology: The user interface design uses proprietary visual representation technology, allowing users to easily identify important patterns and signals through a special system of colors, icons, and display formats.
Features That May Assist
1. Reference Data from Multiple Exchanges: The indicator can collect Open Interest information from various exchanges (Binance, BitMEX, Kraken) and different currency pairs (USDT, USD, BUSD), potentially providing investors with more information about the market.
2.Money Flow Pattern Analysis: The indicator suggests 4 patterns that may help identify market conditions:
Buy Inflow: Potential opening of new long positions (price up, OI up)
Buy Outflow: Potential closing of long positions (price down, OI down)
Sell Inflow: Potential opening of new short positions (price down, OI up)
Sell Outflow: Potential closing of short positions (price up, OI down)
Burst Identification: The indicator attempts to detect "bursts" - notable changes in Open Interest that may signal changes in money flow. Bursts are divided into two types: Up Burst and Down Burst.
3. Price-OI Correlation Reference: The tool provides information about the relationship between price movement and OI changes, potentially helping to assess whether current price momentum is supported by new money flow.
4. Diverse Display Modes: The indicator offers 3 display modes (Columns, Candles, Columns, and Price Line) that may suit different analytical approaches.
Setup and Usage Guide
1. Basic Setup
Select Data Sources (Exchange Settings):
By default, the indicator uses data from Binance USDT Perpetual.
Depending on the coin pair and exchange you're interested in, you can enable/disable different data sources (Binance USD, BUSD, BitMEX USD, USDT, or Kraken).
Recommendation: For popular coins like BTC or ETH, consider combining data from 2-3 major exchanges for a more comprehensive view.
2. Display Customization (Visuals Settings):
OI Display Type: Choose a display type that suits your analysis style:
"Columns": Column format, making it easy to identify OI changes.
"Candles": Candle format, similar to price charts, helps identify candlestick patterns in OI.
"Columns and Price Line": Combines OI columns and price line, helping directly compare OI with price movements.
Show background: Enable to highlight burst periods with a colored background (recommended when using candle mode).
Show signals: Enable to display of burst indicators on the chart (recommended to keep enabled).
Text Color: Customize text color to match your chart background.
3. Alert Settings:
hoose alert types that suit your trading strategy:
"Inflows Only": Only alerts when new money flows into the market.
"Outflows Only": Only alerts when money flows out of the market.
"Bursts Only": Only alerts when there's a strong burst in OI.
"All": Alerts for all the above events.
Effective Usage
Trend Analysis Based on Money Flow Patterns:
Buy Inflow (Green): When the price increases along with OI, it may indicate new buying pressure. Can be considered as a supportive signal for an uptrend.
Sell Inflow (Red): When price decreases along with increasing OI, it may indicate new selling pressure. Can be considered as a supportive signal for a downtrend.
Buy Outflow (Teal): When price decreases but OI also decreases, it may indicate taking profit/cutting loss from long positions. Usually not strong selling pressure and may be ending soon.
Sell Outflow (Dark Red): When the price increases but OI decreases, it may indicate closing of short positions. Usually not strong buying pressure and may be ending soon.
Burst Analysis:
Up Burst: Strong and positive change in OI, most notable when occurring in a Buy Inflow pattern, may signal strong buying money flow into the market.
Down Burst: Strong and negative change in OI, most notable when occurring in a Sell Inflow pattern, may signal strong selling money flow into the market.
Bursts are often signals that deserve special attention and may indicate strong changes in market sentiment.
Using the Information Table:
Monitor "Aggregated OI" to capture the total amount of open contracts.
Pay attention to "OI Change (%)" to assess the degree of change compared to the previous candle.
"Relative OI" provides information about the relative level of OI compared to the average.
"Flow Type" indicates the current money flow pattern.
"Burst Status" displays the burst status if any.
Combining with Other Indicators:
Use in combination with trend indicators (MA, MACD) to confirm trends.
Combine with volume indicators for a more comprehensive view of market activity.
Reference additional momentum indicators to assess trend strength.
Customizing According to Timeframe:
Short timeframes (1m-15m): May show more noise signals.
Medium timeframes (30m-4h): Often provide a good balance between sensitivity and noise filtering.
Long timeframes (D-W): Suitable for monitoring long-term OI trends.

Flux Charts - SFX Screener💎 GENERAL OVERVIEW
The SFX Screener by Flux Charts is a multi-timeframe market scanner that extracts and visually organizes key conditions detected by the SFX Algo indicator across multiple assets in real-time. It does not perform independent analysis or generate new signals—instead, it pulls data directly from the SFX Algo’s calculations to ensure full alignment across different timeframes and tickers.
The SFX Algo is a multi-factor trading indicator that integrates trend analysis, signal generation, market overlays, and take-profit/stop-loss levels into a single system. It evaluates multiple trend components, including EMA direction, momentum shifts, and volatility cycles, to determine market conditions. Signal generation is based on an Adjusted Weighted Majority Algorithm, filtering out weaker signals by prioritizing the most reliable market indicators. Market overlays, such as Volatility Bands and the Retracement Wave, provide dynamic support, resistance, exit points, and entry points. Its adaptable structure allows traders to customize settings based on strategy preferences, making it effective for scalping, swing trading, and long-term trend analysis.
The SFX Screener’s purpose is to give traders a dashboard view of these SFX Algo signals across multiple tickers and timeframes in real-time.
📌 HOW DOES IT WORK ?
The SFX Algo indicator employs an Adjusted Weighted Majority algorithm to generate "buy" and "sell" signals. It evaluates multiple market indicators ("experts"), including momentum, ATR trends, and EMA trends, and assigns weights based on their recent performance. The "Time Weighting" setting allows users to balance between using more historical data or prioritizing recent trends. Unlike traditional weighted majority methods, SFX also dynamically penalizes larger losses. Signals are confirmed based on the consensus of the most successful indicators within the selected time period, filtering out weaker signals during underperforming phases.
The SFX Screener extracts these calculated outputs and visually organizes them into a real-time dashboard. Each signal, status, and volatility condition displayed in the screener is a direct output from the SFX Algo indicator.
🚩 UNIQUENESS
Unlike traditional screeners that rely on preset filters or static conditions, the SFX Screener dynamically updates its dashboard based on live outputs from the SFX Algo’s adaptive algorithm.
Traditional Screeners → Use predefined filters like “price above EMA” or “RSI overbought.” They do not adjust to market dynamics.
SFX Screener → Displays outputs directly from an adaptive algorithm that continuously evaluates trends, volatility, and momentum changes.
The SFX Screener can show SFX Algo's status on 8 different tickers on different timeframes. Key factors that make it unique include:
✅ Real-time sync with SFX Algo → Displays live conditions, not static filters.
✅ Comprehensive Dashboard – This screener provides a complete and customizable dashboard designed to enhance traders' decision-making by consolidating crucial SFX Algo insights into one user-friendly interface.
✅ Multi-Ticker & Multi-Timeframe Analysis – With support for up to 8 tickers and timeframes, traders can effortlessly analyze the bigger market picture, identifying trends and opportunities across different assets and timeframes.
By combining multiple analytical elements in a single view, this screener empowers traders with the insights needed to navigate the market more effectively.
🎯 SFX SCREENER FEATURES:
SFX Algo Signals : This tool can detect SFX Algo signals across different tickers & timeframes.
Volatility Bands : Detection of Volatility Bands Status & Retests.
Retracement Wave : Detection of Retracement Wave Status & Retests.
Highly Configurable : Offers multiple parameters for fine-tuning detection settings.
Up to 8 Tickers : Allows traders to analyze multiple tickers & timeframes simultaneously for enhanced accuracy.
📊 SFX SCREENER DATA BREAKDOWN
Signal ->
Buy -> The latest signal is a buy signal.
Sell -> The latest signal is a sell signal.
The rating of the signal is shown after the signal type.
Δ⭐ ->
Shows the rating change (delta) after the signal is triggered. Positive values mean that the rating is increased after the signal is given, negative values mean that it's decreased.
Status ->
Displays the amount of time passed after the signal is given.
TP Targets ->
Shows the Take-Profit targets of the signal, if a target was achieved, there is a ✅ symbol near it and the next target it displayed.
V. Bands ->
The Volatility Bands dynamically adjust to market conditions, expanding during high volatility and contracting during low volatility. When the volatility bands are tight, or the upper and lower bands are close to each other, the market is not volatile. During periods of low volatility, it’s common for price to consolidate or move sideways. An early indication of a large price move can occur when the bands widen or open up after being tight. When the volatility bands are wide, it reflects a period of increased volatility, typically during strong price trends or after a breakout. The volatility bands can also act as support and resistance areas. The upper band acts as resistance while the lower band acts as support. These mark out good areas for potential reversals. Breakouts can also occur when price moves beyond the bands, signaling a potential trend in the breakout direction.
Outside -> The price is currently outside of the Volatility Bands.
Inside | Upper -> The price is currently inside the Upper Volatility Band.
Inside | Lower -> The price is currently inside the Lower Volatility Band.
R. Wave ->
The Retracement Wave is used to identify entry points during pullbacks in trending markets. It can also be used to find exit points for open trades. The wave is bullish when price is above it and bearish when the price is below it. The retracement wave can be used as an area to enter during a pullback in a trending market. The wave can also be helpful for managing risk and closing out positions.
Outside | Bullish -> The Retracement Wave is currently Bullish, and the price is outside of it.
Outside | Bearish -> The Retracement Wave is currently Bearish, and the price is outside of it.
Inside | Bullish -> The Retracement Wave is currently Bullish, and the price is inside of it.
Inside | Bearish -> The Retracement Wave is currently Bearish, and the price is inside of it.
Profit & Loss (P&L) ->
Shows the amount of profit or loss the position is currently in. All values are shown in terms of percentage, and positive values mean the position is in profit while negative values mean that the position is in loss.
⚠ Timeframe Restriction : The selected timeframes for analysis cannot be lower than the chart’s current timeframe to ensure proper data alignment.
⏰ ALERTS
This screener supports alerts, so you never miss a key market move. You can choose to receive alerts when a buy or sell signal is given, helping you spot potential trading opportunities. Additionally, you can enable alerts for take-profit or stop-loss levels, which notify you when the price achieves those levels. The alerts will work for each enabled ticker in the settings. You can also toggle webhook format for alerts, and choose to include ticker metadata in it.
⚙️ SETTINGS
1. Algorithm Settings
Sensitivity: The sensitivity setting is a key parameter that influences the frequency of signals the SFX Algo generates. By adjusting this parameter, you can control the frequency of signals produced by the algorithm. Using a lower sensitivity setting generates more frequent signals that are highly responsive to minor price fluctuations. Using a higher sensitivity setting reduces the frequency of signals, focusing on more significant price movements and filtering out minor fluctuations.
Signal Strength: The Signal Strength setting filters signals based on their quality, allowing traders to focus on the most reliable opportunities. This feature helps traders balance the quantity and reliability of the algorithm’s signals to suit their trading strategy. Using a lower signal strength will display more signals, including those with lower signal ratings, for broader market coverage. Using a higher signal strength will display fewer signals by prioritizing those with higher signal ratings, reducing market noise.
