GKD-V Weis Wave [Loxx]Giga Kaleidoscope GKD-V Weis Wave is a Volatility/Volume module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines , channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility . There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility ; e.g., Average True Range , True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility / Volume - a technical indicator used to identify volatility / volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR ( Average True Range ) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility . As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double ( TRD ), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index ( RSI ), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index ( RSI ).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands , the MACD (Moving Average Convergence Divergence), and the Stochastic Oscillator. These indicators can provide information about the volatility , momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility / Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow ( CMF ), or the Volume Price Trend ( VPT ), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index . Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index ( RSI ), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR , the Average Directional Index ( ADX ), and the Chandelier Exit .
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module ( Volatility , Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility / Volume , Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility / Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility / Volume . The Volatility / Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility , and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Weis Wave as shown on the chart above
Confirmation 1: Vortex
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume Agrees
█ GKD-C Weis Wave
What is Weis Wave?
The Weis Wave Indicator is a technical analysis tool used by traders to analyze market trends and identify potential turning points in financial markets. It was developed by David Weis, a trader and market analyst with over 45 years of experience.
The Weis Wave Indicator is based on the principles of market waves, which are the repetitive patterns of market behavior that occur in financial markets. These waves are characterized by price movements that occur in a series of up and down trends, and they are used by traders to identify potential market reversals or breakouts.
The Weis Wave Indicator is a histogram that represents the difference between the cumulative sum of the bullish and bearish waves. The indicator is plotted on a chart as a series of bars that change color depending on the direction of the market trend. If the market is trending up, the bars will be green, while if the market is trending down, the bars will be red.
The formula for the Weis Wave Indicator is based on the accumulation and distribution of volume over time. It uses a cumulative delta volume calculation to determine the strength of market trends and identify potential turning points. The formula is as follows:
Weis Wave Volume = Net Buying Volume - Net Selling Volume
The Weis Wave Indicator is used by traders to identify potential market trends and turning points. It is particularly useful in identifying market breakouts and reversals, as well as in detecting divergences between price and volume. The indicator is commonly used in conjunction with other technical analysis tools, such as moving averages, trend lines, and support and resistance levels, to confirm market trends and generate trading signals.
Specifically, the Weis Wave Volume Indicator is an oscillator that measures the volume of price changes. It combines both momentum and volume to indicate buying and selling pressure. The indicator is designed to show a bull market when the volume is increasing and the price is rising, and a bear market when the volume is decreasing and the price is falling ¹.
The Weis Wave Plugin creates wave charts along with their corresponding wave volume. Wave charts were first created by Richard D. Wyckoff. In his famous course on stock market technique, he instructed students to “think in waves.” Wave analysis was an integral part of his trading method. The Weis Wave is an adaptation of Wyckoff’s method that handles today’s volatile markets ².
This indicator has the option of either ATR, volume, or partial close for source input.
(1) Weis Wave Volume Indicator - Trend Following System. www.trendfollowingsystem.com Accessed 4/7/2023.
(2) Weis Wave Plugin: A Modern Adaptation of the Wyckoff Wave & Volume. weisonwyckoff.com Accessed 4/7/2023.
(3) Weis Wave Volume Indicator: Simple But Extremely Effective. howtotradeblog.com Accessed 4/7/2023.
(4) How to use the Weis Waves indicator in ATAS. atas.net Accessed 4/7/2023.
Requirements
Inputs
Chained: GKD-B Baseline
Solo: NA, no inputs
Baseline + Volatility/Volume: GKD-B Baseline
Outputs
Chained: GKD-C indicators Confirmation 1 or Solo Confirmation Complex
Solo: GKD-BT Backtest
Baseline + Volatility/Volume: GKD-BT Backtest
Additional features will be added in future releases.
Поиск скриптов по запросу "algo"

GKD-C Blau Ergodic Candlestick Index [Loxx]Giga Kaleidoscope GKD-C Blau Ergodic Candlestick Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Ergodic Candlestick Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
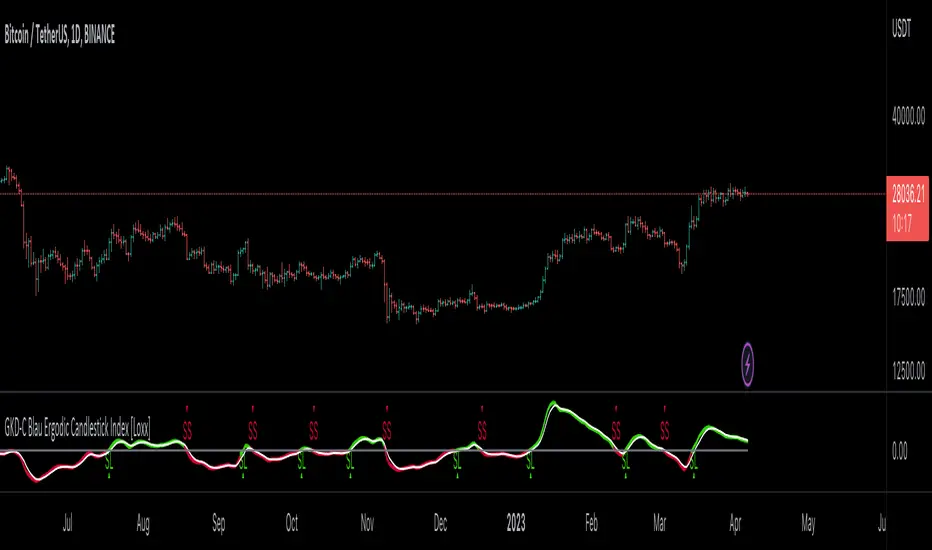
█ GKD-C Blau Ergodic Candlestick Index
What is Blau Ergodic Candlestick Index?
The Blau Ergodic CSI-Oscillator is a technical analysis indicator developed by William Blau and described in his book “Momentum, Direction, and Divergence: Applying the Latest Momentum Indicators for Technical Analysis”. It is based on the Candlestick Index (CSI), which measures the difference between the current close price and the open price of a certain number of bars ago. The values of the CSI are normalized by the price range and mapped into the interval.
The Ergodic CSI-Oscillator is calculated using the following formula:
Ergodic_CSI(price1,price2,q,r,s,u) = CSI(price1,price2,q,r,s,u)
SignalLine(price1,price2,q,r,s,u,ul) = EMA(Ergodic_CSI(price1,price2,q,r,s,u),ul)
where:
- Ergodic_CSI(): Ergodic - Candlestick Index CSI(price1,price2,q,r,s,u)
- SignalLine(): Signal Line - exponentially smoothed moving average EMA(ul), applied to Ergodic
- ul: period of a signal line ¹.
The input parameters for this indicator are:
- q: number of bars used in calculation of Candlestick Momentum (default value is 1)
- r: period of the first EMA applied to Candlestick Momentum (default value is 20)
- s: period of the second EMA applied to result of the first smoothing (default value is 5)
- u: period of the third EMA applied to result of the second smoothing (default value is 3)
- ul: period of the Signal Line - EMA(ul), applied to Ergodic (default value is 3)
- AppliedPrice1: price type (default value is PRICE_CLOSE)
- AppliedPrice2: price type (default value is PRICE_OPEN) ¹.
I hope this information helps you understand what Blau Ergodic CSI-Oscillator is and how it works.
(2) William Blau's Indicators and Trading Systems in MQL5. Part 1 .... www.mql5.com Accessed 4/6/2023.
(3) Ergodic CSI-Oscillator Blau_Ergodic_CSI – indicator for MetaTrader 5. www.forexmt4indicators.com Accessed 4/6/2023.
(4) Free download of the 'Ergodic CSI-Oscillator Blau_Ergodic_CSI .... www.mql5.com Accessed 4/6/2023.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
GKD-C Blau Ergodic Candlestick Momentum Index [Loxx]Giga Kaleidoscope GKD-C Ergodic Candlestick Momentum Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Ergodic Candlestick Momentum Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
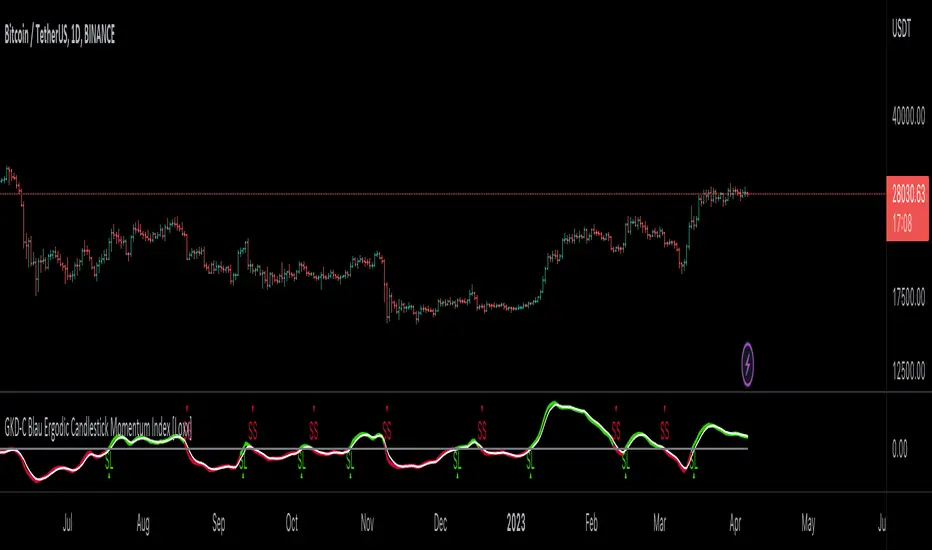
█ GKD-C Ergodic Candlestick Momentum Index
What is Ergodic Candlestick Momentum Index?