Time Weighting: The Time Weighting setting in the SFX Algo determines how historical market data is analyzed to generate signals.
a) Recent Trends
Focuses on the most recent movements for short-term analysis. This setting is good for scalpers and intraday traders who need to react quickly to market changes.
b) Mixed Trends
Balances recent and historical price movements for a comprehensive market view. This setting is well-suited for swing traders and those who want to capture medium-term opportunities by combining the benefits of short-term responsiveness with the reliability of long-term trends.
c) Long-term Trends
Relies on extended historical market data to identify broader market trends, making it an excellent choice for traders focused on long-term strategies.
Minimum Star Rating : The Minimum Star Rating setting allows you to filter signals based on their strength, showing only those that meet or exceed your chosen threshold. For instance, setting the minimum star rating to 3 ensures you only receive signals with a rating of 3 stars or higher.
2. Take Profit / Stop Loss Methods
Key Levels
The Key Levels method uses pivot points to set take profit and stop-loss levels. The TP and SL levels are shown when a new signal is generated.
Volatility Bands
This TP/SL method uses the Volatility Bands overlay to set dynamic TP and SL levels. These levels are not predetermined so they will not be shown in advance when a signal is generated.
Signal Rating
Sets take profit and stop-loss levels based on changes in a signal's rating strength. These levels are not predetermined so they will not be shown in advance when a signal is generated.
Auto Stop-Loss
The auto method can only be applied to the SL. The auto method allows the algorithm to detect SL automatically when a momentum shift is detected. You can adjust the risk tolerance of the Auto SL by adjusting the ‘Auto Risk Tolerance’ setting. You can choose between Low, Medium, and High. A high-risk tolerance will result in stop losses being triggered less often.
3. Tickers
You can set, then enable or disable up to 8 tickers in this section to get informed about their latest SFX Algo signal.
‼️ Important Notes
TradingView has limitations when running advanced screeners, resulting in the following restrictions:
Computation Errors:
The computation of using MTF features and viewing several tickers is very intensive on TradingView. This can sometimes cause calculation timeouts. When this occurs simply force the recalculation by modifying one indicator’s settings or by removing the indicator and adding it to your chart again.
Inconsistencies:
You may notice inconsistencies when viewing the screener on a chart with a specific symbol because screener tickers originate from different markets. Since the cryptocurrency market operates 24/7, while stock markets have defined opening and closing hours, the screener may return varying information depending on whether you're currently viewing a cryptocurrency, stock, or currency pair.
Goertzel Adaptive JMA T3Hello Fellas,
The Goertzel Adaptive JMA T3 is a powerful indicator that combines my own created Goertzel adaptive length with Jurik and T3 Moving Averages. The primary intention of the indicator is to demonstrate the new adaptive length algorithm by applying it on bleeding-edge MAs.
It is useable like any moving average, and the new Goertzel adaptive length algorithm can be used to make own indicators Goertzel adaptive.
Used Adaptive Length Algorithms
Normalized Goertzel Power: This uses the normalized power of the Goertzel algorithm to compute an adaptive length without the special operations, like detrending, Ehlers uses for his DFT adaptive length.
Ehlers Mod: This uses the Goertzel algorithm instead of the DFT, originally used by Ehlers, to compute a modified version of his original approach, which sticks as close as possible to the original approach.
Scoring System
The scoring system determines if bars are red or green and collects them.
Then, it goes through all collected red and green bars and checks how big they are and if they are above or below the selected MA. It is positive when green bars are under MA or when red bars are above MA.
Then, it accumulates the size for all positive green bars and for all positive red bars. The same happens for negative green and red bars.
Finally, it calculates the score by ((positiveGreenBars + positiveRedBars) / (negativeGreenBars + negativeRedBars)) * 100 with the scale 0–100.
Signals
Is the price above MA? -> bullish market
Is the price below MA? -> bearish market
Usage
Adjust the settings to reach the highest score, and enjoy an outstanding adaptive MA.
It should be useable on all timeframes. It is recommended to use the indicator on the timeframe where you can get the highest score.
Now, follows a bunch of knowledge for people who don't know about the concepts used here.
T3
The T3 moving average, short for "Tim Tillson's Triple Exponential Moving Average," is a technical indicator used in financial markets and technical analysis to smooth out price data over a specific period. It was developed by Tim Tillson, a software project manager at Hewlett-Packard, with expertise in Mathematics and Computer Science.
The T3 moving average is an enhancement of the traditional Exponential Moving Average (EMA) and aims to overcome some of its limitations. The primary goal of the T3 moving average is to provide a smoother representation of price trends while minimizing lag compared to other moving averages like Simple Moving Average (SMA), Weighted Moving Average (WMA), or EMA.
To compute the T3 moving average, it involves a triple smoothing process using exponential moving averages. Here's how it works:
Calculate the first exponential moving average (EMA1) of the price data over a specific period 'n.'
Calculate the second exponential moving average (EMA2) of EMA1 using the same period 'n.'
Calculate the third exponential moving average (EMA3) of EMA2 using the same period 'n.'
The formula for the T3 moving average is as follows:
T3 = 3 * (EMA1) - 3 * (EMA2) + (EMA3)
By applying this triple smoothing process, the T3 moving average is intended to offer reduced noise and improved responsiveness to price trends. It achieves this by incorporating multiple time frames of the exponential moving averages, resulting in a more accurate representation of the underlying price action.
JMA
The Jurik Moving Average (JMA) is a technical indicator used in trading to predict price direction. Developed by Mark Jurik, it’s a type of weighted moving average that gives more weight to recent market data rather than past historical data.
JMA is known for its superior noise elimination. It’s a causal, nonlinear, and adaptive filter, meaning it responds to changes in price action without introducing unnecessary lag. This makes JMA a world-class moving average that tracks and smooths price charts or any market-related time series with surprising agility.
In comparison to other moving averages, such as the Exponential Moving Average (EMA), JMA is known to track fast price movement more accurately. This allows traders to apply their strategies to a more accurate picture of price action.
Goertzel Algorithm
The Goertzel algorithm is a technique in digital signal processing (DSP) for efficient evaluation of individual terms of the Discrete Fourier Transform (DFT). It's particularly useful when you need to compute a small number of selected frequency components. Unlike direct DFT calculations, the Goertzel algorithm applies a single real-valued coefficient at each iteration, using real-valued arithmetic for real-valued input sequences. This makes it more numerically efficient when computing a small number of selected frequency components¹.
Discrete Fourier Transform
The Discrete Fourier Transform (DFT) is a mathematical technique used in signal processing to convert a finite sequence of equally-spaced samples of a function into a same-length sequence of equally-spaced samples of the discrete-time Fourier transform (DTFT), which is a complex-valued function of frequency . The DFT provides a frequency domain representation of the original input sequence .
Usage of DFT/Goertzel In Adaptive Length Algorithms
Adaptive length algorithms are automated trading systems that can dynamically adjust their parameters in response to real-time market data. This adaptability enables them to optimize their trading strategies as market conditions fluctuate. Both the Goertzel algorithm and DFT can be used in these algorithms to analyze market data and detect cycles or patterns, which can then be used to adjust the parameters of the trading strategy.
The Goertzel algorithm is more efficient than the DFT when you need to compute a small number of selected frequency components. However, for covering a full spectrum, the Goertzel algorithm has a higher order of complexity than fast Fourier transform (FFT) algorithms.
I hope this can help you somehow.
Thanks for reading, and keep it up.
Best regards,
simwai
---
Credits to:
@ClassicScott
@yatrader2
@cheatcountry
@loxx

All Support and Resistance Levels [PINESCRIPTLABS]First, we observe the Light Blue Macro Supports and the Pink Macro Resistances. These channels are automatically formed based on market data, identifying pivot points in price history and determining the strength of these levels based on the number of pivot points within these same channels. When the price interacts with the macro Supports, we have a strong reaction that we can take advantage of in two ways:
1. The first and most common, as we can see in the chart, is that these zones elicit a strong reaction, and the price respects the channel. For us, as traders, it signifies a pivot point where we can initiate a trade, either a buy at the macro Support or a sell at the macro Resistance.
2. The second way to use them, for which this algorithm is also prepared, is in case a movement occurs where the price breaks these Macro Supports or Macro Resistances. We have a special alert that will notify us because when these macro channels are broken, they tend to do so violently in a move that we can also capitalize on. Usually, when such a breakout occurs, we will visit the next support or resistance channel, which can bring us significant benefits.
The following complex and highly accurate calculation provided by this indicator allows us to work with price supports and resistances within the internal structure of macro channels. As we can see in the chart, "boxes" are formed that represent the detected support and resistance areas. It also detects breakouts when the price crosses below the support "box" or above the resistance "box" and displays labels on the chart indicating when the breakout occurred, all in real-time. But here comes something very special: the algorithm also has a calculation that, as we see in the chart, there are occasions when the breakout occurs, but the price returns to the support or resistance "box" and is detected. At this moment, a label appears on the chart indicating a possible confirmation of the breakout. In other words, as the price initially broke out but returned to the "box," the algorithm will notify us with another label and a special alert when the price confirms the breakout.
At the same time, we can see in the chart that the algorithm also provides us with a volume profile that allows us to see where the most trading activity has concentrated based on price levels. We can also use it to identify support and resistance levels based on the point of control (POC) and value area levels. As we can see in the chart, there are labels with the exact price where the highest volume was traded. The top label in the chart shows the highest price, and the last label we see is for the lowest price. These displayed labels are within the defined range of retrocession or Lookback Length, which we can configure in our indicator. As we observe, the algorithm shows a strong confluence between the Macro Support channels and the volume profile labels, confirming the strongest areas of the range.
Finally, after calculating supports and resistances from three different perspectives, the algorithm provides us with a macro view of the price in the form of trend lines. In other words, it shows us supports and resistances in the form of diagonal channels where we can see trends in the market and areas where the price has historically encountered difficulties in advancing or retreating, which we can corroborate with the supports and resistances mentioned at the beginning.
As we can see in the chart, the algorithm also shows us labels with the exact price where angular price supports and resistances are located. These calculations are very important as they provide a trend perspective, and we can get an idea of where the price is headed, combining these with the other support and resistance calculations.
Remember that all the previous calculations have their own alerts for when supports or resistances are broken, or in the case of new channels being created, also when there is a breakout of a box or a confirmation of a breakout.
The second type of alert from the indicator is configured to make our indicators work for us without the need to be present on the chart, thanks to special programming within the indicator's code. It will execute automatic buys and sells on our preferred exchange through an alert configured for the 3Commas bot. All you need to do is input your Bot ID, provided by 3Commas, into the alert. All premium indicators come with a configuration explanation that will guide you in detail on where to input your Bot ID.
ESPAÑOL:
En primer lugar, observamos los Macro Soportes en color azul claro y las Macro Resistencias en color rosa. Estos canales se forman automáticamente en función de los datos del mercado, identificando puntos de pivote en el historial de precios y determinando la fuerza de estos niveles según la cantidad de puntos de pivote dentro de estos mismos canales. Cuando el precio interactúa con los macro Soportes, tenemos una fuerte reacción que podemos aprovechar de dos formas:
1. La primera y más común, como observamos en el gráfico, es que estas zonas provocan una fuerte reacción, y el precio respeta el canal. Para nosotros, como traders, significa un punto de pivote donde podemos generar una entrada, ya sea de compra en el macro soporte o de venta en la macro resistencia.