The Blau Ergodic CMI-Oscillator is a technical analysis indicator developed by William Blau and described in his book “Momentum, Direction, and Divergence: Applying the Latest Momentum Indicators for Technical Analysis”. It is based on the Candlestick Momentum Index (CMI), which measures the difference between the current close price and the open price of a certain number of bars ago. The values of the CMI are normalized by the price range and mapped into the interval ¹.
The Ergodic CMI-Oscillator is calculated using the following formula:
Ergodic_CMI(price1,price2,q,r,s,u) = CMI(price1,price2,q,r,s,u)
SignalLine(price1,price2,q,r,s,u,ul) = EMA(Ergodic_CMI(price1,price2,q,r,s,u),ul)
where:
- Ergodic_CMI(): Ergodic - Candlestick Momentum Index CMI(price1,price2,q,r,s,u)
- SignalLine(): Signal Line - exponentially smoothed moving average EMA(ul), applied to Ergodic
- ul: period of a signal line ¹.
The input parameters for this indicator are:
- q: number of bars used in calculation of Candlestick Momentum (default value is 1)
- r: period of the first EMA applied to Candlestick Momentum (default value is 20)
- s: period of the second EMA applied to result of the first smoothing (default value is 5)
- u: period of the third EMA applied to result of the second smoothing (default value is 3)
- ul: period of the Signal Line - EMA(ul), applied to Ergodic (default value is 3)
- AppliedPrice1: price type (default value is PRICE_CLOSE)
- AppliedPrice2: price type (default value is PRICE_OPEN) ¹.
I hope this information helps you understand what Blau Ergodic CMI-Oscillator is and how it works.
(1) Ergodic CMI-Oscillator Blau_Ergodic_CMI - indicator for MetaTrader 5 - MQL5. www.mql5.com Accessed 4/6/2023.
(2) HOW TO TRADE: Stochastic Momentum Index Indicator - Video Manual and .... www.mql5.com Accessed 4/6/2023.
(3) Ergodic CMI-Oscillator Blau_Ergodic_CMI – indicator for MetaTrader 5. www.forexmt4indicators.com Accessed 4/6/2023.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
GKD-C Blau Directional Trend Index [Loxx]Giga Kaleidoscope GKD-C Blau Candlestick Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Candlestick Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Candlestick Index
What is Blau Candlestick Index?
The Blau Directional Trend Index (BDTI) is a technical analysis indicator that is used to identify the strength and direction of a trend in financial markets. It was developed by Dr. Alexander Elder and Eric Blau, and is based on the principles of the Directional Movement Index (DMI) and the Relative Strength Index (RSI). ².
The BDTI is calculated by first calculating the raw BDTI value, which is derived from the difference between the sum of positive closes and the sum of negative closes, divided by the sum of all closes. This raw value is then smoothed using an exponential moving average (EMA) to generate the final BDTI value.
The BDTI can be used to identify both the strength and direction of a trend, as well as potential trend reversals. The indicator is considered bullish when it is above the zero line, indicating that the buyers are in control of the market. Conversely, the indicator is considered bearish when it is below the zero line, indicating that the sellers are in control.
The BDTI can also be used to identify overbought and oversold conditions in the market. When the BDTI rises above a certain threshold, such as 75, it is considered overbought and a potential reversal may occur. Conversely, when the BDTI falls below a certain threshold, such as 25, it is considered oversold and a potential reversal may occur.
The DTI is calculated using the following formula:
DTI(q,r,s,u) = 100 * HLM(q,r,s,u) / EMA(EMA(EMA(|HLM(q)|,r),s),u)
where:
- q: number of bars used in calculation of Up Trend Momentum and Down Trend Momentum
- HLM(q): Composite High/Low Momentum
- |HLM(q)|: absolute value of HLM(q)
- HLM(q,r,s,u): triple smoothed HLM(q)
- EMA(...,r): first smoothing - exponentially smoothed moving average with period r, applied to HLM(q) and absolute values of HLM(q)
- EMA(EMA(...,r),s): second smoothing - EMA of period s, applied to result of the first smoothing
- EMA(EMA(EMA(...,r),s),u): third smoothing - EMA of period u, applied to result of the second smoothing ².
The input parameters for this indicator are:
- q: number of bars used in calculation of HLM (default value is 2)
- r: period of the first EMA applied to HLM (default value is 20)
- s: period of the second EMA applied to result of the first smoothing (default value is 5)
- u: period of the third EMA applied to result of the second smoothing (default value is 3) ².
(1) Directional Trend Index Blau_DTI - indicator for MetaTrader 5 - MQL5. www.mql5.com Accessed 4/6/2023.
(2) Directional Trend Index - QuantShare Trading Software. www.quantshare.com Accessed 4/6/2023.
(3) Blau_Directional_Trend_Index - indicator for MetaTrader 5. www.mql5.com Accessed 4/6/2023.
(4) Directional Trend Index - MotiveWave. www.motivewave.com Accessed 4/6/2023.
(5) Blau Directional Trend Index Indicator - Forex Racer. www.forexracer.com Accessed 4/6/2023.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.

GKD-C Blau Candlestick Index [Loxx]Giga Kaleidoscope GKD-C Blau Candlestick Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Candlestick Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Candlestick Index
What is Blau Candlestick Index?
The Blau Candlestick Index (CSI) is a technical analysis indicator developed by William Blau and described in his book “Momentum, Direction, and Divergence: Applying the Latest Momentum Indicators for Technical Analysis”. It is based on the Candlestick Momentum Indicator, which measures the difference between the current close price and the open price of a certain number of bars ago. The values of the CSI are normalized by the price range and mapped into the interval ³.
The CSI is calculated using the following formula:
CSI(price1,price2,q,r,s,u) = 100 * CMtm(price1,price2,q,r,s,u) / EMA(EMA(EMA(HH(q)-LL(q),r),s),u)
where:
- price1: close price
- price2: open price q bars ago
- q: number of bars used in calculation of Candlestick Momentum
- cmtm(price1,price2,q): Candlestick Momentum
- CMtm(price1,price2,q,r,s,u): Triple smoothed Candlestick Momentum
- LL(q): lowest price of the q bars
- HH(q): highest price of the q bars
- EMA(...,r): first smoothing - exponentially smoothed moving average with period r, applied to Candlestick Momentum and q-period Price Range
- EMA(EMA(...,r),s): second smoothing - EMA of period s, applied to result of the first smoothing
- EMA(EMA(EMA(...,r),s),u): third smoothing - EMA of period u, applied to result of the second smoothing ³.
The input parameters for this indicator are:
- q: number of bars used in calculation of Candlestick Momentum (default value is 1)
- r: period of the first EMA applied to Candlestick Momentum (default value is 20)
- s: period of the second EMA applied to result of the first smoothing (default value is 5)
- u: period of the third EMA applied to result of the second smoothing (default value is 3)
- AppliedPrice1: price type (default value is PRICE_CLOSE)
- AppliedPrice2: price type (default value is PRICE_OPEN) ³.
(1) Candlestick Index Blau_CSI - indicator for MetaTrader 5 - MQL5. www.mql5.com Accessed 4/6/2023.
(2) The Blau Candlestick Index trading indicator for MT5. www.fxtradingrevolution.com Accessed 4/6/2023.