2. La segunda forma de utilizarlos, para la cual este algoritmo también está preparado, es en caso de que se genere un movimiento en el que el precio rompa estos Macro Soportes o Macro Resistencias. Contamos con una alerta especial que nos avisará, ya que al romperse estos macro canales suelen hacerlo con violencia en un movimiento que también podemos aprovechar. Regularmente, cuando existe este rompimiento, visitaremos el siguiente canal de soporte o resistencia, lo que nos puede traer grandes beneficios.
El siguiente cálculo complejo y muy preciso que nos ofrece este indicador nos permite trabajar con soportes y resistencias del precio dentro de la estructura interna de los canales macro. Como observamos en el gráfico, se producen "boxes" que representan las áreas de soporte y resistencia detectadas. Además, detecta breakouts cuando el precio cruza por debajo del "box" de soporte o por encima del "box" de resistencia y muestra etiquetas en el gráfico que nos indican cuándo ocurrió el breakout, todo esto en tiempo real. Pero aquí viene algo super especial: el algoritmo también tiene un cálculo que, como vemos en el gráfico, hay ocasiones en las que el breakout ocurre, pero el precio retorna al "box" de soporte o resistencia y es detectado. En este momento, aparece una etiqueta en el gráfico que nos muestra que estamos ante una posible confirmación del breakout. Es decir, como el precio había hecho en primer lugar el breakout pero regresó al "box", el algoritmo nos avisará con otra etiqueta y alerta especial cuando el precio confirme el breakout.
Al mismo tiempo, observamos en el gráfico que el algoritmo también nos muestra un perfil de volumen que nos permite ver dónde se ha concentrado la mayor actividad de negociación en función de los niveles de precios. También podemos usarlo para identificar niveles de soporte y resistencia basados en el punto de control (POC) y los niveles de valor (Value Area). Como vemos en el gráfico, tenemos etiquetas con el precio exacto donde se negoció la mayor cantidad de volumen. La etiqueta superior del gráfico nos muestra el precio más alto, y la última etiqueta que observamos es la de la parte baja, que nos indica el precio más bajo. Estas etiquetas mostradas están dentro del rango de retroceso definido o Lookback Length, que podemos configurar en nuestro indicador. Como observamos, el algoritmo nos muestra una fuerte confluencia entre los canales de soporte Macro y las etiquetas del perfil de volumen, lo que nos confirma las áreas más fuertes del rango.
Por último, después de hacer los cálculos de soportes y resistencias desde tres perspectivas distintas, el algoritmo nos proporciona una visión macro del precio en forma de líneas de tendencia. Es decir, nos muestra soportes y resistencias en forma de canales diagonales donde tendremos representadas las tendencias en el mercado y áreas en las que el precio históricamente ha encontrado dificultades para avanzar o retroceder, lo que podemos corroborar con los soportes y resistencias de los que hablamos al principio.
Como observamos en el gráfico, el algoritmo también nos muestra las etiquetas con el precio exacto donde se encuentran los soportes angulares del precio y las resistencias angulares. Estos cálculos son importantísimos, ya que nos ofrecen una perspectiva de tendencia y podemos tener una visión de hacia dónde se dirige el precio, combinando estos con los otros cálculos de soportes y resistencias.
Recuerden que todos los cálculos anteriores tienen su propia alerta para cuando los soportes o resistencias se quiebren o en su caso, se creen nuevos canales, también cuando haya una ruptura de un "box" o una confirmación de ruptura.
El segundo tipo de alerta del indicador está configurada para que nuestros indicadores trabajen para nosotros sin necesidad de estar presentes en el gráfico, esto mediante una programación especial dentro del código del indicador que realizará compras y ventas automáticas en nuestro Exchange de preferencia mediante una alerta configurada para el bot 3Commas. Solo bastará con que pongamos nuestro número de Bot o Bot ID que da el proveedor de 3Commas y lo insertemos en la alerta. Todos los indicadores premium tienen en su configuración una explicación detallada sobre dónde poner tus Bot ID.
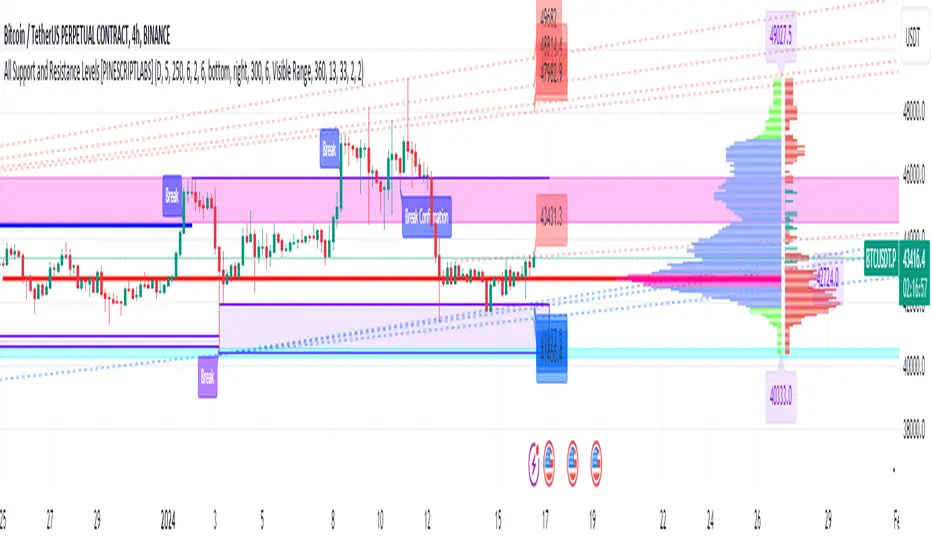
Normalized, Variety, Fast Fourier Transform Explorer [Loxx]Normalized, Variety, Fast Fourier Transform Explorer demonstrates Real, Cosine, and Sine Fast Fourier Transform algorithms. This indicator can be used as a rule of thumb but shouldn't be used in trading.
What is the Discrete Fourier Transform?
In mathematics, the discrete Fourier transform (DFT) converts a finite sequence of equally-spaced samples of a function into a same-length sequence of equally-spaced samples of the discrete-time Fourier transform (DTFT), which is a complex-valued function of frequency. The interval at which the DTFT is sampled is the reciprocal of the duration of the input sequence. An inverse DFT is a Fourier series, using the DTFT samples as coefficients of complex sinusoids at the corresponding DTFT frequencies. It has the same sample-values as the original input sequence. The DFT is therefore said to be a frequency domain representation of the original input sequence. If the original sequence spans all the non-zero values of a function, its DTFT is continuous (and periodic), and the DFT provides discrete samples of one cycle. If the original sequence is one cycle of a periodic function, the DFT provides all the non-zero values of one DTFT cycle.
What is the Complex Fast Fourier Transform?
The complex Fast Fourier Transform algorithm transforms N real or complex numbers into another N complex numbers. The complex FFT transforms a real or complex signal x in the time domain into a complex two-sided spectrum X in the frequency domain. You must remember that zero frequency corresponds to n = 0, positive frequencies 0 < f < f_c correspond to values 1 ≤ n ≤ N/2 −1, while negative frequencies −fc < f < 0 correspond to N/2 +1 ≤ n ≤ N −1. The value n = N/2 corresponds to both f = f_c and f = −f_c. f_c is the critical or Nyquist frequency with f_c = 1/(2*T) or half the sampling frequency. The first harmonic X corresponds to the frequency 1/(N*T).
The complex FFT requires the list of values (resolution, or N) to be a power 2. If the input size if not a power of 2, then the input data will be padded with zeros to fit the size of the closest power of 2 upward.
What is Real-Fast Fourier Transform?
Has conditions similar to the complex Fast Fourier Transform value, except that the input data must be purely real. If the time series data has the basic type complex64, only the real parts of the complex numbers are used for the calculation. The imaginary parts are silently discarded.
What is the Real-Fast Fourier Transform?
In many applications, the input data for the DFT are purely real, in which case the outputs satisfy the symmetry
X(N-k)=X(k)
and efficient FFT algorithms have been designed for this situation (see e.g. Sorensen, 1987). One approach consists of taking an ordinary algorithm (e.g. Cooley–Tukey) and removing the redundant parts of the computation, saving roughly a factor of two in time and memory. Alternatively, it is possible to express an even-length real-input DFT as a complex DFT of half the length (whose real and imaginary parts are the even/odd elements of the original real data), followed by O(N) post-processing operations.
It was once believed that real-input DFTs could be more efficiently computed by means of the discrete Hartley transform (DHT), but it was subsequently argued that a specialized real-input DFT algorithm (FFT) can typically be found that requires fewer operations than the corresponding DHT algorithm (FHT) for the same number of inputs. Bruun's algorithm (above) is another method that was initially proposed to take advantage of real inputs, but it has not proved popular.
There are further FFT specializations for the cases of real data that have even/odd symmetry, in which case one can gain another factor of roughly two in time and memory and the DFT becomes the discrete cosine/sine transform(s) (DCT/DST). Instead of directly modifying an FFT algorithm for these cases, DCTs/DSTs can also be computed via FFTs of real data combined with O(N) pre- and post-processing.
What is the Discrete Cosine Transform?
A discrete cosine transform ( DCT ) expresses a finite sequence of data points in terms of a sum of cosine functions oscillating at different frequencies. The DCT , first proposed by Nasir Ahmed in 1972, is a widely used transformation technique in signal processing and data compression. It is used in most digital media, including digital images (such as JPEG and HEIF, where small high-frequency components can be discarded), digital video (such as MPEG and H.26x), digital audio (such as Dolby Digital, MP3 and AAC ), digital television (such as SDTV, HDTV and VOD ), digital radio (such as AAC+ and DAB+), and speech coding (such as AAC-LD, Siren and Opus). DCTs are also important to numerous other applications in science and engineering, such as digital signal processing, telecommunication devices, reducing network bandwidth usage, and spectral methods for the numerical solution of partial differential equations.
The use of cosine rather than sine functions is critical for compression, since it turns out (as described below) that fewer cosine functions are needed to approximate a typical signal, whereas for differential equations the cosines express a particular choice of boundary conditions. In particular, a DCT is a Fourier-related transform similar to the discrete Fourier transform (DFT), but using only real numbers. The DCTs are generally related to Fourier Series coefficients of a periodically and symmetrically extended sequence whereas DFTs are related to Fourier Series coefficients of only periodically extended sequences. DCTs are equivalent to DFTs of roughly twice the length, operating on real data with even symmetry (since the Fourier transform of a real and even function is real and even), whereas in some variants the input and/or output data are shifted by half a sample. There are eight standard DCT variants, of which four are common.
The most common variant of discrete cosine transform is the type-II DCT , which is often called simply "the DCT". This was the original DCT as first proposed by Ahmed. Its inverse, the type-III DCT , is correspondingly often called simply "the inverse DCT" or "the IDCT". Two related transforms are the discrete sine transform ( DST ), which is equivalent to a DFT of real and odd functions, and the modified discrete cosine transform (MDCT), which is based on a DCT of overlapping data. Multidimensional DCTs ( MD DCTs) are developed to extend the concept of DCT to MD signals. There are several algorithms to compute MD DCT . A variety of fast algorithms have been developed to reduce the computational complexity of implementing DCT . One of these is the integer DCT (IntDCT), an integer approximation of the standard DCT ,: ix, xiii, 1, 141–304 used in several ISO /IEC and ITU-T international standards.
What is the Discrete Sine Transform?