(3) True Strength Index (TSI) - StockCharts.com. school.stockcharts.com Accessed 4/6/2023.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
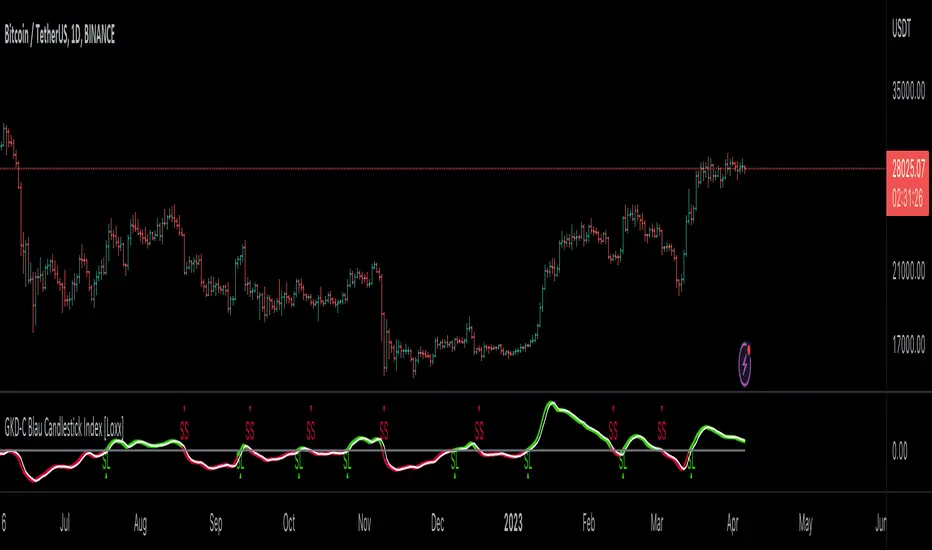
GKD-C Blau Candlestick Momentum Indicator [Loxx]Giga Kaleidoscope GKD-C Blau Candlestick Momentum Indicator is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Candlestick Momentum Indicator as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Candlestick Momentum Indicator
What is Blau Candlestick Momentum Indicator?
The Candlestick Momentum Indicator is a technical analysis indicator developed by William Blau and described in his book “Momentum, Direction, and Divergence: Applying the Latest Momentum Indicators for Technical Analysis”. It measures the difference between the current close price and the open price of a certain number of bars ago. The values of the Candlestick Momentum Indicator are normalized by absolute values and mapped into the interval .
The Candlestick Momentum Indicator is calculated using the following formula:
CMtm(price1,price2,q,r,s,u) = 100 * EMA(EMA(EMA(cmtm(price1,price2,q),r),s),u)
where:
- price1: close price
- price2: open price q bars ago
- q: number of bars used in calculation of Candlestick Momentum
- cmtm(price1,price2,q): Candlestick Momentum
- CMtm(price1,price2,q,r,s,u): Triple smoothed Candlestick Momentum
- EMA(...,r): first smoothing - exponentially smoothed moving average with period r, applied to Candlestick Momentum
- EMA(EMA(...,r),s): second smoothing - EMA of period s, applied to result of the first smoothing
- EMA(EMA(EMA(...,r),s),u): third smoothing - EMA of period u, applied to result of the second smoothing .
The input parameters for this indicator are:
- q: number of bars used in calculation of Candlestick Momentum (default value is 1)
- r: period of the first EMA applied to Candlestick Momentum (default value is 20)
- s: period of the second EMA applied to result of the first smoothing (default value is 5)
- u: period of the third EMA applied to result of the second smoothing (default value is 3)
- AppliedPrice1: price type (default value is PRICE_CLOSE)
- AppliedPrice2: price type (default value is PRICE_OPEN) .
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
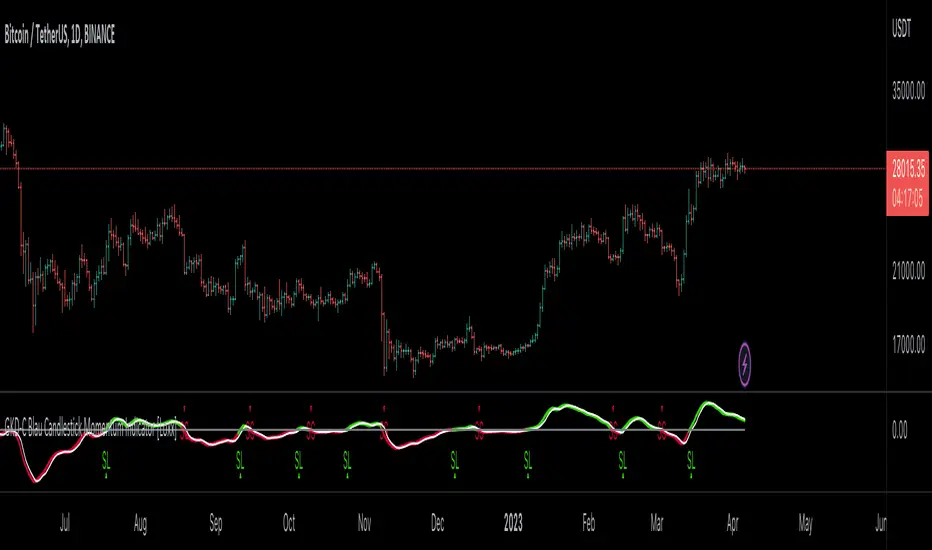
GKD-C Blau Candlestick Momentum Index [Loxx]Giga Kaleidoscope GKD-C Blau Candlestick Momentum Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Candlestick Momentum Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Candlestick Momentum Index
What is Blau Candlestick Momentum Index?
The Blau Candlestick Momentum Index (CMI) is a technical analysis indicator developed by William Blau and described in his book “Momentum, Direction, and Divergence: Applying the Latest Momentum Indicators for Technical Analysis”. It is based on the Candlestick Momentum Indicator, which measures the difference between the current close price and the open price of a certain number of bars ago. The values of the CMI are normalized by the price range and mapped into the interval.
The CMI is calculated using the following formula:
CMI(price1,price2,q,r,s,u) = 100 * CMtm(price1,price2,q,r,s,u) / EMA(EMA(EMA(|cmtm(price1,price2,q)|,r),s),u)
where:
- price1: close price
- price2: open price q bars ago
- q: number of bars used in calculation of Candlestick Momentum
- cmtm(price1,price2,q): Candlestick Momentum
- CMtm(price1,price2,q,r,s,u): Triple smoothed Candlestick Momentum
- EMA(...,r): first smoothing - exponentially smoothed moving average with period r, applied to Candlestick Momentum and absolute value of Candlestick Momentum
- EMA(EMA(...,r),s): second smoothing - EMA of period s, applied to result of the first smoothing
- EMA(EMA(EMA(...,r),s),u): third smoothing - EMA of period u, applied to result of the second smoothing ³.
The input parameters for this indicator are:
- q: number of bars used in calculation of Candlestick Momentum (default value is 1)
- r: period of the first EMA applied to Candlestick Momentum (default value is 20)
- s: period of the second EMA applied to result of the first smoothing (default value is 5)
- u: period of the third EMA applied to result of the second smoothing (default value is 3)
- AppliedPrice1: price type (default value is PRICE_CLOSE)
- AppliedPrice2: price type (default value is PRICE_OPEN) ³.
(2) www.mql5.com ]Candlestick Momentum Index Blau_CMI - indicator for MetaTrader 5 - MQL5. Accessed 4/6/2023.
(3) True Strength Index (TSI) - StockCharts.com. school.stockcharts.com Accessed 4/6/2023.
(4) Candlestick Momentum Index Blau_CMI – indicator for MetaTrader 5. www.forexmt4indicators.com Accessed 4/6/2023.
(5) Candlestick Index Blau_CSI – indicator for MetaTrader 5. Accessed 4/6/2023.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.

GKD-C Blau Ergodic Oscillator [Loxx]Giga Kaleidoscope GKD-C Blau Ergodic Oscillator is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Ergodic Oscillator as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Ergodic Oscillator
What is Blau Ergodic Oscillator?
The William Blau Ergodic Oscillator (BEO) is a technical analysis indicator developed by William Blau, a trader and mathematician, in the early 1990s. The BEO is used to identify potential trend reversals and momentum shifts in the price of an asset.
The BEO is based on the concept of an ergodic process, which is a mathematical model used to describe a stochastic process that behaves similarly over time. The BEO is designed to provide a more accurate representation of price movements than traditional momentum indicators, such as the Relative Strength Index (RSI), by using a more complex calculation.
The BEO is calculated by applying a double exponential moving average (DEMA) to the True Strength Index (TSI), which is itself based on Momentum to which double smoothing has been applied. The formula for the TSI is:
TSI = 100 * EMA(EMA(Momentum)) / EMA(EMA(|Momentum|))
The double exponential moving average is used to reduce the lag often associated with traditional moving averages and provide a more accurate representation of the underlying trend. The oscillator is then plotted on a separate chart below the price chart.
The BEO oscillates between two extreme values, typically ranging from 0 to 100. A reading above 50 indicates a bullish trend, while a reading below 50 indicates a bearish trend. The BEO is also often used in conjunction with other technical analysis tools, such as moving averages and trend lines, to confirm potential trend reversals or momentum shifts.
One of the unique features of the BEO is the ability to adjust the sensitivity of the oscillator by changing the parameters used in the calculation. This allows traders to customize the indicator to fit their specific trading style and market conditions.
To generate buy and sell signals, a signal line is added to the oscillator. When the oscillator crosses above the signal line, it is considered a buy signal, while a cross below the signal line is considered a sell signal.
In conclusion, the William Blau Ergodic Oscillator is a technical analysis indicator used to identify potential trend reversals and momentum shifts in the price of an asset. It is based on the concept of an ergodic process and uses a double exponential moving average applied to the True Strength Index to reduce lag and provide a more accurate representation of price movements. The oscillator oscillates between 0 and 100, and a signal line is added to generate buy and sell signals. The BEO is a versatile tool that can be customized to fit the specific needs of traders and market conditions.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
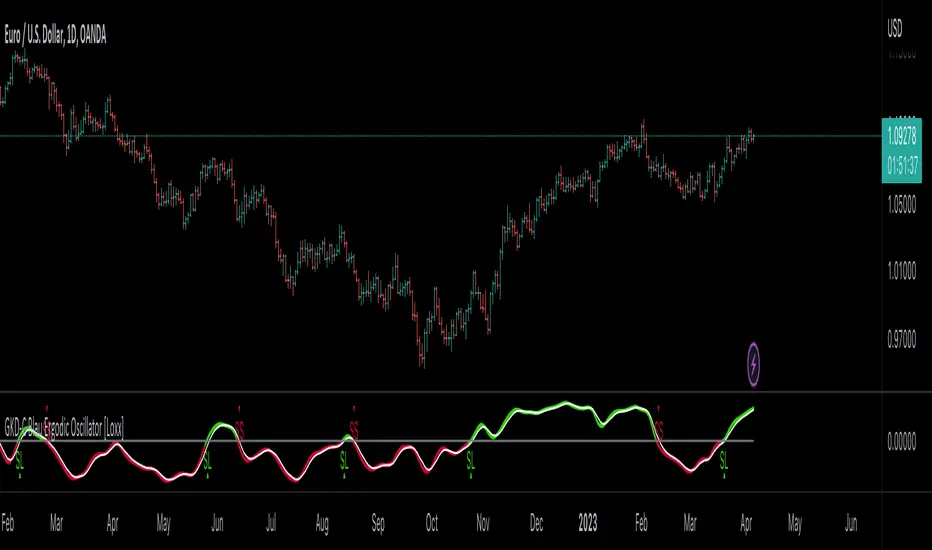
GKD-C Blau Stochastic Index [Loxx]Giga Kaleidoscope GKD-C Blau Stochastic Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Stochastic Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Stochastic Index
What is Blau Stochastic Index?
The Blau Stochastic Index is a technical analysis tool created by William Blau that helps traders determine whether the market is overbought or oversold. This indicator is a normalized smoothed q-period Stochastic, which means that it takes the values of a q-period smoothed Stochastic and normalizes them to be mapped into the interval. This allows the indicator to identify potential buying and selling opportunities based on the current price levels.
The Stochastic Index Indicator is calculated using a complex formula that takes into account several input parameters such as the close price, the number of bars used in the calculation (q), the lowest and highest price of the q bars (LL(q) and HH(q)), and the periods of the three exponential moving averages (EMA) used for smoothing (r, s, and u).
To be more specific, the Blau Stochastic Index is calculated as follows: first, the triple smoothed q-period Stochastic (TStoch) is computed using the high and low prices of the last q bars. Then, the first smoothing is applied to both the TStoch and the q-period price range using an exponentially smoothed moving average with a period of r. Next, the second smoothing is applied to the result of the first smoothing using an EMA of period s. Finally, the third smoothing is applied to the result of the second smoothing using an EMA of period u. The result of this final smoothing is then multiplied by 100 to normalize the values and map them into the interval.
The Blau Stochastic Index has several input parameters that can be customized by traders, including the period used for the calculation of Stochastic (q), the period of the first EMA applied to Stochastic (r), the period of the second EMA applied to the result of the first smoothing (s), and the period of the third EMA applied to the result of the second smoothing (u). The default values for these parameters are 5, 20, 5, and 3, respectively.
The Stochastic Index Indicator is calculated using the following formula:
TStochI (price,q,r,s,u) = 100 * TStoch (price,q,r,s,u) / EMA (EMA (EMA ( HH (q)-LL (q) ,r),s),u)
where:
price: close price
q: number of bars used in calculation
LL(q): lowest price of the q bars
HH(q): highest price of the q bars
TStoch(price,q,r,s,u): triple smoothed q-period Stochastic
EMA(…,r): first smoothing - exponentially smoothed moving average with period r, applied to q-period Stochastic and q-period Price Range
EMA(EMA(…,r),s): second smoothing - EMA of period s, applied to result of the first smoothing
EMA(EMA(EMA(…,r),s),u): third smoothing - EMA of period u, applied to result of the second smoothing 1.
The input parameters for this indicator are:
q: period used for the calculation of Stochastic (default value is 5)
r: period of the first EMA applied to Stochastic (default value is 20)
s: period of the second EMA applied to result of the first smoothing (default value is 5)
u: period of the third EMA applied to result of the second smoothing (default value is 3)
AppliedPrice: price type (default value is PRICE_CLOSE)
Overall, the Blau Stochastic Index is a useful tool for technical traders who want to identify potential buying and selling opportunities based on the overbought/oversold state of the market. However, it is important to note that no indicator can accurately predict market movements, and traders should always use additional analysis and risk management techniques to make informed trading decisions.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.

GKD-C Blau Stochastic Indicator [Loxx]Giga Kaleidoscope GKD-C Blau Stochastic Indicator is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Stochastic Indicator as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Stochastic Indicator
What is Blau Stochastic Indicator?
The Blau Stochastic Indicator, also known as the q-period Stochastic or the smoothed q-period Stochastic, is a technical indicator used to measure momentum in financial markets. It was developed by Dr. William Blau, a well-known technical analyst and author.
The Blau Stochastic Indicator is an extension of the traditional Stochastic Oscillator, which aims to provide a smoother and more accurate representation of price momentum by incorporating smoothing techniques to remove noise from the signal. Unlike the traditional Stochastic Oscillator, which is bounded between 0 and 100, the Blau Stochastic Indicator has no defined boundaries.
The Blau Stochastic Indicator is calculated using the following steps:
1. Find the lowest low over the last q periods.
2. Subtract the lowest low from the current price to obtain the raw momentum value.
3. Smooth the raw momentum value using a series of three exponential moving averages (EMA) with periods u, s, and r, respectively.
The formula for the Blau Stochastic Indicator is:
Blau Stochastic = EMA(EMA(EMA(Close - LowestLow, u), s), r)
Where:
-Close: The closing price of the current period.
-LowestLow: The lowest low over the last q periods.
-EMA: Exponential Moving Average
-u: The period used to calculate the third EMA.
-s: The period used to calculate the second EMA.
-r: The period used to calculate the first EMA.
The resulting value is a momentum indicator that oscillates around zero and has no defined upper or lower boundaries. As with any technical indicator, traders typically look for divergences, crossovers, and overbought/oversold levels to identify potential trading opportunities.
The Blau Stochastic Indicator can be used in combination with other technical indicators and price action analysis to confirm signals and avoid false alarms. Traders may also use multiple timeframes to increase the accuracy of the signals generated by the indicator.
For this version, you have the option to select from 60+ moving averages and 30+ source types.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.

GKD-C Blau True Strength Index [Loxx]Giga Kaleidoscope GKD-C Blau True Strength Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau True Strength Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau True Strength Index
What is Blau True Strength Index?
The Blau True Strength Index (TSI) is a technical indicator that measures the strength of a security's trend by comparing the current price to historical price data. The TSI was developed by William Blau, a trader and expert in technical analysis. It is based on the popular Relative Strength Index (RSI) but differs in its calculation method.
The TSI uses two different smoothing techniques to remove noise from the price data and highlight the underlying trend. The first smoothing technique is a double exponential moving average (DEMA) of the price data. This DEMA helps to reduce the impact of short-term price fluctuations on the indicator's readings. The second smoothing technique is a triple exponential moving average (TEMA) of the DEMA values. The TEMA further smooths out the DEMA values and helps to reduce lag.
The Blau TSI can be calculated using the following steps:
1. Calculate the DEMA of the price data using a short-term and a long-term period. The short-term period is usually set to 13 and the long-term period is usually set to 25.
2. Calculate the difference between the short-term DEMA and the long-term DEMA.
3. Calculate the TEMA of the difference calculated in step 2 using a period of 7.
4. Calculate the TSI as a percentage by dividing the TEMA calculated in step 3 by the absolute value of the TEMA calculated in step 3 plus 1, and then multiplying by 100.
The TSI values range from -100 to +100, with readings above +25 indicating a strong uptrend and readings below -25 indicating a strong downtrend. Values between +25 and -25 indicate a weak or sideways trend.