In mathematics, the discrete sine transform (DST) is a Fourier-related transform similar to the discrete Fourier transform (DFT), but using a purely real matrix. It is equivalent to the imaginary parts of a DFT of roughly twice the length, operating on real data with odd symmetry (since the Fourier transform of a real and odd function is imaginary and odd), where in some variants the input and/or output data are shifted by half a sample.
A family of transforms composed of sine and sine hyperbolic functions exists. These transforms are made based on the natural vibration of thin square plates with different boundary conditions.
The DST is related to the discrete cosine transform (DCT), which is equivalent to a DFT of real and even functions. See the DCT article for a general discussion of how the boundary conditions relate the various DCT and DST types. Generally, the DST is derived from the DCT by replacing the Neumann condition at x=0 with a Dirichlet condition. Both the DCT and the DST were described by Nasir Ahmed T. Natarajan and K.R. Rao in 1974. The type-I DST (DST-I) was later described by Anil K. Jain in 1976, and the type-II DST (DST-II) was then described by H.B. Kekra and J.K. Solanka in 1978.
Notable settings
windowper = period for calculation, restricted to powers of 2: "16", "32", "64", "128", "256", "512", "1024", "2048", this reason for this is FFT is an algorithm that computes DFT (Discrete Fourier Transform) in a fast way, generally in 𝑂(𝑁⋅log2(𝑁)) instead of 𝑂(𝑁2). To achieve this the input matrix has to be a power of 2 but many FFT algorithm can handle any size of input since the matrix can be zero-padded. For our purposes here, we stick to powers of 2 to keep this fast and neat. read more about this here: Cooley–Tukey FFT algorithm
SS = smoothing count, this smoothing happens after the first FCT regular pass. this zeros out frequencies from the previously calculated values above SS count. the lower this number, the smoother the output, it works opposite from other smoothing periods
Fmin1 = zeroes out frequencies not passing this test for min value
Fmax1 = zeroes out frequencies not passing this test for max value
barsback = moves the window backward
Inverse = whether or not you wish to invert the FFT after first pass calculation
Related indicators
Real-Fast Fourier Transform of Price Oscillator
STD-Stepped Fast Cosine Transform Moving Average
Real-Fast Fourier Transform of Price w/ Linear Regression
Variety RSI of Fast Discrete Cosine Transform
Additional reading
A Fast Computational Algorithm for the Discrete Cosine Transform by Chen et al.
Practical Fast 1-D DCT Algorithms With 11 Multiplications by Loeffler et al.
Cooley–Tukey FFT algorithm
Ahmed, Nasir (January 1991). "How I Came Up With the Discrete Cosine Transform". Digital Signal Processing. 1 (1): 4–5. doi:10.1016/1051-2004(91)90086-Z.
DCT-History - How I Came Up With The Discrete Cosine Transform
Comparative Analysis for Discrete Sine Transform as a suitable method for noise estimation

Helme-Nikias Weighted Burg AR-SE Extra. of Price [Loxx]Helme-Nikias Weighted Burg AR-SE Extra. of Price is an indicator that uses an autoregressive spectral estimation called the Weighted Burg Algorithm, but unlike the usual WB algo, this one uses Helme-Nikias weighting. This method is commonly used in speech modeling and speech prediction engines. This is a linear method of forecasting data. You'll notice that this method uses a different weighting calculation vs Weighted Burg method. This new weighting is the following:
w = math.pow(array.get(x, i - 1), 2), the squared lag of the source parameter
and
w += math.pow(array.get(x, i), 2), the sum of the squared source parameter
This take place of the rectangular, hamming and parabolic weighting used in the Weighted Burg method
Also, this method includes Levinson–Durbin algorithm. as was already discussed previously in the following indicator:
Levinson-Durbin Autocorrelation Extrapolation of Price
What is Helme-Nikias Weighted Burg Autoregressive Spectral Estimate Extrapolation of price?
In this paper a new stable modification of the weighted Burg technique for autoregressive (AR) spectral estimation is introduced based on data-adaptive weights that are proportional to the common power of the forward and backward AR process realizations. It is shown that AR spectra of short length sinusoidal signals generated by the new approach do not exhibit phase dependence or line-splitting. Further, it is demonstrated that improvements in resolution may be so obtained relative to other weighted Burg algorithms. The method suggested here is shown to resolve two closely-spaced peaks of dynamic range 24 dB whereas the modified Burg schemes employing rectangular, Hamming or "optimum" parabolic windows fail.
Data inputs
Source Settings: -Loxx's Expanded Source Types. You typically use "open" since open has already closed on the current active bar
LastBar - bar where to start the prediction
PastBars - how many bars back to model
LPOrder - order of linear prediction model; 0 to 1
FutBars - how many bars you want to forward predict
Things to know
Normally, a simple moving average is calculated on source data. I've expanded this to 38 different averaging methods using Loxx's Moving Avreages.
This indicator repaints
Further reading
A high-resolution modified Burg algorithm for spectral estimation
Related Indicators
Levinson-Durbin Autocorrelation Extrapolation of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Dresteghamat:Adaptive Multi-TF Decision Engine**Dresteghamat: Adaptive Multi-Timeframe Decision Engine**
This open-source indicator is an algorithmic decision-support system designed to filter market noise by quantifying three core market dimensions: **Regime**, **Direction**, and **Exhaustion**.
**⚠️ Technical Note on Originality:**
This script solves the "Timeframe Irrelevance" problem found in standard dashboards. Instead of using static HTF references, it implements a custom **"Adaptive Context Engine"** (see lines 245-270 in source code). It calculates the user's current `timeframe.multiplier` and dynamically maps the mathematically relevant Higher Timeframes.
* *Innovation:* A 5m chart automatically weights 15m/1H structure, whereas a 1H chart weights 4H/Daily structure. This dynamic logic is proprietary and ensures contextual accuracy.
---
### 🛠️ Logic & Calculation Methodology
The script does not simply overlay indicators. It processes raw market data through a **Weighted Scoring Engine** (lines 275-285) to output a unified market state.
**1. Regime Identification (Volatility Normalized)**
We calculate a custom "Volatility Ratio" to distinguish Trend vs. Range regimes.
* **Logic:** `Range / Smoothed_ATR`.
* **Function:** If Ratio > 2.0, the market is in Expansion (Trend). If < 1.2, it is in Compression (Range). This normalizes volatility across assets (Crypto/Forex/Stocks).
**2. Directional Bias (Composite Metric)**
Direction is calculated via a voting system of three sub-components (lines 80-130):
* **Structural Pivots:** Detects Swing Highs/Lows using a 25-bar lookback to define market structure.
* **Cumulative Body Delta:** Tracks the net buying/selling pressure within candle bodies.
* **Micro-Flow:** A short-term (5-bar) momentum filter to detect immediate order flow shifts.
**3. Exhaustion Model (Risk Management)**
The script prevents late entries by calculating an "Exhaustion Score" (lines 150-200). It aggregates:
* **VRSD (Volatility Regime Shift):** Detects when volatility expands > 2 standard deviations (Mean Reversion risk).
* **Volume Decay (VEFF):** Identifies Divergence where price makes new highs on declining Volume MA.
* **RSI/Impulse Divergence:** Standard momentum divergence logic.
**4. The Decision Output (MODE)**
The dashboard renders a final signal based on a hierarchical algorithm:
* **BUY/SELL ONLY:** Triggered when Current Momentum aligns with the Dynamically Selected HTF Structure AND the Exhaustion Score is low.
* **PULLBACK:** Triggered when HTF Structure is bullish, but Current Momentum is bearish (indicating a corrective phase).
* **HTF EXHAUST:** Overrides signals when the Higher Timeframe metrics hit extreme levels.
* **WAIT:** Default state during Range Regimes or conflicting signals.
---
### 📊 Usage Guide
1. Apply to chart (Auto-adapts to any timeframe).
2. **Status Column:** Shows the raw health of the trend (Strong/Weakening/Exhausted).
3. **MODE Column:** Displays the final actionable bias based on the scoring algorithm.
**Disclaimer:** This tool provides statistical analysis based on historical data. It does not guarantee future results.

SMC - Institutional Confidence Oscillator [PhenLabs]📊 Institutional Confidence Oscillator
Version: PineScript™v6
📌 Description
The Institutional Confidence Oscillator (ICO) revolutionizes market analysis by automatically detecting and evaluating institutional activity at key support and resistance levels using our own in-house detection system. This sophisticated indicator combines volume analysis, volatility measurements, and mathematical confidence algorithms to provide real-time readings of institutional sentiment and zone strength.
Using our advanced thin liquidity detection, the ICO identifies high-volume, narrow-range bars that signal institutional zone formation, then tracks how these zones perform under market pressure. The result is a dual-wave confidence oscillator that shows traders when institutions are actively defending price levels versus when they’re abandoning positions.
The indicator transforms complex institutional behavior patterns into clear, actionable confidence percentiles, helping traders align with smart money movements and avoid common retail trading pitfalls.
🚀 Points of Innovation
Automated thin liquidity zone detection using volume threshold multipliers and zone size filtering
Dual-sided confidence tracking for both support and resistance levels simultaneously
Sigmoid function processing for enhanced mathematical accuracy in confidence calculations
Real-time institutional defense pattern analysis through complete test cycles
Advanced visual smoothing options with multiple algorithmic methods (EMA, SMA, WMA, ALMA)
Integrated momentum indicators and gradient visualization for enhanced signal clarity
🔧 Core Components
Volume Threshold System: Analyzes volume ratios against baseline averages to identify institutional activity spikes
Zone Detection Algorithm: Automatically identifies thin liquidity zones based on customizable volume and size parameters
Confidence Lifecycle Engine: Tracks institutional defense patterns through complete observation windows
Mathematical Processing Core: Uses sigmoid functions to convert raw market data into normalized confidence percentiles
Visual Enhancement Suite: Provides multiple smoothing methods and customizable display options for optimal chart interpretation
🔥 Key Features
Auto-Detection Technology: Automatically scans for institutional zones without manual intervention, saving analysis time
Dual Confidence Tracking: Simultaneously monitors both support and resistance institutional activity for comprehensive market view
Smart Zone Validation: Evaluates zone strength through volume analysis, adverse excursion measurement, and defense success rates
Customizable Parameters: Extensive input options for volume thresholds, observation windows, and visual preferences
Real-Time Updates: Continuously processes market data to provide current institutional confidence readings
Enhanced Visualization: Features gradient fills, momentum indicators, and information panels for clear signal interpretation
🎨 Visualization
Dual Oscillator Lines: Support confidence (cyan) and resistance confidence (red) plotted as percentage values 0-100%
Gradient Fill Areas: Color-coded regions showing confidence dominance and strength levels
Reference Grid Lines: Horizontal markers at 25%, 50%, and 75% levels for easy interpretation
Information Panel: Real-time display of current confidence percentiles with color-coded dominance indicators
Momentum Indicators: Rate of change visualization for confidence trends
Background Highlights: Extreme confidence level alerts when readings exceed 80%
📖 Usage Guidelines
Auto-Detection Settings
Use Auto-Detection
Default: true
Description: Enables automatic thin liquidity zone identification based on volume and size criteria
Volume Threshold Multiplier
Default: 6.0, Range: 1.0+
Description: Controls sensitivity of volume spike detection for zone identification, higher values require more significant volume increases
Volume MA Length
Default: 15, Range: 1+
Description: Period for volume moving average baseline calculation, affects volume spike sensitivity
Max Zone Height %
Default: 0.5%, Range: 0.05%+
Description: Filters out wide price bars, keeping only thin liquidity zones as percentage of current price
Confidence Logic Settings
Test Observation Window
Default: 20 bars, Range: 2+
Description: Number of bars to monitor zone tests for confidence calculation, longer windows provide more stable readings
Clean Break Threshold
Default: 1.5 ATR, Range: 0.1+
Description: ATR multiple required for zone invalidation, higher values make zones more persistent
Visual Settings
Smoothing Method
Default: EMA, Options: SMA/EMA/WMA/ALMA
Description: Algorithm for signal smoothing, EMA responds faster while SMA provides more stability
Smoothing Length
Default: 5, Range: 1-50
Description: Period for smoothing calculation, higher values create smoother lines with more lag
✅ Best Use Cases
Trending market analysis where institutional zones provide reliable support/resistance levels
Breakout confirmation by validating zone strength before position entry
Divergence analysis when confidence shifts between support and resistance levels
Risk management through identification of high-confidence institutional backing
Market structure analysis for understanding institutional sentiment changes
⚠️ Limitations
Performs best in liquid markets with clear institutional participation
May produce false signals during low-volume or holiday trading periods
Requires sufficient price history for accurate confidence calculations
Confidence readings can fluctuate rapidly during high-impact news events
Manual fallback zones may not reflect actual institutional activity
💡 What Makes This Unique
Automated Detection: First Pine Script indicator to automatically identify thin liquidity zones using sophisticated volume analysis
Dual-Sided Analysis: Simultaneously tracks institutional confidence for both support and resistance levels
Mathematical Precision: Uses sigmoid functions for enhanced accuracy in confidence percentage calculations
Real-Time Processing: Continuously evaluates institutional defense patterns as market conditions change
Visual Innovation: Advanced smoothing options and gradient visualization for superior chart clarity
🔬 How It Works
1. Zone Identification Process:
Scans for high-volume bars that exceed the volume threshold multiplier
Filters bars by maximum zone height percentage to identify thin liquidity conditions
Stores qualified zones with proximity threshold filtering for relevance
2. Confidence Calculation Process:
Monitors price interaction with identified zones during observation windows
Measures volume ratios and adverse excursions during zone tests
Applies sigmoid function processing to normalize raw data into confidence percentiles
3. Real-Time Analysis Process:
Continuously updates confidence readings as new market data becomes available
Tracks institutional defense success rates and zone validation patterns
Provides visual and numerical feedback through the oscillator display
💡 Note:
The ICO works best when combined with traditional technical analysis and proper risk management. Higher confidence readings indicate stronger institutional backing but should be confirmed with price action and volume analysis. Consider using multiple timeframes for comprehensive market structure understanding.
Ocs Ai TraderThis script perform predictive analytics from a virtual trader perspective!
It acts as an AI Trade Assistant that helps you decide the optimal times to buy or sell securities, providing you with precise target prices and stop-loss level to optimise your gains and manage risk effectively.
System Components
The trading system is built on 4 fundamental layers :
Time series Processing layer
Signal Processing layer
Machine Learning
Virtual Trade Emulator
Time series Processing layer
This is first component responsible for handling and processing real-time and historical time series data.
In this layer Signals are extracted from
averages such as : volume price mean, adaptive moving average
Estimates such as : relative strength stochastics estimates on supertrend
Signal Processing layer
This second layer processes signals from previous layer using sensitivity filter comprising of an Probability Distribution Confidence Filter
The main purpose here is to predict the trend of the underlying, by converging price, volume signals and deltas over a dominant cycle as dimensions and generate signals of action.
Key terms
Dominant cycle is a time cycle that has a greater influence on the overall behaviour of a system than other cycles.
The system uses Ehlers method to calculate Dominant Cycle/ Period.
Dominant cycle is used to determine the influencing period for the underlying.
Once the dominant cycle/ period is identified, it is treated as a dynamic length for considering further calculations
Predictive Adaptive Filter to generate Signals and define Targets and Stops
An adaptive filter is a system with a linear filter that has a transfer function controlled by variable parameters and a means to adjust those parameters according to an optimisation algorithm. Because of the complexity of the optimisation algorithms, almost all adaptive filters are digital filters. Thus Helping us classify our intent either long side or short side
The indicator use Adaptive Least mean square algorithm, for convergence of the filtered signals into a category of intents, (either buy or sell)
Machine Learning
The third layer of the System performs classifications using KNN K-Nearest Neighbour is one of the simplest Machine Learning algorithms based on Supervised Learning technique.
K-NN algorithm assumes the similarity between the new case/data and available cases and put the new case into the category that is most similar to the available categories.
K-NN algorithm stores all the available data and classifies a new data point based on the similarity. This means when new data appears then it can be easily classified into a well suite category by using K- NN algorithm. K-NN algorithm can be used for Regression as well as for Classification but mostly it is used for the Classification problems.
Virtual Trade Emulator
In this last and fourth layer a trade assistant is coded using trade emulation techniques and the Lines and Labels for Buy / Sell Signals, Targets and Stop are forecasted!
How to use
The system generates Buy and Sell alerts and plots it on charts
Buy signal
Buy signal constitutes of three targets {namely T1, T2, T3} and one stop level
Sell signal
Sell signal constitutes of three targets {namely T1, T2, T3} and one stop level
What Securities will it work upon ?
Volume Informations must be present for the applied security
The indicator works on every liquid security : stocks, future, forex, crypto, options, commodities
What TimeFrames To Use ?
You can use any Timeframe, The indicator is Adaptive in Nature,
I personally use timeframes such as : 1m, 5m 10m, 15m, ..... 1D, 1W
This Script Uses Tradingview Premium features for working on lower timeframes
In case if you are not a Tradingview premium subscriber you should tell the script that after applying on chart, this can be done by going to settings and unchecking "Is your Tradingview Subscription Premium or Above " Option
How To Get Access ?
You will need to privately message me for access mentioning you want access to "Ocs Ai Trader" Use comment box only for constructive comments. Thanks !

Bist Manipulation [Projeadam]
OVERVIEW | GENEL BAKIŞ
ENG: Indicator that detects manipulation candles according to changing market conditions.
TR: Değişen piyasa koşullarına göre manipülasyon mumlarını tespit eden gösterge.
ENG: IMPORTANT NOTE: This indicator works in BIST Market and only in Future Parities.
Example ->> PETKM1! --SASA1!
TR: ÖNEMLİ NOT: Bu indikatör BİST Piyasasında ve sadece Future Paritelerde Çalışır.
Örnek- >> PETKM1! -- SASA1!
ENG: Market makers manipulate the market because most people who trade on the stock exchange act with their emotions and are forced to close the transaction at a loss.
TR: Piyasada market yapıcı oluşumlar manipülasyon yaparlar çünkü borsada işlem alan insanların birçoğu duygularıyla hareket eder ve zararla işlem kapatılmaya zorlanır.
ENG: If we detect manipulation candles in the market, we can control our fragile psychology and close our transactions in profit by trading with market-making formations in these areas.
TR: Marketde manipülasyon mumlarını tespit edersek kırılgan psikolojimizi kontrol edebilir ve bu alanlardan market yapıcı oluşumlarla beraber işlem alarak işlemlerimizi karda kapatabiliriz.
ALGORITHM | ALGORİTMA
ENG: With the help of this indicator, you can detect manipulation candles in the BIST exchange with the help of the algorithm I created by using volumetric data and wicks created by the price.
When there is excessive volatility in price movement, the algorithm in this indicator notices this price volatility and calculates a manipulation value by dividing it by the volatility value in past price movements.
TR: Bu indikatör yardımıyla hacimsel veriler ve fiyatın oluşturduğu fitillerden yararlanarak oluşturduğum algoritma yardımıyla siz de BİST borsasında manipülasyon mumlarını tespit edebilirsiniz.
Fiyat hareketinde aşırı derece oynaklık olduğunda bu indikatördeki algoritma bu fiyat oynaklığını fark eder ve geçmiş fiyat hareketlerindeki oylanklık degerine bölerek bize bir manipülasyon degeri hesaplar.
How does the indicator work? | Gösterge nasıl çalışır?
ENG: The manipulation candle does not give us information about the direction of price movement, it is only used as an auxiliary indicator.
TR: Manipülasyon mumu bize fiyat hareketinin yönü hakkında bilgi vermez sadece yardımcı bir gösterge olarak kullanılır.
ENG: We show our manipulation values as columns. We draw a channel over the values we show and we understand that there is manipulation in the candle of our values above this channel.
TR: Manipülasyon degerlerimiz kolonlar şeklinde gösteriyoruz. Gösterdiğimiz değerlerimizin üzerine bir kanal çizdiriyoruz ve bu kanalın üzerinde kalan değerlerimizdeki mumda manipülasyon yapıldığını anlıyoruz.
ENG: The indicator shows the manipulation value in the form of columns. Our manipulation value that goes outside the channel we have determined is colored red, within the channel it is colored yellow, and below the channel it is colored green. Red columns indicate candles that are manipulations.
TR: İndikatör manipülasyon degerini kolonlar şeklinde gösteriyor. Bizim belirlediğimiz kanal dışına çıkan manipülasyon degerimiz kırmızı, kanal içerisinde sarı, kanal altında yeşil olarak renklendiriliyor. Kırmızı kolonlar manipülasyon olan mumları göstermektedir.
Example | Örnek
ENG: In our example above, we see a manipulation candle that clears the price gaps, while the market maker clears the orders in the price gaps at the bottom to move the price up.
TR: Yukarıdaki örneğimizde oluşan fiyat boşluklarını temizleyen bir manipülasyon mumu görmekteyiz, alt kısımdaki fiyat boşluklarındaki emirleri temizleyen market maker fiyatı yukarı taşımak için buradaki emirleri temizliyor.
SETTINGS PANEL | AYARLAR PANELİ
ENG: We have only one setting in this indicator.
TR: Bu indikatörde tek ayarımız vardır.
ENG: Our multiplier value determines the width of the band value formed above our manipulation value. In the chart above, our multiplier value is 3.3. If we reduce our multiplier value, our manipulation sensitivity will decrease as there will be much more candles on the band.
TR: Çarpan değerimiz manipülasyon değerimizin üstünde oluşşan band değerinin genişliğini belirlemektedir.Yukarıdaki grafikte çarpan değerimiz 3.3, Eğer çarpan değerimizi azaltırsak band üstünde çok daha fazla mum olacağı için manipülasyon hassasiyetimiz azalacaktır.
ENG: When we set our multiplier value to 2.3, we have a more sensitive manipulation skin and it gives signals in more candles.
TR: Çarpan değerimizi 2.3 yapınca daha hassas manipülasyon derimiz oluyor ve daha fazla mumda sinyal veriyor.
If you have any ideas what to add to my work to add more sources or make calculations cooler, suggest in DM .
AI Moving Average (Expo)█ Overview
The AI Moving Average indicator is a trading tool that uses an AI-based K-nearest neighbors (KNN) algorithm to analyze and interpret patterns in price data. It combines the logic of a traditional moving average with artificial intelligence, creating an adaptive and robust indicator that can identify strong trends and key market levels.
█ How It Works
The algorithm collects data points and applies a KNN-weighted approach to classify price movement as either bullish or bearish. For each data point, the algorithm checks if the price is above or below the calculated moving average. If the price is above the moving average, it's labeled as bullish (1), and if it's below, it's labeled as bearish (0). The K-Nearest Neighbors (KNN) is an instance-based learning algorithm used in classification and regression tasks. It works on a principle of voting, where a new data point is classified based on the majority label of its 'k' nearest neighbors.