Traders use the Blau TSI to identify trend reversals, confirm trend strength, and generate buy and sell signals. A bullish divergence between the TSI and the price can be a signal to buy, while a bearish divergence can be a signal to sell. Traders also look for crossovers of the TSI with its signal line to generate buy and sell signals.
In summary, the Blau True Strength Index is a technical indicator that measures the strength of a security's trend by comparing the current price to historical price data using two different smoothing techniques. Traders use the TSI to identify trend reversals, confirm trend strength, and generate buy and sell signals.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
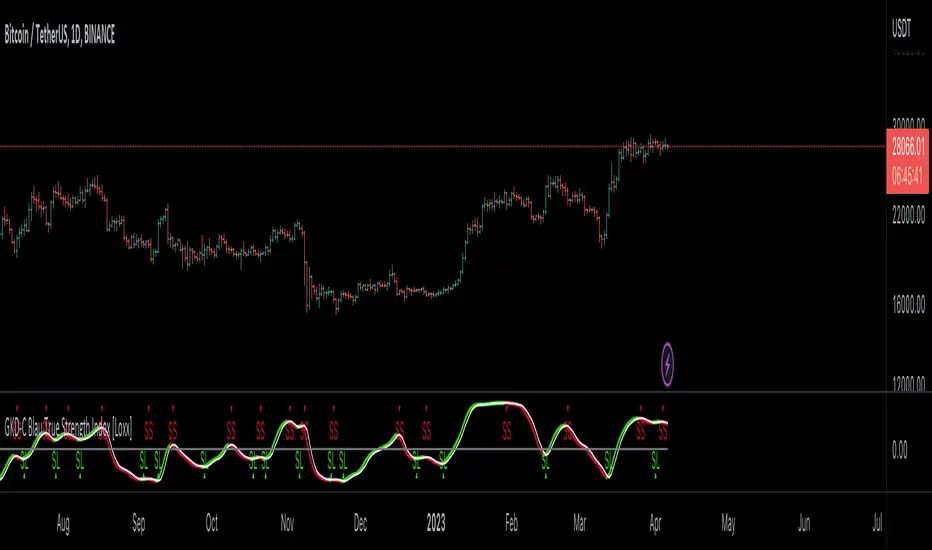
GKD-C Blau Stochastic TS-Oscillator [Loxx]Giga Kaleidoscope GKD-C Blau Stochastic TS-Oscillator is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Stochastic TS-Oscillator as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Stochastic TS-Oscillator
What is Blau Stochastic TS-Oscillator?
The Blau Stochastic TS-Oscillator is a technical analysis indicator developed by William Blau that combines the Stochastic Oscillator and a trend-following indicator to provide a more accurate and reliable measure of momentum in financial markets.
Like the standard Stochastic Oscillator, the Blau Stochastic TS-Oscillator measures the difference between the current closing price and the high/low range over a specified time period. However, it also includes a trend-following component that helps to filter out noise and provide a smoother, more stable indicator.
The trend-following component is typically a moving average, such as the Simple Moving Average (SMA) or the Exponential Moving Average (EMA). The moving average helps to identify the direction of the trend and smooth out any short-term fluctuations in the market.
The Blau Stochastic TS-Oscillator is calculated as follows:
1. Calculate the Stochastic Oscillator using the high, low, and closing prices over a specified time period, such as 14 periods.
2. Calculate the trend-following component using a moving average over the same time period.
3. Subtract the moving average from the Stochastic Oscillator to obtain the Blau Stochastic TS-Oscillator.
The oscillator is typically plotted on a chart as a line that fluctuates between 0 and 100. Values above 80 are considered overbought and may indicate a potential trend reversal or correction, while values below 20 are considered oversold and may indicate a potential buying opportunity.
The Blau Stochastic TS-Oscillator is a versatile indicator that can be used in a variety of markets and timeframes. It is particularly useful for traders who want to filter out noise and false signals using a trend-following component and prefer a more responsive indicator than the standard Stochastic Oscillator. As with any technical indicator, it is important to use the Blau Stochastic TS-Oscillator in conjunction with other forms of analysis and risk management strategies.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.

GKD-C Blau Stochastic Momentum Index [Loxx]Giga Kaleidoscope GKD-C Blau Stochastic Momentum Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Stochastic Momentum Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Stochastic Momentum Index
What is Blau Stochastic Momentum Index?
The Blau Stochastic Momentum Index (BSMI) is a technical analysis indicator used to measure momentum in financial markets. It was developed by William Blau, a well-known trader and author of several books on technical analysis.
The BSMI is based on the Stochastic Momentum Index (SMI), which is a popular momentum indicator that measures the distance between the current closing price and the recent high or low. The SMI is similar to the Stochastic Oscillator, but it takes into account the rate of change in the market, making it more responsive to short-term changes in momentum.
The BSMI is designed to provide a more accurate and responsive measure of momentum than the SMI. It uses a digital signal processing technique called "smoothed moving averages" to filter out noise and provide a smoother, more stable indicator. This technique helps to reduce false signals and provide a clearer picture of market momentum.
The BSMI indicator is plotted on a chart as a line that oscillates between -100 and +100. Values above zero indicate bullish momentum, while values below zero indicate bearish momentum. The BSMI line is typically plotted alongside the price chart to help traders identify potential turning points in the market.
Traders can use the BSMI indicator in a variety of ways, including:
1. Identifying overbought and oversold conditions: When the BSMI line reaches extreme values (e.g., above +80 or below -80), it may indicate that the market is overbought or oversold and due for a reversal.
2. Confirming trend strength: When the BSMI line is trending in the same direction as the price, it can confirm the strength of the trend and help traders stay in winning positions.
3. Identifying divergences: When the BSMI line and the price chart are moving in opposite directions, it may indicate a potential trend reversal or weakening of the current trend.
As with any technical indicator, it is important to use the BSMI in conjunction with other forms of analysis and risk management strategies. No single indicator can predict market movements with 100% accuracy, and traders should always use caution and discipline when making trading decisions.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
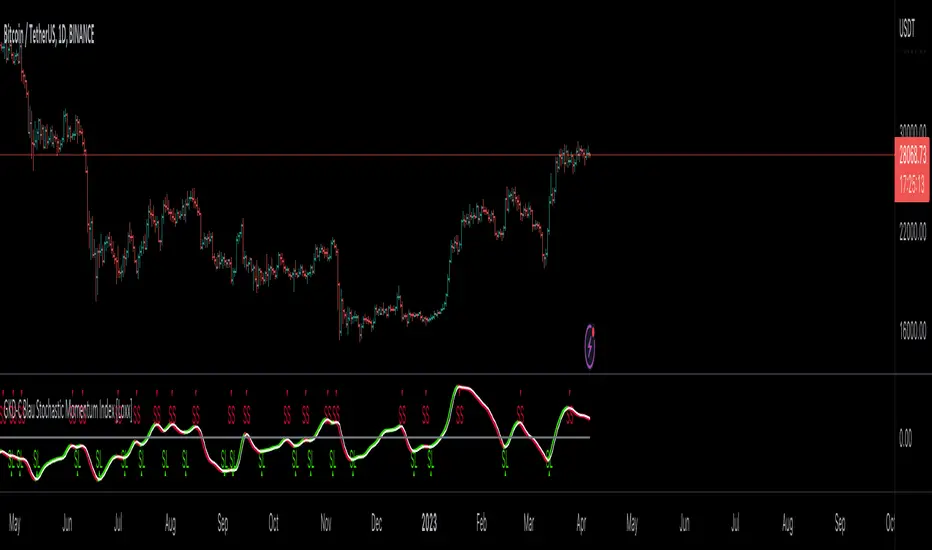
GKD-C Blau Stochastic Momentum [Loxx]Giga Kaleidoscope GKD-C Blau Stochastic Momentum is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Stochastic Momentum as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Stochastic Momentum
What is Blau Stochastic Momentum?
Blau Stochastic Momentum (BSM) is a technical analysis indicator used to measure the momentum of a financial market. It was developed by William Blau, a well-known trader and author of several books on technical analysis.
The BSM indicator is based on the Stochastic Momentum Index (SMI), which is a popular momentum indicator that measures the distance between the current closing price and the recent high or low. The SMI is similar to the Stochastic Oscillator, but it takes into account the rate of change in the market, making it more responsive to short-term changes in momentum.
The BSM indicator is designed to provide a more accurate and responsive measure of momentum than the SMI. It uses a digital signal processing technique called "smoothed moving averages" to filter out noise and provide a smoother, more stable indicator. This technique helps to reduce false signals and provide a clearer picture of market momentum.
The BSM indicator is plotted on a chart as a line that oscillates between -100 and +100. Values above zero indicate bullish momentum, while values below zero indicate bearish momentum. The BSM line is typically plotted alongside the price chart to help traders identify potential turning points in the market.
Traders can use the BSM indicator in a variety of ways, including:
1. Identifying overbought and oversold conditions: When the BSM line reaches extreme values (e.g., above +80 or below -80), it may indicate that the market is overbought or oversold and due for a reversal.
2. Confirming trend strength: When the BSM line is trending in the same direction as the price, it can confirm the strength of the trend and help traders stay in winning positions.
3. Identifying divergences: When the BSM line and the price chart are moving in opposite directions, it may indicate a potential trend reversal or weakening of the current trend.
As with any technical indicator, it is important to use the BSM in conjunction with other forms of analysis and risk management strategies. No single indicator can predict market movements with 100% accuracy, and traders should always use caution and discipline when making trading decisions.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.

GKD-C Blau Stochastic SM-Oscillator [Loxx]Giga Kaleidoscope GKD-C Blau Stochastic SM-Oscillator is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Stochastic SM-Oscillator as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Stochastic SM-Oscillator
What is Blau Stochastic SM-Oscillator?
The Blau Stochastic SM-Oscillator is a technical indicator that combines the Stochastic Oscillator and the Stochastic Momentum Index (SMI) to provide a more accurate and responsive measure of momentum in financial markets. It is designed to identify potential turning points in price trends and help traders make more informed decisions about when to enter or exit a position.
The Stochastic Oscillator is a popular momentum indicator that measures the level of buying or selling pressure in the market. It compares the current closing price to the range of prices over a given period of time to determine whether the market is overbought or oversold. The Stochastic Momentum Index (SMI), on the other hand, takes into account the recent rate of change in the market and is designed to be more responsive to changes in momentum.
The Blau Stochastic SM-Oscillator calculates the difference between the Stochastic Oscillator and the SMI to create a more sensitive indicator that is able to capture short-term changes in momentum. It is plotted as a line that oscillates between -100 and +100, with values above zero indicating bullish momentum and values below zero indicating bearish momentum. The indicator also includes a signal line, which is a moving average of the Blau Stochastic SM-Oscillator, that is used to generate trading signals.
Traders use the Blau Stochastic SM-Oscillator in a variety of ways, including identifying potential entry and exit points, confirming trends, and identifying overbought and oversold conditions in the market. It is important to note, however, that no indicator is foolproof and traders should always use multiple indicators and other forms of analysis to make informed trading decisions.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
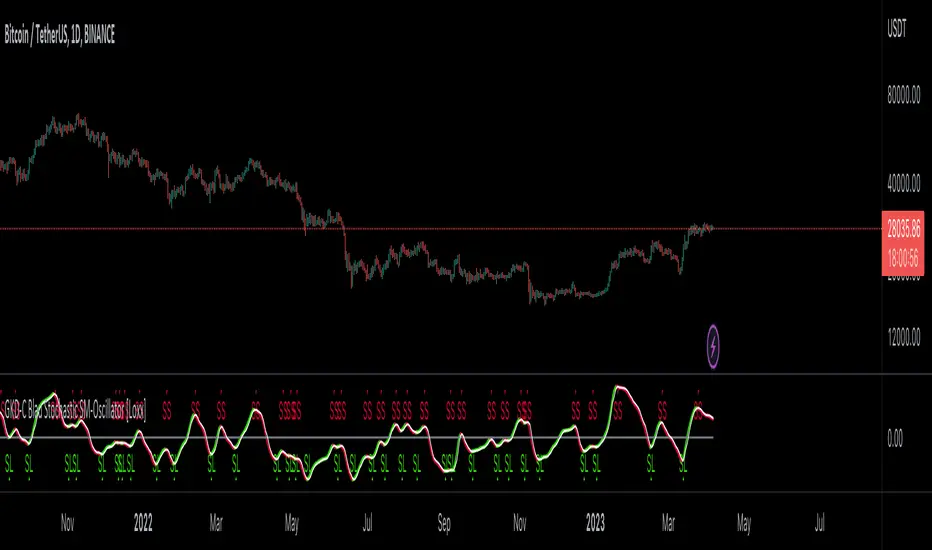
GKD-C Blau Momentum [Loxx]Giga Kaleidoscope GKD-C Blau Momentum is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Momentum as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Momentum
What is Blau Momentum?
The Blau Momentum Indicator is a technical analysis tool that is used to analyze the momentum of a financial instrument, such as a stock or a currency. Developed by William Blau, the indicator is designed to provide a more accurate and timely picture of market momentum than traditional momentum indicators.
The Blau Momentum Indicator is based on the concept of "smoothed momentum," which is the idea that momentum can be more accurately analyzed by smoothing out the data and reducing noise. The indicator is designed to be highly responsive to changes in market conditions, while also providing a more accurate picture of underlying momentum.
The Blau Momentum Indicator is calculated using a complex formula that takes into account the price and volume data of a financial instrument. The formula is designed to provide a smoothed measure of momentum that is less susceptible to short-term fluctuations and noise.
The indicator is plotted as a line graph, with values ranging from -100 to +100. A value of 0 indicates that the momentum is neutral, while a positive value indicates upward momentum and a negative value indicates downward momentum.
Traders can use the Blau Momentum Indicator in a number of ways. For example, the indicator can be used to confirm the direction of a trend, or to identify potential trend reversals. It can also be used in conjunction with other technical indicators, such as moving averages or oscillators, to provide a more complete picture of market conditions.
Overall, the Blau Momentum Indicator is a powerful tool for analyzing market momentum. While it may require some knowledge of technical analysis to use effectively, the indicator can provide valuable insights into market conditions and help traders make informed trading decisions.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.

GKD-C Blau Composite High-Low Momentum [Loxx]Giga Kaleidoscope GKD-C Blau Composite High-Low Momentum is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Blau Composite High-Low Momentum as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Blau Composite High-Low Momentum
What is the Blau Composite High-Low Momentum?
The Composite High/Low Momentum (HLM) Blau HLM is a technical analysis tool that is used to analyze the momentum of a financial instrument. Developed by William Blau, the HLM is a unique indicator that combines both price and volume data to provide a comprehensive picture of market trends and momentum.
The HLM is based on the concept of price momentum, which is the tendency of a financial instrument to continue moving in the same direction that it has been moving. Momentum is a key indicator for traders, as it can help to identify trends and potential changes in trend.
The HLM is calculated by comparing the current price of a financial instrument to its highest and lowest prices over a specified period of time. This calculation is then combined with a measure of volume, which is used to provide additional insight into market trends and momentum.
The HLM is designed to be highly responsive to changes in market conditions, providing traders with a more accurate and timely picture of market trends. The indicator is also highly customizable, allowing traders to adjust the parameters to suit their individual trading styles and preferences.
One of the key benefits of the HLM is its ability to provide early warning signs of potential trend changes. By analyzing both price and volume data, the HLM is able to identify shifts in market momentum that may indicate a potential reversal in trend.
Overall, the Composite High/Low Momentum Blau HLM is a powerful technical analysis tool that can provide traders with valuable insights into market trends and momentum. While it may require some knowledge of technical analysis to use effectively, the HLM can be a valuable tool for traders looking to make informed trading decisions.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.

GKD-V William Blau Ergodic Tick Volume (TVI) [Loxx]Giga Kaleidoscope GKD-V William Blau Ergodic Tick Volume (TVI) is a Volatility / Volume module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines , channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility . There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility ; e.g., Average True Range , True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility / Volume - a technical indicator used to identify volatility / volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR ( Average True Range ) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility . As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double ( TRD ), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index ( RSI ), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index ( RSI ).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands , the MACD (Moving Average Convergence Divergence), and the Stochastic Oscillator. These indicators can provide information about the volatility , momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility / Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow ( CMF ), or the Volume Price Trend ( VPT ), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index . Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index ( RSI ), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR , the Average Directional Index ( ADX ), and the Chandelier Exit .
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module ( Volatility , Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility / Volume , Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility / Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility / Volume . The Volatility / Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility , and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: William Blau Ergodic Tick Volume (TVI) as shown on the chart above
Confirmation 1: Vortex
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility / Volume Agrees
█ GKD-C William Blau Ergodic Tick Volume (TVI)
What is William Blau Ergodic Tick Volume (TVI)?
The William Blau Ergodic Tick Volume Indicator (TVI) is a technical analysis tool used to analyze the volume of a financial instrument, such as a stock or a currency. The TVI is designed to capture the direction and strength of a trend, as well as to identify changes in trend.
The TVI is based on the concept of "ergodicity," which is the idea that a process or system will eventually return to a state of equilibrium or balance. In the case of the TVI, the ergodicity principle is applied to tick volume, which is the number of price movements (ticks) that occur within a given period of time.
The TVI is calculated by first determining the direction of the trend, which is done by comparing the current price to the previous price. If the current price is higher than the previous price, the trend is considered to be up, and if the current price is lower than the previous price, the trend is considered to be down.