The algorithm's use of a KNN-weighted approach adds a layer of intelligence to the traditional moving average analysis. By considering not just the price relative to a moving average but also taking into account the relationships and similarities between different data points, it offers a nuanced and robust classification of price movements.
This combination of data collection, labeling, and KNN-weighted classification turns the AI Moving Average (Expo) Indicator into a dynamic tool that can adapt to changing market conditions, making it suitable for various trading strategies and market environments.
█ How to Use
Dynamic Trend Recognition
The color-coded moving average line helps traders quickly identify market trends. Green represents bullish, red for bearish, and blue for neutrality.
Trend Strength
By adjusting certain settings within the AI Moving Average (Expo) Indicator, such as using a higher 'k' value and increasing the number of data points, traders can gain real-time insights into strong trends. A higher 'k' value makes the prediction model more resilient to noise, emphasizing pronounced trends, while more data points provide a comprehensive view of the market direction. Together, these adjustments enable the indicator to display only robust trends on the chart, allowing traders to focus exclusively on significant market movements and strong trends.
Key SR Levels
Traders can utilize the indicator to identify key support and resistance levels that are derived from the prevailing trend movement. The derived support and resistance levels are not just based on historical data but are dynamically adjusted with the current trend, making them highly responsive to market changes.
█ Settings
k (Neighbors): Number of neighbors in the KNN algorithm. Increasing 'k' makes predictions more resilient to noise but may decrease sensitivity to local variations.
n (DataPoints): Number of data points considered in AI analysis. This affects how the AI interprets patterns in the price data.
maType (Select MA): Type of moving average applied. Options allow for different smoothing techniques to emphasize or dampen aspects of price movement.
length: Length of the moving average. A greater length creates a smoother curve but might lag recent price changes.
dataToClassify: Source data for classifying price as bullish or bearish. It can be adjusted to consider different aspects of price information
dataForMovingAverage: Source data for calculating the moving average. Different selections may emphasize different aspects of price movement.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

Adaptivity: Measures of Dominant Cycles and Price Trend [Loxx]Adaptivity: Measures of Dominant Cycles and Price Trend is an indicator that outputs adaptive lengths using various methods for dominant cycle and price trend timeframe adaptivity. While the information output from this indicator might be useful for the average trader in one off circumstances, this indicator is really meant for those need a quick comparison of dynamic length outputs who wish to fine turn algorithms and/or create adaptive indicators.
This indicator compares adaptive output lengths of all publicly known adaptive measures. Additional adaptive measures will be added as they are discovered and made public.
The first released of this indicator includes 6 measures. An additional three measures will be added with updates. Please check back regularly for new measures.
Ehers:
Autocorrelation Periodogram
Band-pass
Instantaneous Cycle
Hilbert Transformer
Dual Differentiator
Phase Accumulation (future release)
Homodyne (future release)
Jurik:
Composite Fractal Behavior (CFB)
Adam White:
Veritical Horizontal Filter (VHF) (future release)
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman's adaptive moving average (KAMA) and Tushar Chande's variable index dynamic average (VIDYA) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index (RSI), commodity channel index (CCI), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
What is this Hilbert Transformer?
An analytic signal allows for time-variable parameters and is a generalization of the phasor concept, which is restricted to time-invariant amplitude, phase, and frequency. The analytic representation of a real-valued function or signal facilitates many mathematical manipulations of the signal. For example, computing the phase of a signal or the power in the wave is much simpler using analytic signals.
The Hilbert transformer is the technique to create an analytic signal from a real one. The conventional Hilbert transformer is theoretically an infinite-length FIR filter. Even when the filter length is truncated to a useful but finite length, the induced lag is far too large to make the transformer useful for trading.
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, pages 186-187:
"I want to emphasize that the only reason for including this section is for completeness. Unless you are interested in research, I suggest you skip this section entirely. To further emphasize my point, do not use the code for trading. A vastly superior approach to compute the dominant cycle in the price data is the autocorrelation periodogram. The code is included because the reader may be able to capitalize on the algorithms in a way that I do not see. All the algorithms encapsulated in the code operate reasonably well on theoretical waveforms that have no noise component. My conjecture at this time is that the sample-to-sample noise simply swamps the computation of the rate change of phase, and therefore the resulting calculations to find the dominant cycle are basically worthless.The imaginary component of the Hilbert transformer cannot be smoothed as was done in the Hilbert transformer indicator because the smoothing destroys the orthogonality of the imaginary component."
What is the Dual Differentiator, a subset of Hilbert Transformer?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 187:
"The first algorithm to compute the dominant cycle is called the dual differentiator. In this case, the phase angle is computed from the analytic signal as the arctangent of the ratio of the imaginary component to the real component. Further, the angular frequency is defined as the rate change of phase. We can use these facts to derive the cycle period."
What is the Phase Accumulation, a subset of Hilbert Transformer?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 189:
"The next algorithm to compute the dominant cycle is the phase accumulation method. The phase accumulation method of computing the dominant cycle is perhaps the easiest to comprehend. In this technique, we measure the phase at each sample by taking the arctangent of the ratio of the quadrature component to the in-phase component. A delta phase is generated by taking the difference of the phase between successive samples. At each sample we can then look backwards, adding up the delta phases.When the sum of the delta phases reaches 360 degrees, we must have passed through one full cycle, on average.The process is repeated for each new sample.
The phase accumulation method of cycle measurement always uses one full cycle's worth of historical data.This is both an advantage and a disadvantage.The advantage is the lag in obtaining the answer scales directly with the cycle period.That is, the measurement of a short cycle period has less lag than the measurement of a longer cycle period. However, the number of samples used in making the measurement means the averaging period is variable with cycle period. longer averaging reduces the noise level compared to the signal.Therefore, shorter cycle periods necessarily have a higher out- put signal-to-noise ratio."
What is the Homodyne, a subset of Hilbert Transformer?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 192:
"The third algorithm for computing the dominant cycle is the homodyne approach. Homodyne means the signal is multiplied by itself. More precisely, we want to multiply the signal of the current bar with the complex value of the signal one bar ago. The complex conjugate is, by definition, a complex number whose sign of the imaginary component has been reversed."
What is the Instantaneous Cycle?
The Instantaneous Cycle Period Measurement was authored by John Ehlers; it is built upon his Hilbert Transform Indicator.
From his Ehlers' book Cybernetic Analysis for Stocks and Futures: Cutting-Edge DSP Technology to Improve Your Trading by John F. Ehlers, 2004, page 107:
"It is obvious that cycles exist in the market. They can be found on any chart by the most casual observer. What is not so clear is how to identify those cycles in real time and how to take advantage of their existence. When Welles Wilder first introduced the relative strength index (rsi), I was curious as to why he selected 14 bars as the basis of his calculations. I reasoned that if i knew the correct market conditions, then i could make indicators such as the rsi adaptive to those conditions. Cycles were the answer. I knew cycles could be measured. Once i had the cyclic measurement, a host of automatically adaptive indicators could follow.
Measurement of market cycles is not easy. The signal-to-noise ratio is often very low, making measurement difficult even using a good measurement technique. Additionally, the measurements theoretically involve simultaneously solving a triple infinity of parameter values. The parameters required for the general solutions were frequency, amplitude, and phase. Some standard engineering tools, like fast fourier transforms (ffs), are simply not appropriate for measuring market cycles because ffts cannot simultaneously meet the stationarity constraints and produce results with reasonable resolution. Therefore i introduced maximum entropy spectral analysis (mesa) for the measurement of market cycles. This approach, originally developed to interpret seismographic information for oil exploration, produces high-resolution outputs with an exceptionally short amount of information. A short data length improves the probability of having nearly stationary data. Stationary data means that frequency and amplitude are constant over the length of the data. I noticed over the years that the cycles were ephemeral. Their periods would be continuously increasing and decreasing. Their amplitudes also were changing, giving variable signal-to-noise ratio conditions. Although all this is going on with the cyclic components, the enduring characteristic is that generally only one tradable cycle at a time is present for the data set being used. I prefer the term dominant cycle to denote that one component. The assumption that there is only one cycle in the data collapses the difficulty of the measurement process dramatically."
What is the Band-pass Cycle?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 47:
"Perhaps the least appreciated and most underutilized filter in technical analysis is the band-pass filter. The band-pass filter simultaneously diminishes the amplitude at low frequencies, qualifying it as a detrender, and diminishes the amplitude at high frequencies, qualifying it as a data smoother. It passes only those frequency components from input to output in which the trader is interested. The filtering produced by a band-pass filter is superior because the rejection in the stop bands is related to its bandwidth. The degree of rejection of undesired frequency components is called selectivity. The band-stop filter is the dual of the band-pass filter. It rejects a band of frequency components as a notch at the output and passes all other frequency components virtually unattenuated. Since the bandwidth of the deep rejection in the notch is relatively narrow and since the spectrum of market cycles is relatively broad due to systemic noise, the band-stop filter has little application in trading."
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 59:
"The band-pass filter can be used as a relatively simple measurement of the dominant cycle. A cycle is complete when the waveform crosses zero two times from the last zero crossing. Therefore, each successive zero crossing of the indicator marks a half cycle period. We can establish the dominant cycle period as twice the spacing between successive zero crossings."
What is Composite Fractal Behavior (CFB)?
All around you mechanisms adjust themselves to their environment. From simple thermostats that react to air temperature to computer chips in modern cars that respond to changes in engine temperature, r.p.m.'s, torque, and throttle position. It was only a matter of time before fast desktop computers applied the mathematics of self-adjustment to systems that trade the financial markets.
Unlike basic systems with fixed formulas, an adaptive system adjusts its own equations. For example, start with a basic channel breakout system that uses the highest closing price of the last N bars as a threshold for detecting breakouts on the up side. An adaptive and improved version of this system would adjust N according to market conditions, such as momentum, price volatility or acceleration.
Since many systems are based directly or indirectly on cycles, another useful measure of market condition is the periodic length of a price chart's dominant cycle, (DC), that cycle with the greatest influence on price action.
The utility of this new DC measure was noted by author Murray Ruggiero in the January '96 issue of Futures Magazine. In it. Mr. Ruggiero used it to adaptive adjust the value of N in a channel breakout system. He then simulated trading 15 years of D-Mark futures in order to compare its performance to a similar system that had a fixed optimal value of N. The adaptive version produced 20% more profit!
This DC index utilized the popular MESA algorithm (a formulation by John Ehlers adapted from Burg's maximum entropy algorithm, MEM). Unfortunately, the DC approach is problematic when the market has no real dominant cycle momentum, because the mathematics will produce a value whether or not one actually exists! Therefore, we developed a proprietary indicator that does not presuppose the presence of market cycles. It's called CFB (Composite Fractal Behavior) and it works well whether or not the market is cyclic.
CFB examines price action for a particular fractal pattern, categorizes them by size, and then outputs a composite fractal size index. This index is smooth, timely and accurate
Essentially, CFB reveals the length of the market's trending action time frame. Long trending activity produces a large CFB index and short choppy action produces a small index value. Investors have found many applications for CFB which involve scaling other existing technical indicators adaptively, on a bar-to-bar basis.
What is VHF Adaptive Cycle?