Next, the TVI is calculated using a complex formula that takes into account the tick volume and the direction of the trend. The formula is designed to smooth out the volume data, reducing noise and providing a more accurate picture of the underlying trend.
The TVI can be used in a number of ways. Traders may use it to confirm the direction of a trend, or to identify potential trend reversals. It can also be used in conjunction with other technical indicators, such as moving averages or oscillators, to provide a more complete picture of market conditions.
Overall, the William Blau Ergodic Tick Volume Indicator is a powerful tool for analyzing volume trends in financial markets. While it may require some knowledge of technical analysis to use effectively, it can provide valuable insights into market conditions and help traders make informed trading decisions.
Requirements
Inputs
Chained: GKD-B Baseline
Solo: NA, no inputs
Baseline + Volatility/Volume: GKD-B Baseline
Outputs
Chained: GKD-C indicators Confirmation 1 or Solo Confirmation Complex
Solo: GKD-BT Backtest
Baseline + Volatility/Volume: GKD-BT Backtest
Additional features will be added in future releases.

GKD-C Inertia [Loxx]Giga Kaleidoscope GKD-C Inertia is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Inertia as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Inertia
What is the Relative Vigor Index?
The Relative Vigor Index (RVI) is a technical analysis indicator used to measure the strength of a trend in financial markets. It was developed by John Ehlers and first introduced in his book "Cybernetic Analysis for Stocks and Futures" in 2004.
The RVI indicator is based on the concept that the strength of a trend can be measured by comparing the closing price of an asset to its opening price, and then smoothing out the resulting data with an exponential moving average (EMA). The indicator is calculated using the following steps:
Calculate the difference between the closing price and the opening price for a given period.
Calculate the high-low range for the same period.
Divide the difference in step 1 by the high-low range in step 2.
Calculate an EMA of the result obtained in step 3, usually using a period of 10.
The resulting RVI value oscillates around a centerline of 0. If the RVI value is positive, it indicates that the closing price is higher than the opening price and that the bullish momentum is increasing. If the RVI value is negative, it indicates that the closing price is lower than the opening price and that the bearish momentum is increasing.
Traders use the RVI indicator to identify changes in the momentum of a trend. When the RVI crosses above the centerline, it indicates that bullish momentum is increasing, and traders may look for opportunities to buy the asset. Conversely, when the RVI crosses below the centerline, it indicates that bearish momentum is increasing, and traders may look for opportunities to sell the asset.
It is important to note that the RVI is not a standalone indicator, and traders usually use it in conjunction with other technical analysis tools to confirm signals and make trading decisions.
What is The Least Squares Moving Average (LSMA)
The Least Squares Moving Average (LSMA) is a technical analysis indicator used to identify trends and momentum in financial markets. It is based on the concept of linear regression analysis, which is a statistical method used to estimate the relationship between two variables.
The LSMA indicator is calculated by fitting a linear regression line to the closing prices over a specified period of time. The slope of the regression line represents the trend, and the intercept represents the moving average. The LSMA indicator is a moving average of the regression line's intercept, and it is designed to be more responsive to changes in price than traditional moving averages.
The LSMA indicator is calculated using the following steps:
Determine the length of the moving average. This is the number of periods that will be used to calculate the LSMA.
Calculate the slope and intercept of the linear regression line for the closing prices over the specified period of time.
Calculate the LSMA using the intercept of the regression line and the length of the moving average.
Traders use the LSMA indicator to identify trends and momentum in financial markets. When the LSMA is moving upward, it indicates an uptrend, and traders may look for opportunities to buy the asset. Conversely, when the LSMA is moving downward, it indicates a downtrend, and traders may look for opportunities to sell the asset.
It is important to note that the LSMA is not a standalone indicator, and traders usually use it in conjunction with other technical analysis tools to confirm signals and make trading decisions. Additionally, the LSMA indicator can be subject to false signals during periods of market volatility, so traders should use caution when interpreting its signals.
What is Inertia?
Inertia applies Jurik Smoothing halfway through the calculation process to filter out noise thereby producing a cleaner output signal.
What is Inertia?
This indicator is the LSMA of RVI. This is one of various types of inertia used primarily in Forex trading but can be used for any time series financial data.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
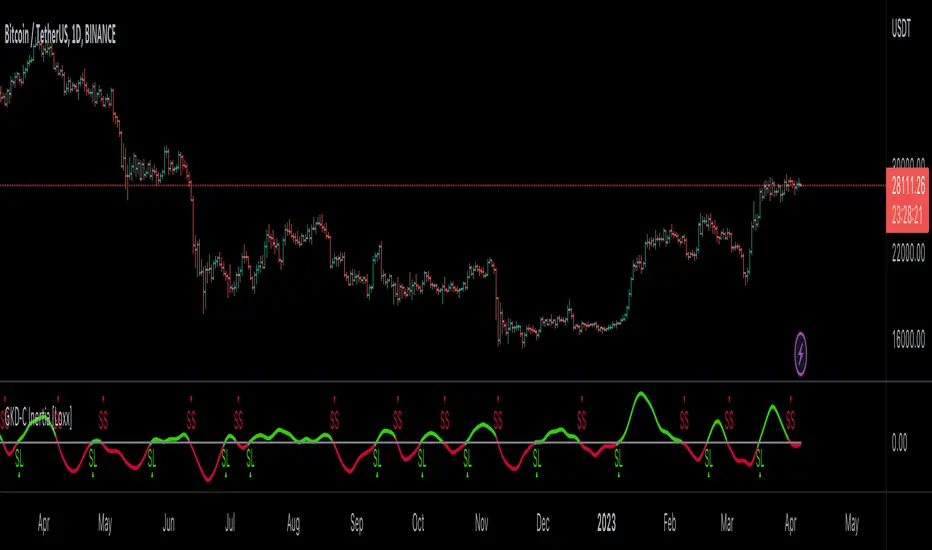
GKD-C Trend Scalp [Loxx]Giga Kaleidoscope GKD-C Trend Scalp is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Trend Scalp as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Trend Scalp
What is T3?
The T3 Moving Average (T3MA) is a technical analysis indicator that was developed by Tim Tillson. It is a trend-following indicator that aims to provide a smoother and more accurate representation of price trends than other moving average indicators.
The T3MA is a type of exponential moving average ( EMA ) that is calculated using a series of complex formulas. Unlike a simple or exponential moving average , which use fixed smoothing factors, the T3MA uses a variable smoothing factor that is based on the volatility of the underlying asset. This means that the T3MA is able to adapt to changing market conditions and provide more accurate signals.
The formula for calculating the T3MA is as follows:
T3 = a * EMA1 + (1 - a) * T3
Where:
-T3 is the current value of the T3MA
-EMA1 is the current value of the first EMA
-T3 is the previous value of the T3MA
-a is the smoothing factor, which is based on the volatility of the underlying asset and is calculated using the following formulas:
-c1 = -1 + exp (-sqrt(2) * pi / period)
-c2 = 2 * c1 * c1 + 2 * c1
-c3 = 1 - c1 - c2
-a = c1 * sqrt(period) * (close - T3) + c2 * T3 + c3 * EMA1
In simple terms, the T3MA is calculated by taking a weighted average of two different EMAs, with the weight given to each EMA depending on the volatility of the asset being analyzed. The T3MA is then smoothed using a second smoothing factor, which further reduces noise and improves the accuracy of the indicator.
The T3MA can be used in a variety of ways by traders and analysts. Some common applications include using the T3MA as a trend-following indicator, with buy signals generated when the price of an asset crosses above the T3MA and sell signals generated when the price crosses below. The T3MA can also be used in combination with other indicators and analytical techniques to confirm trading decisions and identify potential trend reversals.
Overall, the T3 Moving Average is a highly sophisticated and complex technical indicator that is designed to provide a more accurate and reliable representation of price trends. While it may be difficult for novice traders to understand and use effectively, experienced traders and analysts may find the T3MA to be a valuable tool in their trading toolbox.
What is Trend Scalp?
Trend Scalp calculates the difference between bull and bear power and then smooths this calculation using the T3 filter. This indicator is good for lower timeframe scalping. For use in regular trading, decrease the levels value, for scalps, keep the levels value high.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
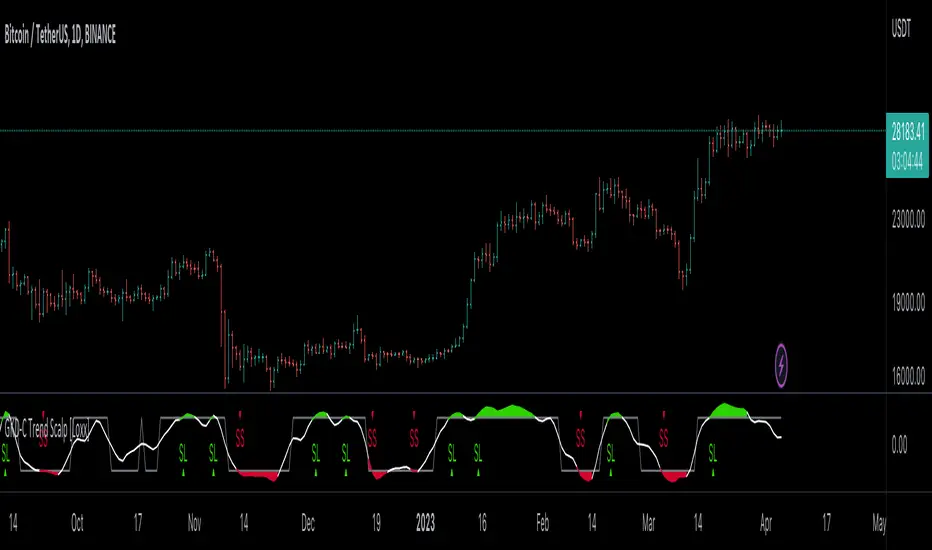
GKD-C GKYZ-Filtered, Non-Linear Regression MA [Loxx]Giga Kaleidoscope GKD-C GKYZ-Filtered, Non-Linear Regression MA is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: GKYZ-Filtered, Non-Linear Regression MA as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C GKYZ-Filtered, Non-Linear Regression MA
What is Non-Linear Regression Moving Average?
Non-linear regression is a statistical method used to model non-linear relationships between independent and dependent variables. In contrast to linear regression, which assumes a linear relationship between the variables, non-linear regression allows for more complex relationships to be modeled.
Moving average is a time series analysis technique used to smooth out short-term fluctuations in data and highlight longer-term trends or cycles. It works by calculating the average of a subset of data points over a specified window or period of time, and then shifting the window forward one time step and recalculating the average.
Non-linear regression moving average combines these two techniques to model non-linear relationships in time series data. The approach involves fitting a non-linear regression model to the data and then applying a moving average filter to the residuals, which are the differences between the actual data values and the predicted values from the model. The moving average filter smooths out any remaining short-term fluctuations in the residuals, allowing the underlying long-term trends to be more clearly observed.
The choice of window or period for the moving average filter can affect the results of non-linear regression moving average, with larger windows resulting in smoother trends but potentially obscuring important short-term fluctuations. The approach is commonly used in financial analysis, economics, and other fields where time series data are frequently encountered.
What is Garman-Klass-Yang-Zhang Historical Volatility?
Garman-Klass-Yang-Zhang (GKYZ) Historical Volatility is a method of calculating volatility in financial markets. It is a modification of the standard historical volatility calculation that incorporates intraday price data and takes into account the volatility clustering phenomenon often observed in financial time series.
The GKYZ formula calculates volatility as the square root of the sum of squared returns over a given time period. Specifically, it incorporates four components: opening price, closing price, high price, and low price. The formula is as follows:
GKYZ Historical Volatility = (Σ |ln(P_t / P_(t-1))|^2 / (4*N))^(1/2)
where:
P_t is the closing price at time t
P_(t-1) is the closing price at time t-1
N is the number of intraday periods in the time period of interest (e.g. number of minutes in a day)
The formula takes the natural logarithm of the ratio of closing prices to calculate the log return. The absolute value of the log return is squared and summed over the number of intraday periods in the time period of interest. This sum is divided by 4 times N and then square rooted to obtain the GKYZ Historical Volatility.
The GKYZ formula is designed to be more robust than the standard historical volatility calculation, as it incorporates intraday price data and adjusts for volatility clustering. Volatility clustering is the phenomenon where periods of high volatility tend to be followed by periods of high volatility, and periods of low volatility tend to be followed by periods of low volatility. The GKYZ formula accounts for this by incorporating intraday data, which can capture volatility fluctuations more accurately than daily data.
The GKYZ Historical Volatility is commonly used in options pricing models and risk management, as it provides a more accurate measure of volatility than the standard historical volatility calculation.
What is GKYZ-Filtered, Non-Linear Regression MA?
This indicator combines a Non-Linear Regression Moving Average with Garman-Klass-Yang-Zhang Historical Volatility through a stepping formula that requires price and/or the Non-Linear Regression Moving Average to have moved by XX multiple of Garman-Klass-Yang-Zhang Historical Volatility before registering a trend flip. The output moving average drawn to the chart is also adjusted to this filtering mechanism. You can choose to filter by price, Non-Linear Regression Moving Average, or both.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.

GKD-C Trendilo [Loxx]Giga Kaleidoscope GKD-C Trendilo is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Trendilo as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Trendilo
What is the ALMA?
The Arnaud Legoux Moving Average (ALMA) is a moving average variant created by Arnaud Legoux in 2009 with the goal of decreasing the lag commonly encountered with moving averages. It is designed to use a Gaussian distribution that is shifted with a calculated offset in order for the average to be biased towards more recent days, instead of being more evenly centered on the window. The ALMA indicator aims to detect trends and trend reversals and can be used similarly to other moving averages
What is the Double Smoothed Stochastic Oscillator (DSS)
Trendilo calculates the percentage change of the source data and applies an Arnaud Legoux Moving Average (ALMA) to it. The result is plotted along with positive and negative root mean square (RMS) valuesth reliable signals that confirm the strength of a trend or indicate a possible trend reversal.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
GKD-C Double-Smoothed Stochastic QQE [Loxx]Giga Kaleidoscope GKD-C Double-Smoothed Stochastic QQE is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Double-Smoothed Stochastic QQE as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ GKD-C Double-Smoothed Stochastic QQE
What is the Double Smoothed Stochastic Oscillator (DSS)
The Double Smoothed Stochastic Oscillator (DSS) is a technical indicator used in financial analysis to measure the momentum of a security's price. It is an enhanced version of the traditional Stochastic Oscillator that reduces false signals and lag.
The traditional Stochastic Oscillator measures the position of a security's closing price relative to its price range over a specified period, usually 14 days. It calculates two lines, %K and %D, which oscillate between 0 and 100. When %K crosses above %D, it is considered a buy signal, and when %K crosses below %D, it is considered a sell signal.
The Double Smoothed Stochastic Oscillator adds an additional level of smoothing to the traditional Stochastic Oscillator by calculating two additional lines, DSS %K and DSS %D, using a double exponential moving average (DEMA) formula. The DEMA formula is a weighted moving average that gives more weight to recent data points than older data points.
The DSS %K line is calculated by taking a 3-period DEMA of the traditional Stochastic %K line, and the DSS %D line is calculated by taking a 3-period DEMA of the DSS %K line. The result is a smoother oscillator that responds more quickly to changes in price momentum.
Traders use the DSS to identify overbought and oversold conditions, as well as trend reversals. An overbought condition occurs when the oscillator is above 80, and an oversold condition occurs when the oscillator is below 20. Traders look for buy signals when the oscillator crosses above 20 from oversold conditions, and sell signals when the oscillator crosses below 80 from overbought conditions.
In summary, the Double Smoothed Stochastic Oscillator is an enhanced version of the traditional Stochastic Oscillator that reduces false signals and lag by adding an additional level of smoothing through the use of a double exponential moving average formula. It is used by traders to identify overbought and oversold conditions and trend reversals.
What is QQE?
Quantitative Qualitative Estimation (QQE) is a technical analysis indicator used to identify trends and trading opportunities in financial markets. It is based on a combination of two popular technical analysis indicators - the Relative Strength Index (RSI) and Moving Averages (MA).
The QQE indicator uses a smoothed RSI to determine the trend direction, and a moving average of the smoothed RSI to identify potential trend changes. The indicator then plots a series of bands above and below the moving average to indicate overbought and oversold conditions in the market.
The QQE indicator is designed to provide traders with a reliable signal that confirms the strength of a trend or indicates a possible trend reversal. It is particularly useful for traders who are looking to trade in markets that are trending strongly, but also want to identify when a trend is losing momentum or reversing.
Traders can use QQE in a number of different ways, including as a confirmation tool for other indicators or as a standalone indicator. For example, when used in conjunction with other technical analysis tools like support and resistance levels, the QQE indicator can help traders identify key entry and exit points for their trades.
One of the main advantages of the QQE indicator is that it is designed to be more reliable than other indicators that can generate false signals. By smoothing out the price action, the QQE indicator can provide traders with more accurate and reliable signals, which can help them make more profitable trading decisions.
In conclusion, QQE is a popular technical analysis indicator that traders use to identify trends and trading opportunities in financial markets. It combines the RSI and moving average indicators and is designed to provide traders with reliable signals that confirm the strength of a trend or indicate a possible trend reversal.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation Complex: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest strategy
Additional features will be added in future releases.