Vertical Horizontal Filter (VHF) was created by Adam White to identify trending and ranging markets. VHF measures the level of trend activity, similar to ADX DI. Vertical Horizontal Filter does not, itself, generate trading signals, but determines whether signals are taken from trend or momentum indicators. Using this trend information, one is then able to derive an average cycle length.

Monte Carlo Range Forecast [DW]This is an experimental study designed to forecast the range of price movement from a specified starting point using a Monte Carlo simulation.
Monte Carlo experiments are a broad class of computational algorithms that utilize random sampling to derive real world numerical results.
These types of algorithms have a number of applications in numerous fields of study including physics, engineering, behavioral sciences, climate forecasting, computer graphics, gaming AI, mathematics, and finance.
Although the applications vary, there is a typical process behind the majority of Monte Carlo methods:
-> First, a distribution of possible inputs is defined.
-> Next, values are generated randomly from the distribution.
-> The values are then fed through some form of deterministic algorithm.
-> And lastly, the results are aggregated over some number of iterations.
In this study, the Monte Carlo process used generates a distribution of aggregate pseudorandom linear price returns summed over a user defined period, then plots standard deviations of the outcomes from the mean outcome generate forecast regions.
The pseudorandom process used in this script relies on a modified Wichmann-Hill pseudorandom number generator (PRNG) algorithm.
Wichmann-Hill is a hybrid generator that uses three linear congruential generators (LCGs) with different prime moduli.
Each LCG within the generator produces an independent, uniformly distributed number between 0 and 1.
The three generated values are then summed and modulo 1 is taken to deliver the final uniformly distributed output.
Because of its long cycle length, Wichmann-Hill is a fantastic generator to use on TV since it's extremely unlikely that you'll ever see a cycle repeat.
The resulting pseudorandom output from this generator has a minimum repetition cycle length of 6,953,607,871,644.
Fun fact: Wichmann-Hill is a widely used PRNG in various software applications. For example, Excel 2003 and later uses this algorithm in its RAND function, and it was the default generator in Python up to v2.2.
The generation algorithm in this script takes the Wichmann-Hill algorithm, and uses a multi-stage transformation process to generate the results.
First, a parent seed is selected. This can either be a fixed value, or a dynamic value.
The dynamic parent value is produced by taking advantage of Pine's timenow variable behavior. It produces a variable parent seed by using a frozen ratio of timenow/time.
Because timenow always reflects the current real time when frozen and the time variable reflects the chart's beginning time when frozen, the ratio of these values produces a new number every time the cache updates.
After a parent seed is selected, its value is then fed through a uniformly distributed seed array generator, which generates multiple arrays of pseudorandom "children" seeds.
The seeds produced in this step are then fed through the main generators to produce arrays of pseudorandom simulated outcomes, and a pseudorandom series to compare with the real series.
The main generators within this script are designed to (at least somewhat) model the stochastic nature of financial time series data.
The first step in this process is to transform the uniform outputs of the Wichmann-Hill into outputs that are normally distributed.
In this script, the transformation is done using an estimate of the normal distribution quantile function.
Quantile functions, otherwise known as percent-point or inverse cumulative distribution functions, specify the value of a random variable such that the probability of the variable being within the value's boundary equals the input probability.
The quantile equation for a normal probability distribution is μ + σ(√2)erf^-1(2(p - 0.5)) where μ is the mean of the distribution, σ is the standard deviation, erf^-1 is the inverse Gauss error function, and p is the probability.
Because erf^-1() does not have a simple, closed form interpretation, it must be approximated.
To keep things lightweight in this approximation, I used a truncated Maclaurin Series expansion for this function with precomputed coefficients and rolled out operations to avoid nested looping.
This method provides a decent approximation of the error function without completely breaking floating point limits or sucking up runtime memory.
Note that there are plenty of more robust techniques to approximate this function, but their memory needs very. I chose this method specifically because of runtime favorability.
To generate a pseudorandom approximately normally distributed variable, the uniformly distributed variable from the Wichmann-Hill algorithm is used as the input probability for the quantile estimator.
Now from here, we get a pretty decent output that could be used itself in the simulation process. Many Monte Carlo simulations and random price generators utilize a normal variable.
However, if you compare the outputs of this normal variable with the actual returns of the real time series, you'll find that the variability in shocks (random changes) doesn't quite behave like it does in real data.
This is because most real financial time series data is more complex. Its distribution may be approximately normal at times, but the variability of its distribution changes over time due to various underlying factors.
In light of this, I believe that returns behave more like a convoluted product distribution rather than just a raw normal.
So the next step to get our procedurally generated returns to more closely emulate the behavior of real returns is to introduce more complexity into our model.
Through experimentation, I've found that a return series more closely emulating real returns can be generated in a three step process:
-> First, generate multiple independent, normally distributed variables simultaneously.
-> Next, apply pseudorandom weighting to each variable ranging from -1 to 1, or some limits within those bounds. This modulates each series to provide more variability in the shocks by producing product distributions.
-> Lastly, add the results together to generate the final pseudorandom output with a convoluted distribution. This adds variable amounts of constructive and destructive interference to produce a more "natural" looking output.
In this script, I use three independent normally distributed variables multiplied by uniform product distributed variables.
The first variable is generated by multiplying a normal variable by one uniformly distributed variable. This produces a bit more tailedness (kurtosis) than a normal distribution, but nothing too extreme.
The second variable is generated by multiplying a normal variable by two uniformly distributed variables. This produces moderately greater tails in the distribution.
The third variable is generated by multiplying a normal variable by three uniformly distributed variables. This produces a distribution with heavier tails.
For additional control of the output distributions, the uniform product distributions are given optional limits.
These limits control the boundaries for the absolute value of the uniform product variables, which affects the tails. In other words, they limit the weighting applied to the normally distributed variables in this transformation.
All three sets are then multiplied by user defined amplitude factors to adjust presence, then added together to produce our final pseudorandom return series with a convoluted product distribution.
Once we have the final, more "natural" looking pseudorandom series, the values are recursively summed over the forecast period to generate a simulated result.
This process of generation, weighting, addition, and summation is repeated over the user defined number of simulations with different seeds generated from the parent to produce our array of initial simulated outcomes.
After the initial simulation array is generated, the max, min, mean and standard deviation of this array are calculated, and the values are stored in holding arrays on each iteration to be called upon later.
Reference difference series and price values are also stored in holding arrays to be used in our comparison plots.
In this script, I use a linear model with simple returns rather than compounding log returns to generate the output.
The reason for this is that in generating outputs this way, we're able to run our simulations recursively from the beginning of the chart, then apply scaling and anchoring post-process.
This allows a greater conservation of runtime memory than the alternative, making it more suitable for doing longer forecasts with heavier amounts of simulations in TV's runtime environment.
From our starting time, the previous bar's price, volatility, and optional drift (expected return) are factored into our holding arrays to generate the final forecast parameters.
After these parameters are computed, the range forecast is produced.
The basis value for the ranges is the mean outcome of the simulations that were run.
Then, quarter standard deviations of the simulated outcomes are added to and subtracted from the basis up to 3σ to generate the forecast ranges.
All of these values are plotted and colorized based on their theoretical probability density. The most likely areas are the warmest colors, and least likely areas are the coolest colors.
An information panel is also displayed at the starting time which shows the starting time and price, forecast type, parent seed value, simulations run, forecast bars, total drift, mean, standard deviation, max outcome, min outcome, and bars remaining.
The interesting thing about simulated outcomes is that although the probability distribution of each simulation is not normal, the distribution of different outcomes converges to a normal one with enough steps.
In light of this, the probability density of outcomes is highest near the initial value + total drift, and decreases the further away from this point you go.
This makes logical sense since the central path is the easiest one to travel.
Given the ever changing state of markets, I find this tool to be best suited for shorter term forecasts.
However, if the movements of price are expected to remain relatively stable, longer term forecasts may be equally as valid.
There are many possible ways for users to apply this tool to their analysis setups. For example, the forecast ranges may be used as a guide to help users set risk targets.
Or, the generated levels could be used in conjunction with other indicators for meaningful confluence signals.
More advanced users could even extrapolate the functions used within this script for various purposes, such as generating pseudorandom data to test systems on, perform integration and approximations, etc.
These are just a few examples of potential uses of this script. How you choose to use it to benefit your trading, analysis, and coding is entirely up to you.
If nothing else, I think this is a pretty neat script simply for the novelty of it.
----------
How To Use:
When you first add the script to your chart, you will be prompted to confirm the starting date and time, number of bars to forecast, number of simulations to run, and whether to include drift assumption.
You will also be prompted to confirm the forecast type. There are two types to choose from:
-> End Result - This uses the values from the end of the simulation throughout the forecast interval.
-> Developing - This uses the values that develop from bar to bar, providing a real-time outlook.
You can always update these settings after confirmation as well.
Once these inputs are confirmed, the script will boot up and automatically generate the forecast in a separate pane.
Note that if there is no bar of data at the time you wish to start the forecast, the script will automatically detect use the next available bar after the specified start time.
From here, you can now control the rest of the settings.
The "Seeding Settings" section controls the initial seed value used to generate the children that produce the simulations.
In this section, you can control whether the seed is a fixed value, or a dynamic one.
Since selecting the dynamic parent option will change the seed value every time you change the settings or refresh your chart, there is a "Regenerate" input built into the script.
This input is a dummy input that isn't connected to any of the calculations. The purpose of this input is to force an update of the dynamic parent without affecting the generator or forecast settings.
Note that because we're running a limited number of simulations, different parent seeds will typically yield slightly different forecast ranges.
When using a small number of simulations, you will likely see a higher amount of variance between differently seeded results because smaller numbers of sampled simulations yield a heavier bias.
The more simulations you run, the smaller this variance will become since the outcomes become more convergent toward the same distribution, so the differences between differently seeded forecasts will become more marginal.
When using a dynamic parent, pay attention to the dispersion of ranges.
When you find a set of ranges that is dispersed how you like with your configuration, set your fixed parent value to the parent seed that shows in the info panel.
This will allow you to replicate that dispersion behavior again in the future.
An important thing to note when settings alerts on the plotted levels, or using them as components for signals in other scripts, is to decide on a fixed value for your parent seed to avoid minor repainting due to seed changes.
When the parent seed is fixed, no repainting occurs.
The "Amplitude Settings" section controls the amplitude coefficients for the three differently tailed generators.
These amplitude factors will change the difference series output for each simulation by controlling how aggressively each series moves.
When "Adjust Amplitude Coefficients" is disabled, all three coefficients are set to 1.
Note that if you expect volatility to significantly diverge from its historical values over the forecast interval, try experimenting with these factors to match your anticipation.
The "Weighting Settings" section controls the weighting boundaries for the three generators.
These weighting limits affect how tailed the distributions in each generator are, which in turn affects the final series outputs.
The maximum absolute value range for the weights is . When "Limit Generator Weights" is disabled, this is the range that is automatically used.
The last set of inputs is the "Display Settings", where you can control the visual outputs.
From here, you can select to display either "Forecast" or "Difference Comparison" via the "Output Display Type" dropdown tab.
"Forecast" is the type displayed by default. This plots the end result or developing forecast ranges.
There is an option with this display type to show the developing extremes of the simulations. This option is enabled by default.
There's also an option with this display type to show one of the simulated price series from the set alongside actual prices.
This allows you to visually compare simulated prices alongside the real prices.
"Difference Comparison" allows you to visually compare a synthetic difference series from the set alongside the actual difference series.
This display method is primarily useful for visually tuning the amplitude and weighting settings of the generators.
There are also info panel settings on the bottom, which allow you to control size, colors, and date format for the panel.
It's all pretty simple to use once you get the hang of it. So play around with the settings and see what kinds of forecasts you can generate!
----------
ADDITIONAL NOTES & DISCLAIMERS
Although I've done a number of things within this script to keep runtime demands as low as possible, the fact remains that this script is fairly computationally heavy.
Because of this, you may get random timeouts when using this script.
This could be due to either random drops in available runtime on the server, using too many simulations, or running the simulations over too many bars.
If it's just a random drop in runtime on the server, hide and unhide the script, re-add it to the chart, or simply refresh the page.
If the timeout persists after trying this, then you'll need to adjust your settings to a less demanding configuration.
Please note that no specific claims are being made in regards to this script's predictive accuracy.
It must be understood that this model is based on randomized price generation with assumed constant drift and dispersion from historical data before the starting point.
Models like these not consider the real world factors that may influence price movement (economic changes, seasonality, macro-trends, instrument hype, etc.), nor the changes in sample distribution that may occur.
In light of this, it's perfectly possible for price data to exceed even the most extreme simulated outcomes.
The future is uncertain, and becomes increasingly uncertain with each passing point in time.
Predictive models of any type can vary significantly in performance at any point in time, and nobody can guarantee any specific type of future performance.
When using forecasts in making decisions, DO NOT treat them as any form of guarantee that values will fall within the predicted range.
When basing your trading decisions on any trading methodology or utility, predictive or not, you do so at your own risk.
No guarantee is being issued regarding the accuracy of this forecast model.
Forecasting is very far from an exact science, and the results from any forecast are designed to be interpreted as potential outcomes rather than anything concrete.
With that being said, when applied prudently and treated as "general case scenarios", forecast models like these may very well be potentially beneficial tools to have in the arsenal.

Machine Learning: LVQ-based StrategyLVQ-based Strategy (FX and Crypto)
Description:
Learning Vector Quantization (LVQ) can be understood as a special case of an artificial neural network, more precisely, it applies a winner-take-all learning-based approach. It is based on prototype supervised learning classification task and trains its weights through a competitive learning algorithm.
Algorithm:
Initialize weights
Train for 1 to N number of epochs
- Select a training example
- Compute the winning vector
- Update the winning vector
Classify test sample
The LVQ algorithm offers a framework to test various indicators easily to see if they have got any *predictive value*. One can easily add cog, wpr and others.
Note: TradingViews's playback feature helps to see this strategy in action. The algo is tested with BTCUSD/1Hour.
Warning: This is a preliminary version! Signals ARE repainting.
***Warning***: Signals LARGELY depend on hyperparams (lrate and epochs).
Style tags: Trend Following, Trend Analysis
Asset class: Equities, Futures, ETFs, Currencies and Commodities
Dataset: FX Minutes/Hours+++/Days
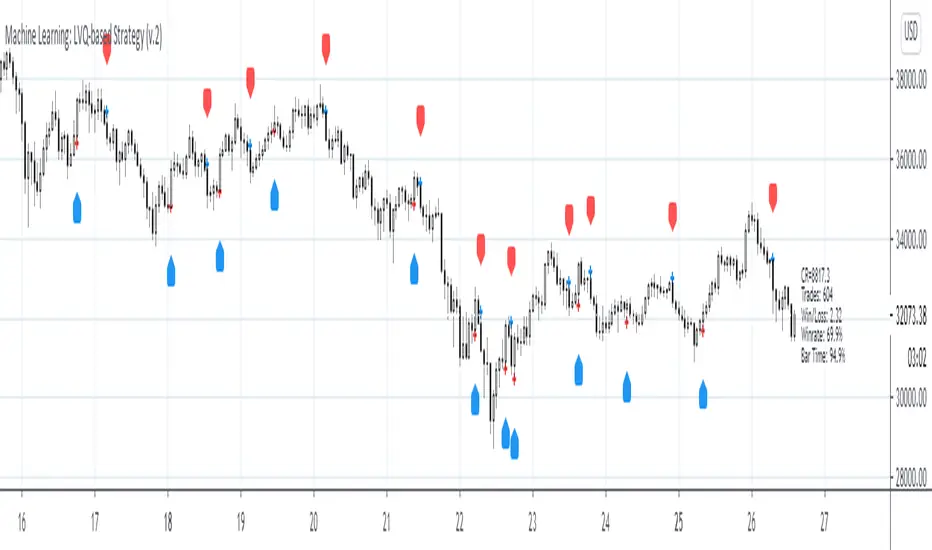
MIDAS VWAP Jayy his is just a bash together of two MIDAS VWAP scripts particularly AkifTokuz and drshoe.
I added the ability to show more MIDAS curves from the same script.
The algorithm primarily uses the "n" number but the date can be used for the 8th VWAP
I have not converted the script to version 3.
To find bar number go into "Chart Properties" select " "background" then select Indicator Titles and "Indicator values". When you place your cursor over a bar the first number you see adjacent to the script title is the bar number. Put that in the dialogue box midline is MIDAS VWAP . The resistance is a MIDAS VWAP using bar highs. The resistance is MIDAS VWAP using bar lows.
In most case using N will suffice. However, if you are flipping around charts inputting a specific date can be handy. In this way, you can compare the same point in time across multiple instruments eg first trading day of the year or an election date.
Adding dates into the dialogue box is a bit cumbersome so in this version, it is enabled for only one curve. I have called it VWAP and it follows the typical VWAP algorithm. (Does that make a difference? Read below re my opinion on the Difference between MIDAS VWAP and VWAP ).
I have added the ability to start from the bottom or top of the initiating bar.
In theory in a probable uptrend pick a low of a bar for a low pivot and start the MIDAS VWAP there using the support.
For a downtrend use the high pivot bar and select resistance. The way to see is to play with these values.
Difference between MIDAS VWAP and the regular VWAP
MIDAS itself as described by Levine uses a time anchored On-Balance Volume (OBV) plotted on a graph where the horizontal (abscissa) arm of the graph is cumulative volume not time. He called his VWAP curves Support/Resistance VWAP or S/R curves. These S/R curves are often referred to as "MIDAS curves".
These are the main components of the MIDAS chart. A third algorithm called the Top-Bottom Finder was also described. (Separate script).
Additional tools have been described in "MIDAS_Technical_Analysis"
Midas Technical Analysis: A VWAP Approach to Trading and Investing in Today’s Markets by Andrew Coles, David G. Hawkins
Copyright © 2011 by Andrew Coles and David G. Hawkins.
Denoting the different way in which Levine approached the calculation.
The difference between "MIDAS" VWAP and VWAP is, in my opinion, much ado about nothing. The algorithms generate identical curves albeit the MIDAS algorithm launches the curve one bar later than the VWAP algorithm which can be a pain in the neck. All of the algorithms that I looked at on Tradingview step back one bar in time to initiate the MIDAS curve. As such the plotted curves are identical to traditional VWAP assuming the initiation is from the candle/bar midpoint.
How did Levine intend the curves to be drawn?
On a reversal, he suggested the initiation of the Support and Resistance VVWAP (S/R curve) to be started after a reversal.
It is clear in his examples this happens occasionally but in many cases he initiates the so-called MIDAS S/R VWAP right at the reversal point. In any case, the algorithm is problematic if you wish to start a curve on the first bar of an IPO .
You will get nothing. That is a pain. Also in Levine's writings, he describes simply clicking on the point where a
S/R VWAP is to be drawn from. As such, the generally accepted method of initiating the curve at N-1 is a practical and sensible method. The only issue is that you cannot draw the curve from the first bar on any security, as mentioned without resorting to the typical VWAP algorithm. There is another difference. VWAP is launched from the middle of the bar (as per AlphaTrends), You can also launch from the top of the bar or the bottom (or anywhere for that matter). The calculation proceeds using the top or bottom for each new bar.
The potential applications are discussed in the MIDAS Technical Analysis book.
The Abramelin Protocol [MPL]"Any sufficiently advanced technology is indistinguishable from magic." — Arthur C. Clarke
🌑 SYSTEM OVERVIEW
The Abramelin Protocol is not a standard technical indicator; it is a "Technomantic" trading algorithm engineered to bridge the gap between 15th-century esoteric mathematics and modern high-frequency markets.
This script is the flagship implementation of the MPL (Magic Programming Language) project—an open-source experimental framework designed to compile metaphysical intent into executable Python and Pine Script algorithms.
Unlike traditional indicators that rely on arbitrary constants (like the 14-period RSI or 200 SMA), this protocol calculates its parameters using "Dynamic Entity Gematria." We utilize a custom Python backend to analyze the ASCII vibrational frequencies of specific metaphysical archetypes, reducing them via Tesla's 3-6-9 harmonic principles to derive market-responsive periods.
🧬 WHAT IS ?
MPL (Magic Programming Language) is a domain-specific language and research initiative created to explore Technomancy—the art of treating code as a spellbook and the market as a chaotic entity to be tamed.
By integrating the logic of ancient Grimoires (such as The Book of Abramelin) with modern Data Science, MPL aims to discover hidden correlations in price action that standard tools overlook.
🔗 CONNECT WITH THE PROJECT:
If you are a developer, a trader, or a seeker of hidden knowledge, examine the source code and join the order:
• 📂 Official Project Site: hakanovski.github.io
• 🐍 MPL Source Code (GitHub): github.com
• 👨💻 Developer Profile (LinkedIn): www.linkedin.com
🔢 THE ALGORITHM: 452 - 204 - 50
The inputs for this script are mathematically derived signatures of the intelligence governing the system:
1. THE PAIMON TREND (Gravity)
• Origin: Derived from the ASCII summation of the archetype PAIMON (King of Secret Knowledge).
• Function: This 452-period Baseline acts as the market's "Event Horizon." It represents the deep, structural direction of the asset.
• Price > Line: Bullish Domain.
• Price < Line: Bearish Void.
2. THE ASTAROTH SIGNAL (Trigger)
• Origin: Derived from the ASCII summation of ASTAROTH (Knower of Past & Future), reduced by Tesla’s 3rd Harmonic.
• Function: This is the active trigger line. It replaces standard moving averages with a precise, gematria-aligned trajectory.
3. THE VOLATILITY MATRIX (Scalp)
• Origin: Based on the 9th Harmonic reduction.
• Function: Creates a "Cloud" around the signal line to visualize market noise.
🛡️ THE MILON GATE (Matrix Filter)
Unique to this script is the "MILON Gate" toggle found in the settings.
• ☑️ Active (Default): The algorithm applies the logic of the MILON Magic Square. Signals are ONLY generated if Volume and Volatility align with the geometric structure of the move. This filters out ~80% of false signals (noise).
• ⬜ Inactive: The algorithm operates in "Raw Mode," showing every mathematical crossover without the volume filter.
⚠️ OPERATIONAL USAGE
• Timeframe: Optimized for 4H (The Builder) and Daily (The Architect) charts.
• Strategy: Use the Black/Grey Line (452) as your directional bias. Take entries only when the "EXECUTE" (Long) or "PURGE" (Short) sigils appear.
Use this tool wisely. Risk responsibly. Let the harmonics guide your entries.
— Hakan Yorganci
Technomancer & Full Stack Developer
